
Недавно мы уже рассказывали про ускорение целых аналитических конвейеров на Apache Spark и отдельных задач, а также рассматривали способы оптимизации Shuffle-операций в SQL-модуле этого Big Data фреймворка. Сегодня разберем, какие факторы провоцируют задержки в Spark-приложениях, и как дата-инженер может их найти, чтобы устранить причины и следствия этих проблем.
Задержки Spark-приложений и их идентификация
Отставание снижает общую производительность Spark-приложений и приводит к неэффективному использованию ресурсов в кластере. Поэтому инженеру Big Data важно своевременно выявить потенциально отстающие Spark-задания и определить основную причину их возникновения, чтобы внести исправления в Data pipeline и/или принять превентивные меры. Как правило, отставание относится к очень медленно выполняющейся задаче на определенном этапе Spark-приложения, которая работает с одним разделом из всего количества разделов этого этапа (stage). Отстающая задача требует чрезмерно много времени для завершения по сравнению с остальными на этой же той же стадии. В реальности несколько отстающих задач в одном задании могут присутствовать на одном или на нескольких этапах, снижая скорость выполнения всего аналитического конвейера и общую производительность Spark-приложения. Также отставание может также привести к неэффективной трате ресурсов кластера, если для задания настроены статические ресурсы, т.к. уже освобожденные статические ресурсы этапа не могут быть использованы далее, пока отставшие задачи не завершены.
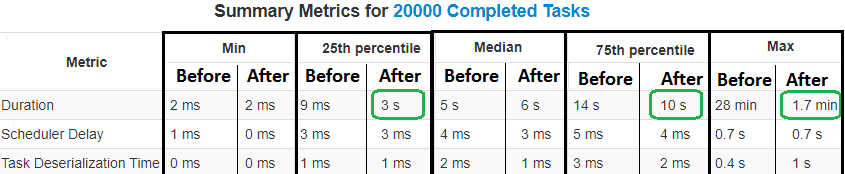
Найти отставшие задачи можно в GUI Apache Spark по «застрявшему» индикатору выполнения этапа. Чтобы подтвердить это предположение, следует открыть подробные сведения со сводной информацией о показателях выполненных задач на этапе. Если максимальная продолжительность отдельной задачи намного превышает значение «медиана» или «75-й процентиль» среди других выполненных задач, это явный признак отставания [1]. Почему это случилось и как исправить ситуацию, рассмотрим далее.
Что провоцирует отставание: 4 самых частых причины
Чаще всего Spark-приложения «тормозят» по следующим причинам [1]:
- Искаженное разбиение (Skewed partitioning), что приводит к асимметрии размера данных в каждом разделе. Когда данные раздела не соответствуют данным, над которыми должны производиться вычисления, искажается распределение времени вычислений между задачами, назначенными для разных разделов. Такая ситуация случается при повторном разделении структуры данных DataSet или RDD на основе ключа партиционирования с искаженным распределение. Также Skewed partitioning происходит, когда группа неразделимых файлов с искаженным размером считывается в DataSet или RDD. Поэтому следует убедиться, что данные равномерно распределены между всеми разделами, когда интенсивность вычислений напрямую связана с размером данных, содержащихся в разделе. При возможности выбирать ключ повторного партиционирования стоит использовать в качестве ключа такой атрибут записи, который обеспечит более высокую мощность и равномерно распределится между записями данных. В частности, рекомендуется использовать reduceByKey вместо groupBy, потому что groupByKey создает много перетасовки, которая снижает производительность, в то время как reduceByKey не перетасовывает данные в такой степени. Следовательно, reduceByKey быстрее, чем groupByKey. Кроме того, при любом применении операции ByKey следует правильно разбивать данные [2]. О том, чем reduceByKey отличается от groupByKey иaggregateByKey(), читайте в нашей новой статье.
- Искаженные вычисления (Skewed Computation), когда пользовательские вычисления для данных разделов искажаются из-за зависимости от определенных атрибутов или свойств данных в разделе, даже если сами данные между разделами распределены достаточно хорошо. Например, когда в конкретном разделе структуры данных DataSet, указывающей на коллекцию объектов FileWrappers, все эти объекты относятся к большим файлам по сравнению с объектами в других разделах. Поэтому необходимо обеспечить равномерное распределение вычислений между разделами, где интенсивность вычислений не связана напрямую с размером данных в разделе, а зависит от определенного атрибута или поля в каждой записи.
- Медленные операции чтения или записи на диск (Slow disk reads/writes), когда отдельный сервер в кластере слишком долго считывает или сохраняет промежуточный RDD/DataSet на диск. Здесь стоит обратить внимание на формат файла. Spark поддерживает CSV, JSON, XML, Parquet, ORC, AVRO и пр. Задания Spark можно оптимизировать, выбрав Parquet-файл с мгновенным сжатием, что обеспечит высокую производительность и лучший анализ, т.к. этот колоночный формат содержит метаданные вместе с самими данными [2]. Также стоит помнить про кэширование в Apache Spark с помощью механизмов persist() и cache(), чтобы сохранять используемые несколько раз данные в памяти и быстрее использовать их, о чем мы рассказывали здесь.
- Чрезмерное увеличение количества ядер ЦП на исполнителя (Higher Number of Cores per Executor), от 4 до 8, что случается из-за одновременного выполнения сложных вычислительных ресурсоемких задач на всех ядрах исполнителя. Такая ситуация одновременного выполнения приводит к борьбе за общие ресурсы, например, память, внутри исполнителя хоста, ухудшая производительность, в частности, garbage collection. Частично решить эту проблему можно, увеличив количество разделов.
Спекуляция Spark-задач как способ решения проблемы с отставаниями
Также устранить отставание в задачах Apache Spark можно через настройки конфигурационного параметра spark.speculation, который по умолчанию равен false. При установке его в значение true, начнется спекулятивное выполнение задач, что означает, перезапуск одной или нескольких задач, которые выполняются слишком медленно на одном этапе. Функция спекуляции Spark сама активно определяет медленно выполняющиеся задачи и снова перезапускает их, чтобы справиться с отставанием, которое возникает из-за нехватки ресурсов у исполнителей или медленного выполнения операций чтения/записи на диск или сетевого ввода-вывода на сервере-хосте. Отметим также настройки spark.speculation, которые пригодятся для точной идентификации отстающих задач [3]:
- speculation.interval (по умолчанию 100 мс) – период времени, который задает, как часто Spark будет проверять наличие отстающих задач для спекулятивного перезапуска;
- speculation.multiplier (по умолчанию 1,5) – показатель, который определяет, во сколько раз медленнее медианы должна выполняться задача, чтобы считаться отстающей.
- speculation.quantile (по умолчанию 0,75) – часть задач, которые должны быть выполнены до включении спекуляции для определенного этапа.
- speculation.task.duration.threshold (по умолчанию None) – продолжительность задачи, по истечении которой планировщик попытается спекулятивно запустить задачу. Если задать этот параметр, задачи будут запускаться спекулятивно, когда текущий этап содержит меньше задач, чем количество слотов на одном исполнителе или равно ему, а задача занимает больше времени, чем пороговое значение. Эта конфигурация помогает бороться с отставанием на этапе с очень небольшим количеством задач. Регулярные спекуляции могут также применяться, если слоты исполнителя велики, например, задачи могут быть повторно запущены, даже когда порог не был достигнут. Количество слотов вычисляется на основе значений конфигураций spark.executor.cores и spark.task.cpus.
Впрочем, спекулятивный запуск задач помогает бороться со следствием, а не причиной отставания. Поэтому, прежде чем использовать конфигурацию spark.speculation, следует определить, почему Spark-задача «тормозит», чтобы прерывание и повторный запуск задач через готовую функцию спекуляции не привел к несогласованности в результатах приложения [1].
В частности, имеет смысл проверить партиционирование. Напомним, во время работы Spark по умолчанию в случайном порядке создает 200 разделов. Разработчику следует определить области, в которых происходит перемешивание (shuffle), и на основе объема обработанных данных определить соответствующие номера разделов во время этой операции. Проверить существующий раздел на датафрейме (df) и распределение данных по разделам можно с помощью команд [2]:
p = df.rdd.getNumberPartitions ()
print (‘distribution:’ + str (df.rdd.glom (). map (len) .collect ()))
Cлишком мало или слишком много разделов негативно для любого приложения. Если все операции перемешивания в коде Spark-приложения обрабатывают примерно один и тот же объем данных, можно определить shuffle-раздел перемешивания на уровне сеанса:
spark.conf.set («spark.sql.shuffle.partitions», «40»)
Или, исходя из потребностей во время shuffle-операции, определить размер, используя repartition (40) или coalesce (40). Здесь 40 – число разделов. Подробнее о том, как работает метод repartition() и чем он отличается от coalesce(), читайте здесь.
Например, оптимизировав искажения в данных и вычислениях с помощью вышеописанных действий, можно в десятки раз уменьшить время выполнения Spark-задач [1].
Освоить на практике все особенности разработки и оптимизации распределенных приложений для аналитики больших данных на Apache Spark, вы можете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- https://dzone.com/articles/identify-and-resolve-stragglers-in-your-spark-appl
- https://nivedita-mondal.medium.com/spark-optimization-technique-how-to-improve-performance-for-your-spark-application-f75dc58b6b86
- https://spark.apache.org/docs/latest/configuration.html

