
Говоря про практическое обучение Apache Spark для дата-инженеров, сегодня рассмотрим особенности разработки собственного коннектора для этого фреймворка на примере его интеграции с BI-системой Tableau. Читайте далее, как конвертировать Spark RDD в нужный формат и сделать свой коннектор удобным для пользователей.
Интеграция Spark с внешними источниками данных через коннекторы
Apache Spark – отличный инструмент для быстрой обработки Big Data, однако он не является хранилищем, в отличие от озера данных на Hadoop HDFS или СУБД, таких как Cassandra, Mongo DB, Greenplum, Elasticsearch и прочие базы данных. Чтобы считывать информацию из Data Lake, СУБД или другого источника, в Спарк используются специальные коннекторы в виде интерфейсов для одной из основных структур данных этого фреймворка — RDD (Resilient Distributed Dataset, надежная распределенная коллекция данных типа таблицы). Полученная информация, как правило, подвергается аналитической обработке и визуализации, например, в BI-инструментах или других системах аналитики больших данных.
Фреймворк предоставляет множеств готовых коннекторов в Spark SQL API. Например, коннектор записи write позволяет легко конвертировать структуру данных DataFrame в CSV с помощью всего одной строки кода: dataframe.write.csv(‘mycsv.csv‘). Также готовые коннекторы Спарк поддерживают и другие распространенные форматы: текстовые файлы, JSON, Parquet, ORC и т.д. Крупные компании-разработчики программного обеспечения уровня Microsoft, MongoDB Inc. Pivotal Software и другие вендоры популярных систем, предлагают собственные форматы хранения больших данных и коннекторы для их интеграции со Спарк. К примеру, популярный продукт для бизнес-аналитики Tableau использует Tableau Data Extract (.tde) илиHyper (.hyper) в качестве форматов хранения своих таблиц [1].
Разработчик аналитической MPP-СУБД Greenplum, на основе которой создана отечественная Arenadata DB, корпорация Pivotal Software также предлагает готовый Greenplum-Spark Connector в виде JAR-файла. Начать работу с ним можно выполнив команду spark-shell с параметром –jars, который определяет путь файловой системы к JAR-файлу Greenplum-Spark Connector [2]:
spark-user@spark-node$ export GSC_JAR=/path/to/greenplum-spark_-.jar
spark-user@spark-node$ spark-shell —jars $GSC_JAR
СУБД Mongo DB также предлагает свой коннектор для Spark, предоставляя доступ ко всем библиотекам этого Big Data фреймворка, включая Scala, Java, Python и R. Данные MongoDB материализованы в виде DataFrames и Datasets для анализа с помощью машинного обучения, графического, потокового и SQL API [3].
При всем многообразии готовых и уникальных коннекторов для Apache Spark, все они работают по одному принципу, который мы рассмотрим далее.
Как устроены коннекторы Спарк и при чем здесь RDD
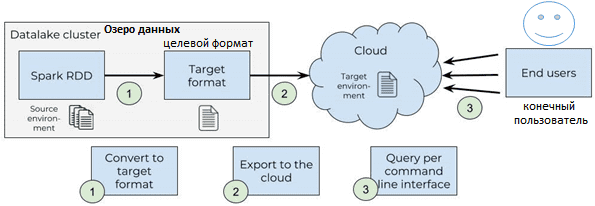
Работу Spark-коннекторов можно представить в виде 3-х этапов [1]:
- преобразование датафрейма в целевой формат. При этом стоит помнить про особенности обработки больших данных в этом фреймворке. В частности, RDD распределены по разделам (parttion), не доступным напрямую драйверу кластера, в котором выполняется код Python. Поэтому для каждого раздела RDD нужно собрать данные для драйвера с помощью метода .collect(), а затем просмотреть собранный раздел и вставить его в целевой файл построчно. Пример такой манипуляции показывает следующий код на Python:
def add_partition_index(partition_index, partition_rows):
yield (partition_index, list(partition_rows))
partitioned_rdd = rdd.mapPartitionWithIndex(add_partition_index)
for current_partition_index in range(rdd.getNumPartitions()):
[(_, current_partition_rows)] = partitioned_rdd \
.filter(lambda x: x[0] == current_partition_index) \
.collect() for row in current_partition_rows:
convert_and_insert(row)
Функция convert_and_insert() будет предоставлена поставщиками данных. К примеру, в случае BI-системы Tableau можно обратиться к Tableau SDK (для формата .tde) или Tableau API 2.0 (для формата .hyper), которые имеют C ++, Java и Python API.
Это предполагает полный контроль разработчика Big Data над следующими факторами:
- память драйвера, которую можно настроить для текущего сеанса Спарк через spark.driver.memory, потому что все разделы, которые будут собраны в этот драйвер один за другим, должны соответствовать;
- разбиение исходного датафрейма, поскольку ни один раздел не должен превышать объем памяти драйвера, чтобы избежать ошибок OutOfMemory, о которой мы говорили вчера.
- Экспорт исходного файла в облако, чтобы сделать данные доступными для пользователей. Например, в случае Tableau это выполняется с помощью REST API для публикации файлов этой BI-системы на ее сервере. Как правило, каждый вендор предоставляет разработчикам выделенные API для публикации данных в облаке. Однако, поскольку не все API достаточно подробно документированы, имеет смысл просмотреть код напрямую, чтобы понять, реализована нужная вам функция.
- Упаковка готового коннектора в удобный для пользователей вид. Например, можно реализовать интерфейс командной строки на Python поверх коннектора. Это позволит пользователю выбирать исходную и целевую среды, между которыми нужно передать данные. С учетом заданных параметров и файла конфигурации, запускаются сервисы преобразования и экспорта для публикации форматированных данных в облаке.
Подробное видео о разработке собственного коннектора Спарк для MongoDB на Java, Python и R доступно для просмотра в [4]. Примечательно, что рассмотренный пример можно легко адаптировать для интеграции Apache Spark с другим источником данных благодаря универсальной последовательности действий по разработке уникального коннектора [4]:
- привести распределенные данные к подходящему формату;
- реализовать код коннектора на Scala или Java;
- предоставить коннектору доступ к нужным функциям фреймворка Спарк, например, потоковая передача Spark Streaming и Spark SQL;
- протестировать работу созданного коннектора;
- расширить разработанный коннектор для поддержки Python и R (если необходимо);
- опубликовать готовый коннектор для общего использования.
В следующей статье мы продолжим разговор про коннекторы Спарк с целью обучения инженеров больших данных и рассмотрим, как устроен Greenplum-Spark Connector, а также кейсы и примеры его практического использования.
А освоить практические особенности эксплуатации Apache Spark для аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://www.sicara.ai/blog/2018-12-12-publish-data-outside-data-lake-spark-connector
- https://greenplum.org/introducing-pivotal-greenplum-spark-connector-integrating-apache-spark/
- https://www.mongodb.com/products/spark-connector
- https://databricks.com/session/how-to-connect-spark-to-your-own-datasource

