
В этой статье разберем ключевые характеристики идеального конвейера обработки больших данных. Читайте далее, чем отличается Big Data Pipeline, а также какие приемы и технологии помогут инженеру данных спроектировать и реализовать его наиболее эффективным образом. В качестве практического примера рассмотрим кейс британской компании кибербезопасности Panaseer, которой удалось в 10 раз сократить цикл разработки и тестирования ETL-конвейеров на компонентах экосистемы Apache Hadoop: Hive, HBase и Spark.
На чем стоит инженерия больших данных: 5 принципов проектирования конвейеров
Современный Data Engineering – это гораздо больше, чем просто перемещения данных из одного места в другое или операции ETL (Extract-Transform-Load). Инженерия больших данных включает их моделирование, интеграция, конфигурирование СУБД, файловых и других хранилищ, проектирование и реализацию DWH, ETL-конвейеры, внедрение идей CI/CD для данных и прочие DataOps-практики.
Из всего этого многообразия преобразование и перенос данных является одной из основных обязанностей дата-инженера. Конвейеры обработки данных обеспечивают их доступность. Однако, чтобы такой pipeline был по-настоящему эффективным, автоматизируя процессы обработки Big Data, он должен обладать следующими качествами [1]:
- Воспроизводимость – возможность корректного рестарта с любого согласованного момента времени для повторной загрузки данных в случае сбоя, недоступности источника или других ошибок. Воспроизводимость обеспечивает детерминированность конвейера данных на основе принципов их неизменности и идемпотентности, независимо от потокового (real-time) или пакетного (batch) режима обработки.
- Отслеживаемость, которая позволяет дата-инженеру в любой момент времени знать, какое задание выполняется или запускается, а также что не удалось сделать и почему, чтобы быстро устранить проблему в конвейере. В общем смысле отслеживаемость или контролируемость конвейера данных позволяет Data Engineer’у наблюдать историю событий в наглядном и понятном виде.
- Масштабируемость, поскольку со временем данных становится только больше. При проектировании data pipeline’ов следует помнить об этой особенности и выбирать масштабируемые инструменты, такие как, например, Apache Kafka, NiFi, AirFlow, Spark, Hadoop и прочие открытые технологии Big Data.
- Надежность, что относится как к технологиям обеспечения конвейера данных, о которых мы сказали выше, так и к самим данным. Последнее входит в область обеспечения качества данных (Data Quality), повысить которое помогут такие DataOps-практики, как автоматизированное тестирование источников, приемников и элементов самого конвейера данных.
- Наконец, безопасность, которая включает соответствие data pipeline’а требованиям security, обеспечивая санкционированный доступ к нужным данным и операции над ними, а также предупреждая утечки.
Чтобы показать, как все эти принципы реализуются на практике, далее рассмотрим пример британской компании Panaseer Limited, которая разрабатывает программные платформы обеспечения корпоративной безопасности с использованием технологий Big Data и лучших DataOps-практик. Это ориентировано на обеспечение максимальной прозрачности всех digital-аспектов безопасности предприятия, позволяя клиентам принимать оптимальные решения, основанные на данных, и управлять рисками по [2].
Инженерный Big Data Pipeline на примере Panaseer: проблемы и решения
Big Data Pipelines в Panaseer являются ядром серверной платформы: они отвечают за прием данных из разнородных источников, их преобразование и анализ, а также сопровождение до финального этапа загрузки в СУБД, которая обслуживает корпоративного веб-клиента. Работа этого конвейера основана на Apache Hadoop: Hive, Spark и HBase. Благодаря распределенному характеру этих технологий Big Data обеспечивается эффективное разделение разделению этапов ETL-конвейера и возможности параллелизма [3]:
- данных за счет разбиения последовательного файла на файлы меньшего размера для обеспечения параллельного доступа в стиле Hadoop;
- конвейера в виде одновременного запуска сразу нескольких компонентов в одном потоке данных, например, преобразование данных в одном блоке может выполняться одновременно с извлечением их в другом блоке pipeline’а.
- компонентов как одновременный запуск сразу нескольких процессов в разных потоках данных в одном задании.
Поскольку дата-конвейеры в Panaseer работают с множеством различных источников, для сбора и преобразования данных необходимо разрабатывать и поддерживать большой объем кода Spark. Чтобы снизить сложность этого процесса, в компании был разработан собственный язык на основе JSON для управления потоками ETL как конфигурацией в соответствии с принципами DevOps. В конвейерах присутствуют общие считыватели таблиц (HiveReader) и загрузчики, а также настраиваемые преобразователи, которые можно объединять в цепочку для создания pipeline’ов произвольной длины и сложности. Такой прием реализует принцип воспроизводимости, позволяя повторно использовать большой объем нужного кода в случае запланированной или случайной остановки. В частности, можно передавать дополнительные настройки в конфигурируемый преобразователь, которые будут автоматически трансформированы в код Spark и применены к DataFrame’ам. Таким образом, скрывается сложность разработки на Spark, обеспечивая непрерывную поставку данных.
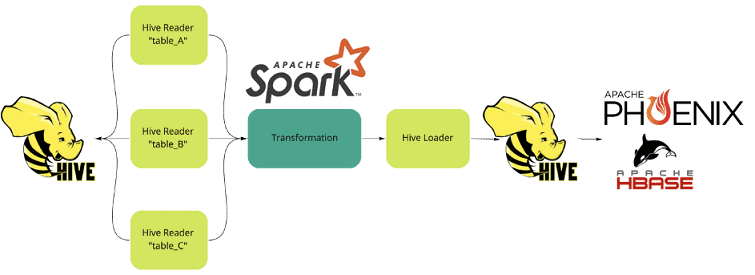
Проблемой вышеописанного pipeline’а была длительная процедура изменения его конфигурации. К примеру, если пользователь хотел протестировать это, требовалось развернуть код в среде разработки или промежуточной среде с определенным дистрибутивом Hadoop, а также вручную проделать следующие действия [3]:
- внести необходимые изменения конфигурации локально в файлы конфигурации ETL;
- синхронизировать (развернуть) репозиторий с целевой средой, без всяких гарантий, что новая конфигурация корректна;
- запустить нужное задание ETL;
- наблюдать за логами, ожидая инициализации контекста Spark;
- проверять логи на наличие ошибок;
- в случае ошибок вернуться к первому шагу для их исправления.
Таким образом, цикл настройки, развертывания и запуск конфигурации ETL-конвейера мог занимать до 15 минут, снижая общую производительность разработчиков. Кроме того, из-за зависимости от сервисов Hadoop (Hive, Zookeeper, HBase, YARN и пр.) было невозможно тестировать ETL локально от начала до конца, подключая их к рабочим процессам CI/CD.
Поэтому дата-инженеры компании Panaseer решили создать инструмент для сканирования Hive и HBase и извлечения схем для базовых таблиц. Далее эти схемы сохраняются в центральном репозитории или реестре схем (Schema Registry). При этом используются необработанные файлы в системе управления версиями, чтобы пользователь мог легко получить доступ к ним в том же месте, что и код ETL, а также копировать файлы в свою локальную среду разработки для автономного режима. Затем при запуске ETL вместо чтения из Hive используются файлы схемы данных для создания пустого датафрейма Spark, с которым выполняются соответствующие бизнес-логике преобразования. Таким образом имитируется взаимодействие с Hive с возможностью тестировать преобразования Spark и их взаимодействие с реальными датафреймами. Важно, что здесь нет тестирования данных в датафреймах, а идет проверка логических операций ETL-конвейера на то, что любые изменения конфигурации приведут к корректной выходной схеме данных.
Запуск всех необходимых сервисов Hadoop: YARN, Zookeeper, Hive и Spark возможен внутри виртуальной машины. Однако, производительность такого решения далека от оптимальной из-за больших требований к памяти и длительного времени запуска. Поэтому дата-инженеры Panaseer разработали собственный CLI-краулер, который получает схемы базовых таблиц Hive и HBase, сканируя сканирует хранилища данных и извлекая схему для каждой таблицы. Результатом является набор YAML-файлов, каждый из которых описывает схему для одной таблицы. Эти файлы хранятся в центральном репозитории Github, где они доступны как для разработки, так и для использования на сайте клиента. Поскольку схемы таблиц меняются с течением времени, этот CLI-инструмент регулярно запускается в режиме ночного пакетного обновления.
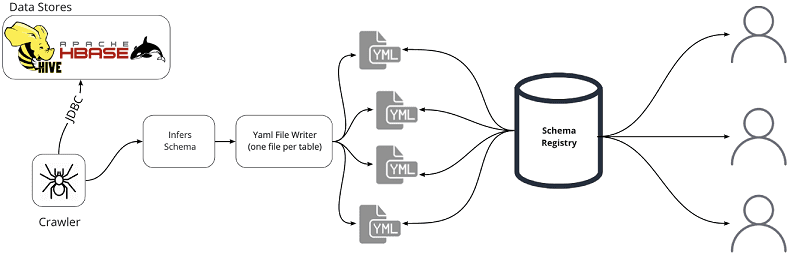
Также в описанный ETL-сценарий был добавлен флаг запуска компонента HiveReader для чтения общей таблицы из Hive для взаимодействия с реестром схем данных. Schema Registry считывает нужный YAML-файл из локальной файловой системы и на основе этой схемы данных создает пустой DataFrame. Далее запускается оптимизированный локальный контекст Spark и ETL-процесс для этого пустого DataFrame стартует точно так же, как в обычном режиме. После окончательного преобразования, вместо обратной записи в таблицу Hive, компонент HiveLoader выполняет проверку схемы данных, сравнивая полученный DataFrame с ожидаемым вариантом. Это делается через взаимодействие с реестром схем. Такое решение удаляет зависимость от любой внешней системы хранения, заменяя ее реестром схем, который является просто компонентом для управления взаимодействием с локальной файловой системой.
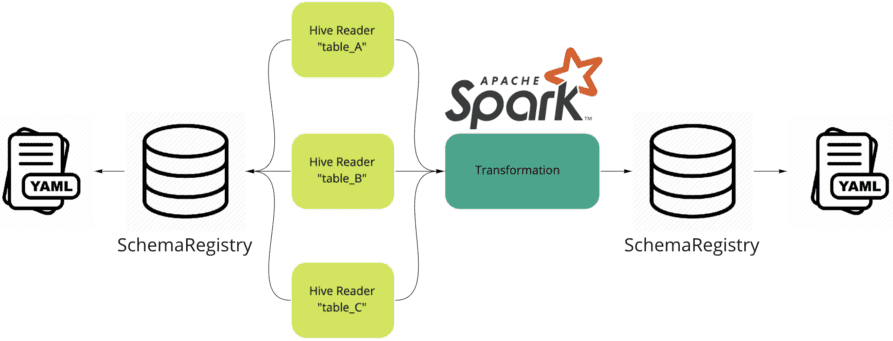
В результате такого нетривиального решения инженеры данных компании Panaseer получили возможность запускать ETL-конвейеры локально, ускорив цикл разработки и тестирования Data Flow примерно в 10 раз. А благодаря тому, что файлы схемы данных хранятся в том же месте, что и конфигурация ETL, можно разрабатывать интеграционные тесты и запускать их непосредственно в среде разработки. Далее эти тесты можно упаковать в задачу системы автоматической сборки Gradle, чтобы далее запускать их как часть рабочих CI-процессов с уверенностью в том, что изменения кода ничего не нарушат. О простых способах оптимизации и повышения производительности конвейеров Apache Spark-приложений читайте в нашей новой статье.
Еще больше интересных приемов по инженерии больших данных в Apache Hadoop с практическими примерами вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Hadoop для инженеров данных
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
- Интеграция Hadoop и NoSQL
Источники

