
Аутентификация – далеко не единственная возможность обеспечения информационной безопасности в Apache Kafka. Сегодня мы продолжим разговор про Big Data cybersecurity и рассмотрим особенности авторизации в Apache Kafka в формате самообслуживания (self-service), как это было сделано в travel-компании Booking.com. В качестве примера продолжим разбирать доклад Александра Миронова, который был представлен 23 января 2020 года на зимнем Кафка-митапе Avito.Tech.
Принципалы, ACL и другие особенности авторизации Apache Kafka
Apache Kafka включает встроенный фреймворк авторизации (Authorizer), который использует ZooKeeper для хранения всех списков избирательного доступа (ACL, Access Control List) для детального определения прав клиентов кластера на чтение или запись ресурсов (топик с сообщениями, группа, идентификатор транзакции и пр). Authorizer по умолчанию ограничивает доступ к ресурсам всем, кроме суперпользователей (super users). Поэтому для каждого ресурса необходимо настроить собственный ACL. При этом сами ACL-списки хранятся в Zookeeper, который имеет собственные ACL-настройки для доступа к его узлам [1].
Именно такая зависимость от Zookeeper и стала основной причиной, почему администраторы Kafka в компании Booking.com предпочли другой способ авторизации. Кроме того, правила настройки ACL-списков Кафка могут показаться слишком сложными пользователю, который ранее не работал с этой Big Data системой. В частности, чтобы разрешить отдельному принципалу читать данные из конкретного топика, необходимо предоставить ему 2 ACL-разрешения: на получение сообщений (consume) и на присоединение к определенной группе, чтобы предотвратить несанкционированный доступ постороннего получателя (consumer’a). Напомним, в Кафка принципал (principal) – это объект, который может быть аутентифицирован Authorizer’ом, идентификационные данные пользователя или программного обеспечения, запрашивающего разрешение на выполнение определенного действия с определенным ресурсом. Принципалы могут быть аутентифицированы или не аутентифицированы (анонимные). Клиенты брокера Kafka идентифицируют себя как конкретного принципала, используя различные протоколы безопасности (mTLS, SASL/GSSAPI или SASL/PLAIN) [1]. Подобная специфика понятна опытным администраторам кластера Кафка, но непрозрачна для пользователя без специальных знаний. Поэтому команда Booking.com начала поиск решения с более высоким уровнем абстракции, который будет отвечать формату самообслуживания (self-service) [2]. Как это было реализовано на практике, мы рассмотрим далее.
Собственная панель управления или self-service авторизации кластеров Кафка в Booking.com
Чтобы обеспечить понятную и самообслуживаемую авторизацию ресурсов Кафка, администраторы Big Data инфраструктуры в компании Booking.com разработали специальную панель управления (Control Plane), частично о которой мы уже рассказывали. Это простое Java-приложение с API-интерфейсом обеспечивает следующие возможности:
- управление множеством кластеров (на январь 2020 года в Booking.com насчитывалось более 45 кластеров Кафка);
- прозрачное задание и поддержка атрибутов принадлежности ресурсов Kafka бизнес-подразделениям, проектам и сервисам;
- аутентификация и авторизация клиентов в формате self-service;
- понятная человеку аутентификация пользователей по RBAC-модели (Role Based Access Control), о которой мы писали здесь;
- интерфейс командной строки (CLI, Command Line Interface) для непосредственного взаимодействия пользователя и REST API;
- логгирование всех изменений, которые были проведены через Control Plane, в отдельный топик для их последующего аудита (при необходимости).
Все корпоративные кластера Кафка были интегрированы с этой панелью управления путем переопределения следующих классов [2]:
- client.quota.callback.class – интерфейс обратного вызова квот для брокеров, который позволяет настраивать расчет клиентских квот [3], например, задать, откуда берутся квоты или какое значение квоты должно быть передано во внутренние классы Kafka для определенного принципала. Квота в Кафка – это максимальный предел количества сообщений в секунду, который можно ограничить конкретным значением.
- authorizer.class.name – подключаемый интерфейс авторизатора для брокеров Kafka [4], который позволяет использовать собственный сервис хранения ACL-списков вместо Apache Zookeeper;
- topic.policy.class.name – интерфейс для применения политики по запросам на создание топиков. Если create.topic.policy.class.name определено, Кафка создаст экземпляр указанного класса, используя конструктор по умолчанию, а затем передаст его конфигурации брокера методом configure () [5].
- alter.config.policy.class.name – интерфейс для применения политики к запросам на изменение конфигураций. Если alter.config.policy.class.name определен, Kafka создаст экземпляр указанного класса, используя конструктор по умолчанию, а затем передаст конфигурации брокера методом configure () [6].
- principal.builder.class — подключаемый интерфейс основного конструктора, который поддерживает SSL-аутентификацию через SSLAuthenticationContext и SASL через SaslAuthenticationContext [7]. Он также позволяет из набора строк SSL-сертификата составить имя пользователя (user name) или другой параметр для гибкой и автоматической настройки прав доступа к ресурсам Kafka.
Общая схема взаимодействия Кафка с разработанной панелью управления выглядит так [2]:
- периодически Кафка запрашивает от Control Plane квоты и ACL-списки;
- получив квоты и ACL-списки, Кафка записывает их в локальный кэш (Local Cache);
- каждый запрос на создание и модификацию топика Кафка направляет в Control Plane, чтобы провалидировать (оценить корректность и возможность выполнения) и осуществить его;
- метаданные приложений хранятся во внутреннем сервисе Service Directory;
- все общение взаимодействие пользователя с кластером Кафка происходит через Control Plane по REST API.
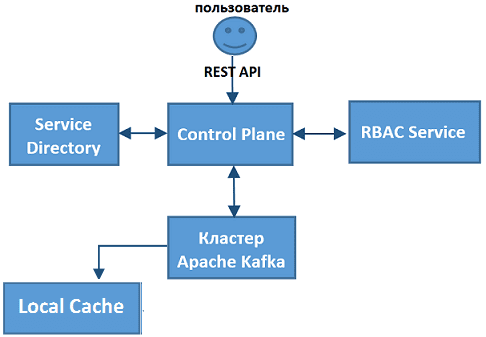
Таким образом, собственная панель управления существенно облегчила работу администраторов Apache Kafka, автоматизировав функции создания и модификации топиков, с проверкой возможностей их выполнения отдельным клиентом (пользователем или приложением). В результате был существенно улучшен пользовательский опыт работы с этой Big Data системой как на уровне разработчиков (Developers), так и администраторов (Operators), что соответствует принципам DevOps-подхода. Однако, создание такого уникального self-service решения не обошлось без эксцессов, о которых мы поговорим в следующей статье.
А как на практике настроить авторизацию Apache Kafka для потоковой обработки больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://docs.confluent.io/current/kafka/authorization.html
- https://habr.com/ru/company/avito/blog/486278/
- https://kafka.apache.org/21/javadoc/org/apache/kafka/server/quota/ClientQuotaCallback.html
- https://kafka.apache.org/24/javadoc/org/apache/kafka/server/authorizer/Authorizer.html
- https://kafka.apache.org/10/javadoc/org/apache/kafka/server/policy/CreateTopicPolicy.html
- https://kafka.apache.org/10/javadoc/org/apache/kafka/server/policy/AlterConfigPolicy.html
- https://kafka.apache.org/10/javadoc/index.html?org/apache/kafka/common/security/auth/KafkaPrincipalBuilder.html

