
В этой статье для разработчиков Apache Kafka рассмотрим пример масштабирования потоковой обработки событий с Akka Streams. Читайте далее, что не так с параллелизмом при одновременном выполнении событий на запись, как Akka Streams решает эту проблему и при чем здесь Apache Kafka.
Проблемы масштабирования потоковой обработки в Kafka Streams
Масштабная потоковая обработка часто вызывает проблемы, связанные с параллелизмом, особенно при выполнении операций записи. Например, два события появляются в потоке почти одновременно и оба модифицируют один и тот же объект. Если они обрабатываются параллельно, то одно из них может завершить запись первым, но его результаты будут перезаписаны другим, т.е. часть данных потеряется. Apache Kafka решает эту проблему гарантируя, что события с одним и тем же ключом всегда появляются в одном разделе. Пока ключ однозначно идентифицирует изменяемый объект и раздел обрабатывается только в одном месте за раз, потери данных в рамках одного экземпляра не возникает. Kafka Streams использует эти гарантии для решения проблемы, требуя, чтобы для каждого раздела одновременно обрабатывалось только одно событие. Однако, если события в разделе относятся к разным объектам, должна быть возможность обрабатывать их параллельно, а Kafka Streams не позволяет сделать это.
Для решения этой проблемы можно использовать Akka Streams – это Reactive Streams и JDK 9+ java.util.concurrent.Flow-реализация, полностью совместимая с другими реализациями. Напомним, Akka – это набор библиотек с открытым исходным кодом для проектирования масштабируемых, отказоустойчивых систем, охватывающих ядра процессоров и сети, который позволяет сосредоточиться на бизнес-логике вместо написания низкоуровневого кода, обеспечивая надежное поведение, отказоустойчивость и высокую производительность. Эластичная кластерная архитектура Akka является эластичной, масштабируемой или расширяемой по запросу, позволяя создать реактивную систему. А благодаря использованию модели акторов обеспечивается уровень абстракции, который упрощает разработку параллельных и распределенных систем. Модель акторов охватывает полный набор библиотек Akka, предоставляя единообразный способ их понимания и использования. Что именно представляет собой модуль Akka Streams мы рассмотрим далее.
Параллельная обработка событий с Akka Streams
Akka Streams позволяет гибко запускать несколько событий для каждого раздела с помощью метода mapAsync(). Метод дает возможность сопоставить каждое входящее событие в потоке с будущим и запускать настраиваемое количество этих будущих событий параллельно с гарантией того, что результирующие события будут генерироваться по порядку независимо от времени их фактического завершения. Но запуск метода mapAsync() со значением параллелизма, равным единице приведет к подходу Kafka Streams «одно событие для каждого раздела за раз», снижая пропускную способность всей системы.
Поэтому вместо использования mapAsync() для непосредственного выполнения будущих событий следует вызвать метод ask(), который сам возвращает будущее событие для сообщения соответствующему актору. Затем этот субъект может обработать указанное сообщение, выполнив будущую логику, ранее запланированную для mapAsync() с гарантией, что только одно будет выполняться за раз. После того, как актор получает свое сообщение и запускает желаемое будущее, он может немедленно вернуться из обработчика или заблокировать, пока будущее событие не завершится. В первом случае актор немедленно начнет обрабатывать следующее событие, если оно существует. Но при этом нет гарантии, что предыдущее будущее завершилось на этом этапе, поэтому снова возникает параллельное выполнение нескольких событий для одного и того же объекта.
Второй подход гарантирует, что второе событие не будет обработано, пока не завершится первое, но Akka прикрепляет несколько участников к одному программному потоку. Хотя переключение контекста для управления этим общим потоком встроено в сам фреймворк и обычно незаметно для разработчика, блокирование этого потока для одного актора рискует лишить других участников их собственного доступа к потоку.
Однако, Akka позволяет буферизовать («хранить») сообщения для последующей обработки, а затем разблокировать их («распаковать») в режиме FIFO в любое время. Также Akka позволяет актору изменять свое поведение в ответ на различные сообщения, фактически делая актора своего рода конечным автоматом, который переключается между двумя режимами. Первый режим обрабатывает входящие сообщения, а второй режим буферизации, который их сохраняет. Каждый субъект запускается в первом режиме приема, но переключается в режим буферизации, как только он получает сообщение и инициирует первое будущее событие. В этот момент любые дальнейшие сообщения будут буферизированы — то есть, до тех пор, пока не завершится будущее, после чего актор открепит первое сообщение в своем буфере (если он существует) и вернется в режим приема. Такой подход позволяет гарантировать, что одновременно обрабатывается только одно будущее событие без блокировок.
Альтернативой является настройка отдельного пула потоков для обработки блокирующих субъектов. Это решение эффективно, но дорого, поскольку увеличивает потребление памяти на дополнительные пулы потоков. Kafka Streams тоже позволяет обрабатывать несколько событий параллельно, инициируя асинхронное задание для каждого события и выход из обработчика по завершении. Так можно начать обработку следующего события, пока задание еще выполнялось, и зафиксировать связанное смещение, гарантируя, что в случае сбоя этого задания событие все равно будет считаться завершенным и фактически отброшено.
Коннектор Alpakka Kafka, который раньше назывался Akka Streams Kafka и Reactive Kafka, позволяет бесшовно подключать Apache Kafka к Akka Streams. Поскольку клиентский протокол Kafka согласовывает версию для использования с брокером, можно использовать версию клиента, которая отличается от версии брокера. Отдельные пакеты с именами akka.kafka.scaladsl и akka.kafka.javadsl с API для Scala и Java соответственно содержат классы Producer и Consumer с фабричными методами для различных потоков Akka Streams Flow, Sink и Source, которые создают или принимают сообщения в топики Kafka или из них.
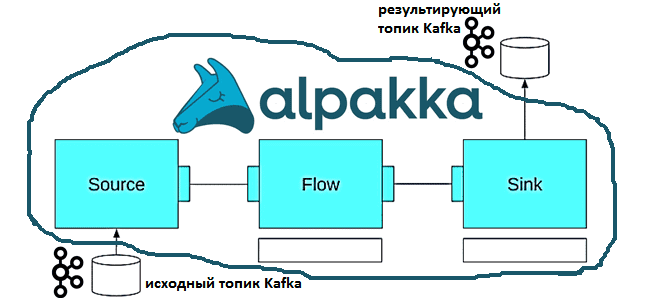
Американская туристическая компания Expedia Group протестировала все описанные альтернативы и выбрала Akka Streams для применения в своих внутренних потоковых сервисах с различными функциями, от агрегирования потоков до записи в базу данных. Эта технология позволила компании безопасно обрабатывать сотни событий одновременно из каждого раздела, значительно увеличивая пропускную способность системы. В заключение разработчики Expedia Group рекомендуют хранить соединения в экземплярах акторов, а не в сообщениях, чтобы сократить время на изменение системы, когда это потребуется.
О других проблемах потоковой обработки и способа их решения с помощью платформы Redpanda как альтернативы Apache Kafka, читайте в нашей новой статье.
Узнайте больше интересных примеров администрирования и эксплуатации Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

