Как количество разделов топика Apache Kafka влияет на потребителей и продюсеров, зачем нужны группы потребителей и как этот механизм реализует идею микросервисной архитектуры Big Data систем.
Как работают группы потребителей в Apache Kafka
Будучи распределенной платформой потоковой передачи событий, Apache Kafka выполняет роль средства обмена сообщениями между приложениями-продюсерами и приложениями-потребителями в реальном времени. Потребители Kafka читают потоки данных от продюсеров, потребляя события или сообщения из логов, называемых топиками. Топик может быть разделен на разделы, которые представляют собой логи только для добавления, где хранятся сообщения. Это позволяет размещать каждый топик и реплицировать его между несколькими брокерами.
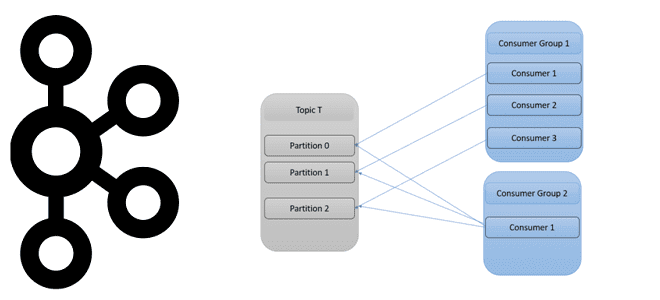
Таким образом, в Apache Kafka раздел топика является единицей параллелизма, позволяя нескольким потребителям получать информацию от продюсера. Предположим, один топик разделен на 3 раздела и в группе потребителей есть только один, который будет получать все сообщения со всех трех разделов. Если в группе будет несколько потребителей с одинаковым group.id, каждый раздел будет потребляется только одним приложением-потребителем. Таким образом, наибольшая степень параллелизма группы потребителей достигается лишь тогда, когда в топике нет разделов. Идентификаторы групп можно назначать с помощью конфигурации при создании клиента-потребителя.
Примечательно, что данные из одного топика могут считываться несколькими группами потребителей одновременно. Когда несколько приложений-потребителей одной группы считывают данные из Kafka, каждый из них получает сообщения из разных разделов топика, что выравнивает нагрузку на брокеры. А благодаря уникальному назначению разделов по потребителям внутри одной группы, Kafka позволяет избежать повторной обработки данных.
Когда пропускной способности потребителей в одной группе недостаточно для обработки поступающих событий, имеет смысл добавить новый раздел в топик Kafka.
Однако, если количество разделов меньше количества потребителей в группе, какие-то приложения-потребители будут простаивать и вообще не получат сообщений. Механизм группы потребителей в Apache Kafka предполагает, что количество потребителей внутри группы должно быть равно или меньше числа раздела в топике. На один топик может быть подписано несколько групп потребителей, которые абсолютно независимы и работают автономно друг от друга.
Смена владельца раздела от одного потребителя к другому называется перебалансировкой, которая позволяет легко и безопасно добавлять и удалять потребителей. Но при перемещении разделов от одного потребителя к другому, текущий потребитель теряет свои сообщения. Поэтому Kafka использует механизм heartbeat-сигналов, обеспечивая активный сеанс потребителя и перебалансировку при смене состава группы, например, когда к ней присоединяются новые потребители, покидают ее или находятся в состоянии бездействия (простаивают). Подробнее про механизм перебалансировки приложений-потребителей читайте в наших новых статьях: здесь и здесь.
За распределение сообщений по разделам топика отвечает ключ партиционирования, который гарантирует, что сообщения от продюсера с одним и тем же ключом отправляются в один и тот же раздел топика. Это обеспечивает порядок внутри раздела, т.к. иначе Apache Kafka выполняет круговой перебор и сообщения от одного клиента могут попасть в разные разделы, что приведет к нарушению порядка их обработки.
Идентификаторы групп связываются через брокер с битами информации, называемыми смещениями, которые определяют местоположение конкретного события в разделе, предоставляя продвижение по топику. По сути, смещения в группах потребителей похожи на закладки в книгах.
В заключение подчеркнем важность концепции группы потребителей при проектировании микросервисной архитектуры. Важно убедиться, что у каждого микросервиса есть собственная группа потребителей со своим уникальным идентификатором. Например, есть топик, куда записываются события о платежах. Микросервисам «заказы» и «возвраты» потребляют данные из этого топика. Однако, они не должны разделять одни и те же данные, т.к. сообщения придется делить по заказам и возвратам, что чревато пропущенными заказами или возмещениями.
Используя группу потребителей, обрабатывающих заказы путем чтения из разделов в топике с платежами, текущее смещение для каждого потребителя в группе, хранящееся в брокере, обеспечивает непрерывный прогресс обработки данных даже если какой-то из потребителей терпит сбой. При этом приложения-потребители из другой группы, относящиеся к сервису возвраты, бесперебойно читают сообщения о платежах из топика Kafka, независимо от состояния и степени перебалансировки потребителей из группы заказы.
Больше подробностей про администрирование и эксплуатацию Apache Kafka в системах аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники

