В прошлый раз мы говорили про особенности работы с базовыми CRUD-операциями в Hive. Сегодня поговорим про основные join-операции в распределенной Big Data платформе Apache Hive. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про особенности работы с join-операциями в распределенной СУБД Apache Hive.
Join-операции в СУБД Apache Hive
Стоит отметить, что Hive — это распределенная система управления базами данных (СУБД), которая дает возможность проектировать структуры Big Data (таблицы, партиции, бакеты) с помощью SQL-диалекта HiveQL (Hive Query Language). Часто возникают случаи, когда необходимо объединить данные нескольких таблиц в Hive. Для этого применяются join-операции. Join-операции в Hive — это набор функций для соединения (join) данных нескольких таблиц в одно целое. Результатом соединения служит новая таблица, содержащая данные всех исходных таблиц, участвующих в соединении. Существуют следующие виды соединений таблиц в Hive:
- inner join — внутреннее соединение (или полное соединение) двух и более таблиц, результатом которого будет таблица, содержащая все данные, участвующие в соединении;
- left outer join — левое внешнее соединение таблиц, результатом которого будут являться все строки из «левой» таблицы (название которой стоит перед оператором
LEFT OUTER JOIN) и те строки из «правой» (название которой стоит после оператораLEFT OUTER JOIN) таблицы, которые совпадают по ключам соединения (поля, значения которых должны быть по условию равны при соединении) с «левой» таблицей. Все несовпадающие значения именуются в NULL. - left outer join — правое внешнее соединение таблиц, результатом которого будут являться все строки из «правой» таблицы (название которой стоит после оператора
RIGHT OUTER JOIN) и те строки из «левой» (название которой стоит перед операторомRIGHT OUTER JOIN) таблицы, которые совпадают по ключам соединения (поля, значения которых должны быть по условию равны при соединении) с «правой» таблицей. Все несовпадающие значения именуются в NULL; - full outer join — это операция полного внешнего соединения, которая объединяет записи левой и правой таблиц по указанному условию. Результатом этой операции служит новая таблица с совпадающими записями из таблиц либо со значениями NULL для всех несовпадающих записей.
Работа с JOIN-операциями в Hive: несколько практических примеров
В качестве примера соединения таблиц можно рассмотреть исходные таблицы CUSTOMERS (клиенты) и ORDERS (заказы).
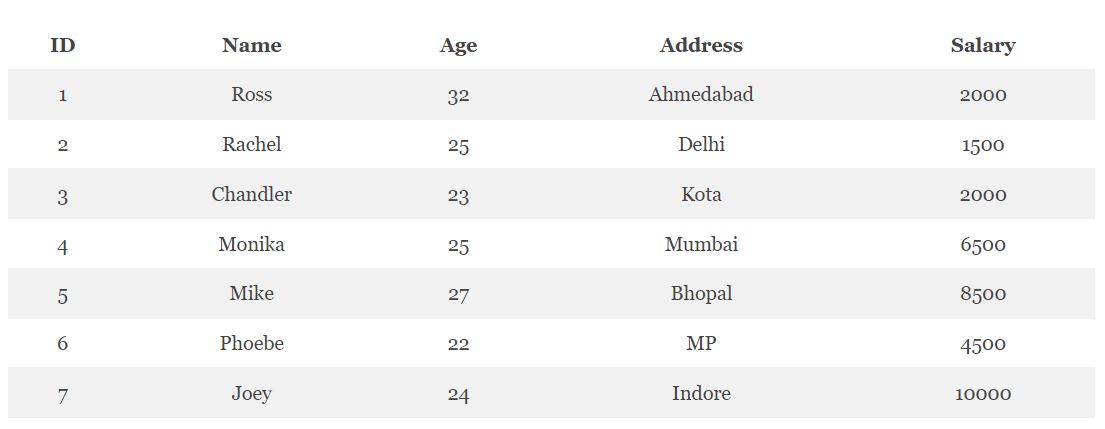
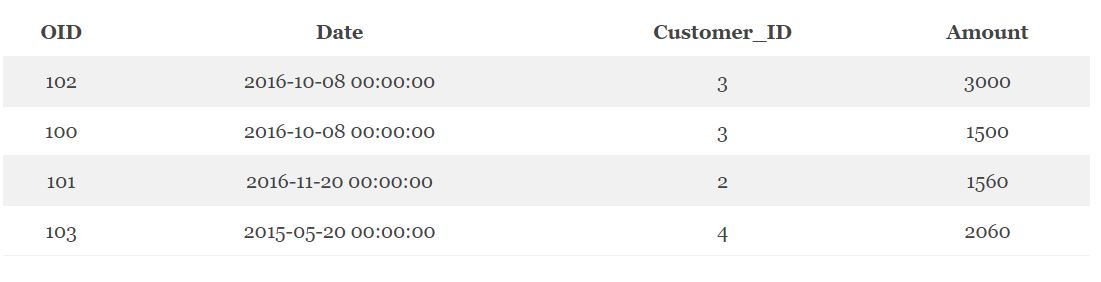
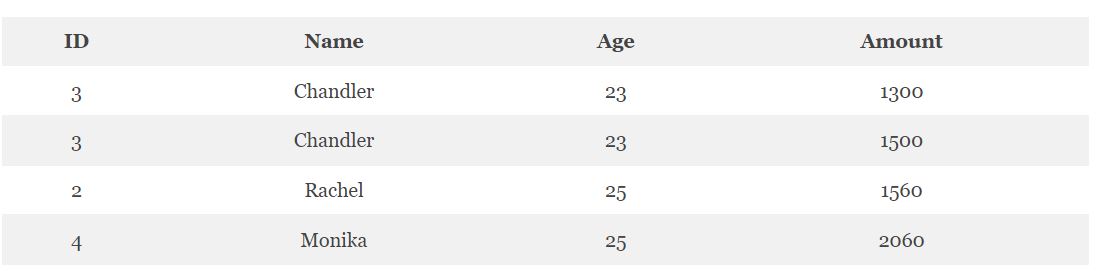
Для внутреннего соединения таблиц в Hive используется оператор INNER JOIN или просто JOIN. Следующий код на языке HiveQL отвечает за вывод клиентов и количество их заказов [1]:
SELECT c.ID, c.NAME, c.AGE, o.AMOUNT FROM CUSTOMERS c JOIN ORDERS o ON (c.ID = o.CUSTOMER_ID);
Для того, чтобы сделать левое внешнее соединение в Hive, используется SQL-команда LEFT OUTER JOIN. В качестве примера можно рассмотреть вывод результатов с именами клиентов, а также количеством их заказов и временем заказа [1]:
SELECT c.ID, c.NAME, o.AMOUNT, o.DATE FROM CUSTOMERS c LEFT OUTER JOIN ORDERS o ON (c.ID = o.CUSTOMER_ID);
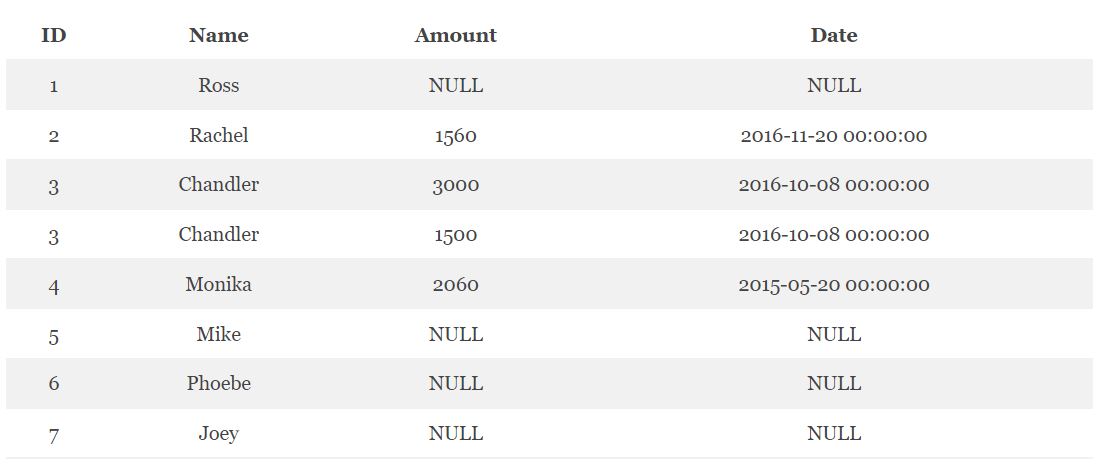
Как видно из результата, записи правой таблицы, которые по условию (за условие соединения таблиц отвечает оператор ON) не совпадают с записями из правой, превратились в NULL-значения.
Для правого внешнего соединения в Hive служит оператор RIGHT OUTER JOIN. Можно повторить вышеприведенный пример, но уже с правым внешним соединением [1]:
SELECT c.ID, c.NAME, o.AMOUNT, o.DATE FROM CUSTOMERS c RIGHT OUTER JOIN ORDERS o ON (c.ID = o.CUSTOMER_ID);

Как видно из результата, в отличие от предыдущего примера, при условии данного соединения абсолютно все строки левой таблицы соответствуют всем строкам правой таблицы и поэтому NULL-значений не наблюдается.
Для того, чтобы выполнить полное внешнее соединения в Hive есть специальная SQL-команда FULL OUTER JOIN. В качестве примера можно повторить решить предыдущую задачу с использованием полного внешнего соединения [1]:
SELECT c.ID, c.NAME, o.AMOUNT, o.DATE FROM CUSTOMERS c FULL OUTER JOIN ORDERS o ON (c.ID = o.CUSTOMER_ID);
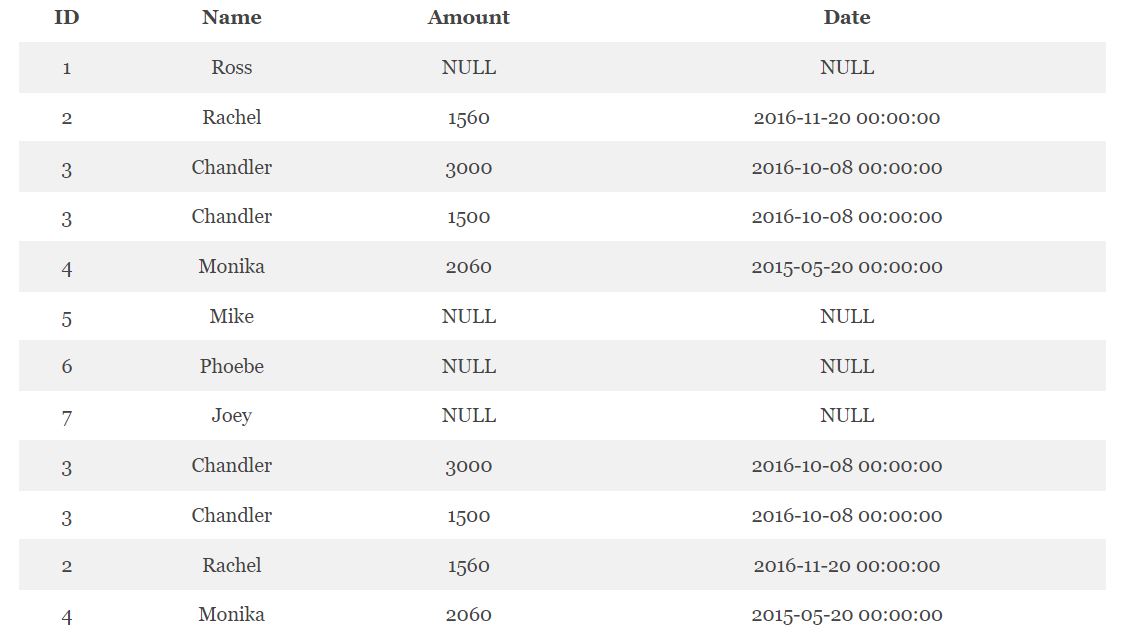
При полном внешнем соединении в обеих таблицах есть несовпадающие друг с другом значения, что противоречит указанному в коде условию, поэтому эти значения обратились в NULL.
Таким образом, благодаря join-операциям, Hive освобождает разработчика от создания и копирования дополнительных таблиц Big Data, что исключает возможность переполнения и замедления вычислительного кластера. Это делает Apache Hive весьма удобным средством для работы с Big Data.
Больше подробностей про применение Apache Hive в проектах анализа больших данных вы узнаете на практических курсах по NoSQL в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
MPA: CLOUDERA IMPALA DATA ANALYTICS
ADQM: ЭКСПЛУАТАЦИЯ ARENADATA QUICKMARTS
ADBR: Arenadata DB для разработчиков
ADB: Эксплуатация Arenadata DB
HBASE: Администрирование кластера HBase
HIVE: Hadoop SQL администратор Hive
NoSQL: Интеграция Hadoop и NoSQL
Источники

