Недавно мы говорили про трудности наблюдаемости данных вообще и возможности мониторинга их происхождения в Apache Spark. Сегодня рассмотрим, зачем дата-инженеру прерывать DAG lineage в Spark-приложениях и как это сделать.
Что такое DAG lineage и зачем его прерывать?
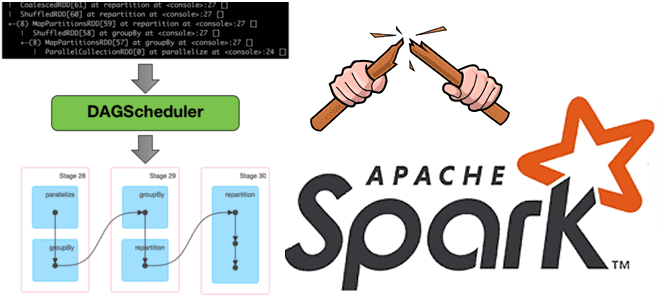
Напомним, Apache Spark использует концепция DAG для выполнения распределенных вычислений. Направленный ациклический граф в Spark визуализирует, как будет выполняться задание. Вершинами этого графа являются низкоуровневые структуры данных Spark – RDD, Распределенные отказоустойчивые коллекции данных, которые соединяются ребрами DAG-графа, отображающими операции над этими RDD. Визуальное представление DAG можно посмотреть в веб-GUI фреймворка, в разделе задания.
При вызове какого-либо действия Spark, планировщик на входе принимает DAG-граф, на выходе создавая этапы и задачи. Иногда DAG созданное количество этапов и задач настолько велики, что не помещаются в память. Это приводит к ошибкам java.lang.StackOverflowError или java.lang.OutOfMemoryError. Поэтому возникает потребность разорвать DAG lineage. Сделать это можно через контрольные точки или пересоздание датасета/датафрейма. У каждого способа есть свои достоинства и недостатки. Выбор варианта зависит от условий среды развертывания, например, кластера, где выполняются задания Spark. Чтобы понять, как это работает, рассмотрим каждый из способов более подробно, но сперва проясним разницу между DAG и графом происхождения данных (Lineage graph).
Когда в RDD выполняется ряд преобразований, они выполняются не сразу, а являются отложенными вычислениями (lazy evaluation). Когда новый RDD создается из существующего RDD, новый RDD содержит указатель на родительский. Все зависимости между RDD регистрируются в графе, а не в фактических данных. Этот граф и называется lineage graph.
Контрольные точки в Apache Spark
При выполнении заданий в кластере Hadoop датафрейм сохраняется в HDFS во время контрольной точки. Это обеспечивает отказоустойчивость, если исполнитель будет завершен во время обработки: данные будут взяты из HDFS другим исполнителем. Рекомендуется уменьшить количество shuffle-разделов перед контрольной точкой, поскольку их большое количество приведет к появлению большого количества небольших файлов в HDFS. Это замедлит работу контрольной точки, поскольку узел имен (NameNode) является узким местом кластера.
Контрольные точки можно использовать для усечения логического плана нового набора данных, что особенно полезно в итеративных алгоритмах, где план выполнения запроса может расти экспоненциально. Он будет сохранен в файлах внутри каталога контрольных точек, установленного с помощью конфигурации SparkContext#setCheckpointDir.
Если кластер, где выполняются задания Spark, имеет медленную сеть, лучше выбрать способ локальной контрольной точки (LocalCheckpoint). В этом случае данные не передаются в HDFS, а сохраняются в локальной файловой системе исполнителя. Но, если исполнитель откажет во время обработки, данные будут потеряны, и Spark не гарантирует восстановление этого датафрейма из DAG. Локальные контрольные точки записываются в хранилище исполнителя, и, несмотря на более высокую скорость выполнения, они ненадежны и могут поставить под угрозу завершение задания.
Пересоздание данных
Вместо медленных или ненадежных контрольных точек можно просто создать новый датафрейм данных или датасет на основе текущего. Так можно разорвать DAG lineage, без передачи данных по сети и нагрузки HDFS с NameNode. API разработчика Spark позволяет создать датафрейм из RDD, содержащий строки, используя заданную схему. При этом важно убедиться, что структура каждой строки этого RDD соответствует предоставленной схеме. Иначе возникнет исключение во время выполнения. Также можно использовать энкодер – публичный интерфейс, который используется для преобразования объекта JVM во внутреннее представление Spark SQL и обратно. Он поможет создать набор данных из RDD заданного типа.
Узнайте больше практических деталей по применению Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

