Сегодня рассмотрим примеры совместного использования двух популярных технологий потоковой обработки больших данных (Big Data): Apache Kafka и NiFi. Читайте в нашей статье, как они дополняют друг друга, каковы преимущества их объединения и каким образом инженеру Data Flow это реализовать на практике.
Еще раз о том, что такое Apache Kafka и NiFi: краткий ликбез для инженера Big Data
Напомним, Apache Kafka – это отказоустойчивая распределенная стриминговая платформа, которая часто используется в качестве брокера сообщений. Она работает по принципу «издатель-подписчик», когда кластерные серверы (брокеры) принимают данные из источников (производителей, producer) и передают их потребителям (consumer). Отправляя сообщение в кластер Kafka, производитель указывает, в какой топик (topic) его записать. Топик – это набор сообщений, которые реплицируются и упорядочиваются по смещению (offset) – возрастающему значению, которое присваивается каждому сообщению, добавляемому в топик. Это смещение позволяет повторно считывать данные, а также дает потребителям возможность выбирать собственный темп для получения сообщений из топика. Еще одним достоинством кластера Kafka является его горизонтальная масштабируемость для обработки любого количества производителей и потребителей [1].
В свою очередь, Apache NiFi – это инструмент работы с потоками данных (Data Flow), который обеспечивает их маршрутизацию, включая ETL-процессы, позволяя конечным пользователям делать это в визуальном режиме через веб-GUI через добавление новых пунктов назначения и источников с возможностью воспроизведения в любое время. NiFi оперирует потоковыми файлами и процессорами. Файл потока данных – это единый фрагмент информации из заголовка и содержимого, аналогично HTTP-запросу. Заголовок содержит атрибуты, которые описывают тип данных содержимого, время создания и уникальный идентификатор (uuid), а также пользовательские свойства. Содержимое потокового файла — это просто необработанные данные, которые передаются: простой текст, JSON, байт-коды и пр. Для работы с потоковыми файлами NiFi использует множество обработчиков (процессоров) – отдельных фрагментов кода для выполнения конкретной операции с потоковыми файлами [1].
Таким образом, Apache Kafka и NiFi не дублируют назначение и функциональные возможности друг друга, а могут использоваться совместно, расширяя инструментарий инженера Data Flow и архитектора Big Data систем. Далее мы разберем несколько практических примеров, когда и как это реализуется.
Как совместить Кафка и Найфай: несколько реальных кейсов
Рассмотрим следующий сценарий: через Kafka поступают сообщения в формате JSON, из которых следует отправить в Apache HBase только те записи, в которых заполнены все поля. Apache NiFi поможет сделать это быстро и просто в режиме веб-GUI, избегая ручного напичания большого количества программного кода. В частности, в NiFi есть процессоры ConsumeKafka, которые можно настроить на конкретный брокер и имя группы Kafka. Другой NiFi-процессор, ValidateRecord, позволит проверить, все ли полученные сообщения отвечают заданным требованиям насчет полей. За вывод данных в HBase отвечает PutHBaseRecord [2].
Это один из возможных сценариев, но далеко не единственный вариант совместного использования Apache Kafka с NiFi, который может выступать как в качестве производителя, так и в качестве потребителя для брокера сообщений. В первом случае NiFi будет генерировать различные типы входных данных из множества источников и пересылать их брокеру Kafka. При этом пользователь может направить сообщения в нужный топик Kafka путем расстановки NiFi-процессоров PublishKafka в рабочей области, чтобы визуально отслеживать и контролировать этот конвейер обработки данных (data pipeline) [3]. Примечательно, что настройка (конфигурирование процессора также производится в визуальном режиме. Это существенно снижает порог входа в эту Big Data технологию, позволяя строить собственные data pipeline не только опытному инженеру DataFlow, но и аналитику данных, а также Data Scientist’у.
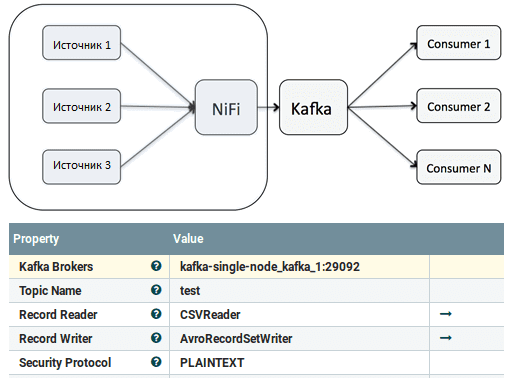
Аналогичным образом, Apache NiFi может выступать в роли потребителя Kafka, реализуя всю логику обработки данных. Например, взять данные из Kafka и передать их в другую Big Data систему. В этом случае также вся работа выполняется в GUI через простое перетаскивание и настройку NiFi-процессора ConsumeKafka. В частности, так можно доставлять данные из Kafka в HDFS, HBase или другую Big Data систему без написания программного кода [3].
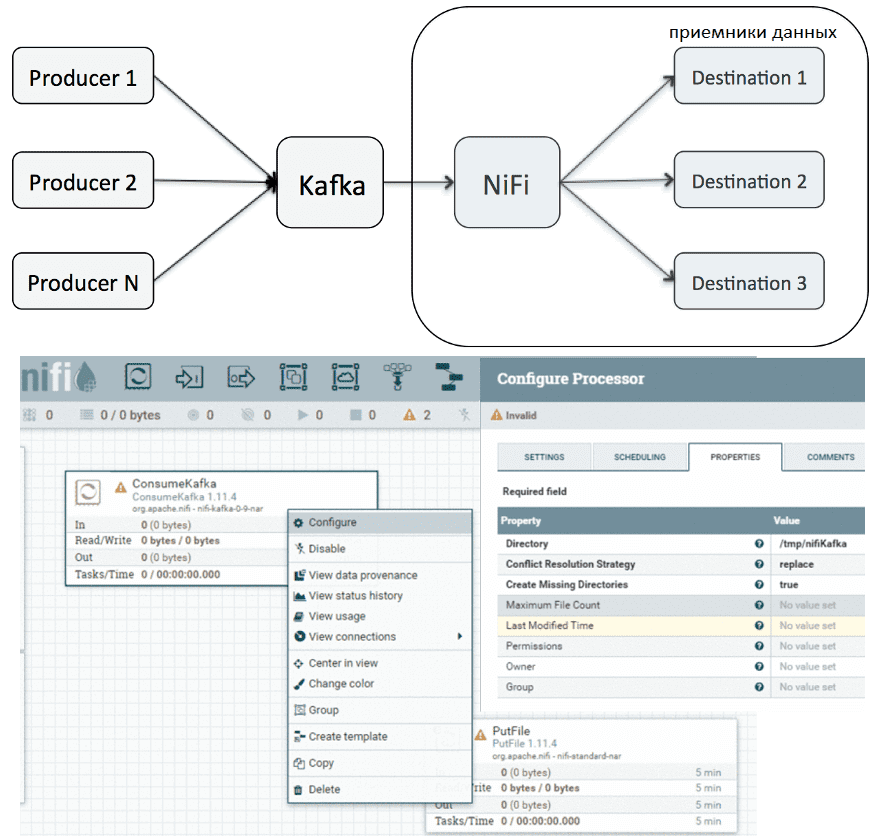
Наконец, помимо удобства графического интерфейса и гибкой настройки уже готовых процессоров в визуальном режиме, NiFi позволяет создавать собственные обработчики на Python, который очень распространен в области Data Science и считается проще Java, который поддерживает Kafka Streams. Таким образом, сочетание NiFi с Кафка дает максимальную гибкость для разработчиков Data Flow и инженеров Big Data, которые поддерживают этот pipeline. В частности, можно анализировать данные из топиков Kafka с помощью специализированных Data Science Python-библиотек [1]. Учитывая все преимущества совместного использования Apache Kafka с NiFi, неудивительно, что российский разработчик корпоративных Big Data на открытых технологиях, компания «Аренадата Софтвер» построила на базе этих фреймворков целую платформу потоковой обработки больших данных в режиме реального времени — Arenadata Streaming, о которой мы рассказываем здесь. О том, где еще пригодится интеграция Apache Kafka с NiFi, читайте в нашей новой статье.
Все технические детали совместного и раздельного использования Apache Kafka и NiFi для потоковой обработки больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

