Поскольку курсы инженеров Big Data предполагают практическое обучение на реальных кейсах, сегодня поговорим про тестирование конвейеров обработки и аналитики больших данных и разберем несколько прикладных примеров для компонентов экосистемы Apache Hadoop. Читайте далее про проверку работоспособности, а также поиск ошибок в Spark-заданиях и DAG-цепочках Airflow.
Конвейер для конвейера: сложности тестирования комплексных Big Data заданий
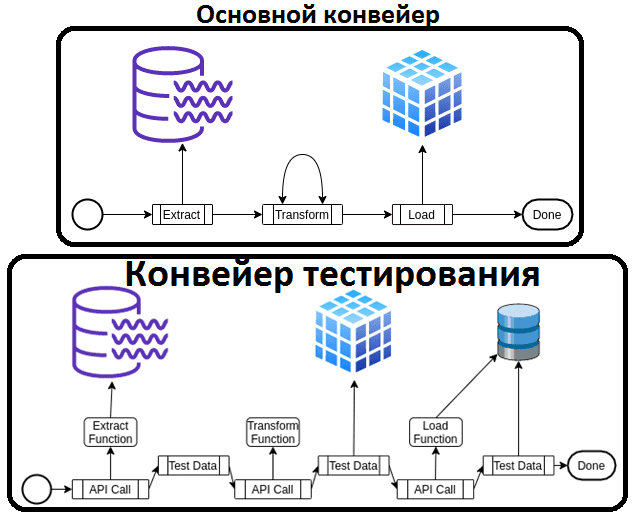
На первый взгляд, тестирование конвейеров аналитики больших данных не слишком отличается от проверки отдельных функций или целых приложений. Однако, в случае Big Data Pipeline’а нужно не просто проверить работоспособность единичных задач, но и несколько раз перебрать исходные данные, чтобы понять узкие места всей цепочки их обработки. При том, что внутреннюю логику задач можно протестировать с помощью модульных тестов, нельзя просто отбросить события, которые не соответствуют заранее заданному стандарту. Даже в случае не корректных данных конвейер не должен выходить из строя, а данные не должны быть потеряны. Поэтому недостаточно просто написать несколько тестов с конкретными входными образцами, нужно тестировать конвейер на реальных данных в любой момент времени. Автоматизировать процесс тестирования конвейера можно через конвейер тестирования следующим образом [1]:
- сначала выделить в основном конвейере тестируемые части, например, ETL;
- написать другой конвейер, который использует основной pipeline как API;
- тест должен проверить результат работы основного конвейера;
- запускать конвейер тестирования в той же среде, что и основной, с теми же данными, т.е. проводить тесты на реальных данных в реальном времени.
Таким образом, конвейер тестирования позволяет дата-инженеру контролировать, какие данные загружаются и обрабатываются, каков объем этих данных и скорость их обработки в реальном времени. Тестовый pipeline позволит проверить, совпадают ли тестовые данные с реальными и находятся ли отклонения в допустимых пределах. Однако, конвейерные тесты не заменяют обычные модульные и прочие тесты, передающие образцы данных через основной конвейер. Конвейер тестирования зависит от основного, что позволяет проверять его отдельные функции.
Пример реализации конвейеров тестирования pipeline’ов из Spark-заданий описан в источнике [1]. Проверить работоспособность связанных друг с другом Spark-приложений предлагается с помощью достаточно простых тестов на Scala в мульти-модульном Maven-проекте, Docker-образ которого развернут в Kubernetes.
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
22 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
От сенсора до DAG-конвейера: 5 видов тестов в Apache AirFlow
Разумеется, на практике дата-инженеру приходится тестировать не только Spark-конвейеры. Еще одной популярной технологий стека Apache Hadoop является Airflow, который позволяет разрабатывать, планировать, запускать и отслеживать выполнение заданий с помощью Python-операторов. Несколько связанных задач, которые операторы обрабатывают последовательно или параллельно, представляют собой цепочку DAG (Directed Acyclic Graph) – направленный ациклический граф. DAG описывает, как запускать рабочий процесс, а оператор – выполнение его отдельной задачи. Apache Airflow предоставляет множество готовых операторов для решения типовых задач, например, BashOperator выполняет команду bash, PythonOperator вызывает произвольную функцию Python, EmailOperator отправляет электронное письмо, а HTTPOperator — HTTP-запрос, Sensor (сенсор) ожидает определенное время, файл, строку базы данных, ключ AWS S3 и пр. Таким образом, для Apache Airflow можно написать следующие тесты [2]:
- тесты валидации DAG (DAG Validation Tests) для проверки опечаток и цикличности цепочки задач. Эти тесты являются общими для всех DAG’ов в Airflow, поэтому не нужно писать отдельный тест для каждого DAG. Такой тест проверит правильность каждого DAG, наличие опечаток и циклов или нет. Также эти тесты полезны, когда нужно проверить корректность изменений аргументов DAG’а, которые внес разработчик.
- тесты определения DAG или конвейера (DAG/Pipeline Definition Tests) для проверки общего количества задач в DAG-цепочке, восходящих и нисходящих зависимостей каждой задачи в конвейере и пр. Эти тесты похожи на тестирование snapshot’ов, они не проверяют логику обработки, а только помогают проверить определение конвейера: общее количество задач и их характер, восходящие и нисходящие зависимости. Нужно каждый раз писать такие тесты для каждого DAG’а.
- модульные тесты (Unit Tests) для проверки логики пользовательских операторов и сенсоров. Это требуется при разработке собственных операторов и сенсоров, чтобы проверить, как они выполняются.
- интеграционные тесты (Integration Tests) для проверки связи между задачами, например, через Xcom для коммуникаций разных операторов друг с другом;
- cквозные конвейерные тесты (End to End Pipeline Tests, E2E) для тестирования и верификации интеграции каждой задачи с другими.
Для запуска интеграционных тестов и сквозного конвейерного тестирования нужна тестовая среда, похожая на production, но в меньшем масштабе, чтобы убедиться, что все работает корректно и будет выполняться так, как надо, в реальном Big Data кластере. Подробные примеры валидационных, определительных и модульных тестов на Python для AirFlow-задач приведены в источнике [2], а интеграционных и конвейерных – в источнике [3]. Проверить свое знание Apache AirFlow вы можете прямо на нашем сайте, ответив на 10 вопросов открытого интерактивного теста для дата-инженеров.
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
22 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Освоить практику построения эффективных конвейеров аналитики больших данных в экосистеме Apache Hadoop с AirFlow и Spark, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- https://medium.com/everything-full-stack/sparkjob-testing-with-live-data-c8542890f5b6
- https://blog.usejournal.com/testing-in-airflow-part-1-dag-validation-tests-dag-definition-tests-and-unit-tests-2aa94970570c
- https://medium.com/@chandukavar/testing-in-airflow-part-2-integration-tests-and-end-to-end-pipeline-tests-af0555cd1a82

