
Для высоконагруженных Big Data систем и платформ интернета вещей (Internet of Things, IoT) с непрерывными информационными потоками Apache Kafka, практически, стала стандартом де факто для обмена сообщениями и управления очередями. Аналогичную популярность среди DevOps-инструментов завоевал Kubernetes (K8s) как наиболее мощное средство для автоматизации развертывания и управления контейнеризованными приложениями. В этой статье мы поговорим, как использовать эти технологии вместе и насколько это эффективно.
Зачем разворачивать Apache Kafka на Kubernetes
Одна из главных выгод применения Kubernetes с точки зрения DevOps – это стандартизация процессов развертывания и масштабирования распределенных приложений. Можно значительно ускорить наращивание кластера, рассматривая брокер Кафка как приложение в рамках одного пода (pod) K8s – добавление новых брокеров выполняется с помощью пары kubectl-команд или нескольких строк в файле конфигурации. Также изменения, обновления и перезапуски кластера Apache Kafka становятся значительно проще [1]. В частности, можно свести к нулю длительность простоев кластерных узлов при обновлениях. Это достигается благодаря StatefulSet-объектам Kubernetes, которые работают со множественными нагрузками, сохраняющими состояниями, координируя их путем упорядочения и гарантии уникальности подов. StatefulSet обеспечивает автоматические обновления: при выборе стратегии RollingUpdate каждый под Kafka будет обновляться по очереди [2].
Кроме того, через интерфейс командной строки пода можно решать некоторые задачи администрирования кластера Apache Kafka , в частности, создание топиков (topic) и переприсваивание секторов можно сделать с помощью shell-скриптов K8s [2].
Администрирование кластера Kafka
Код курса
KAFKA
Ближайшая дата курса
29 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Таким образом, Kubernetes в очередной раз реализует свое практическое назначение в качестве эффективного DevOps-инструмента для автоматизированного управления процессами разработки и эксплуатации.
Проблемы совмещения Кафка и Кубернетис
Однако, несмотря на вышеотмеченное преимущество, совместное использование Apache Kafka и Kubernetes сопровождается следующими проблемами [2]:
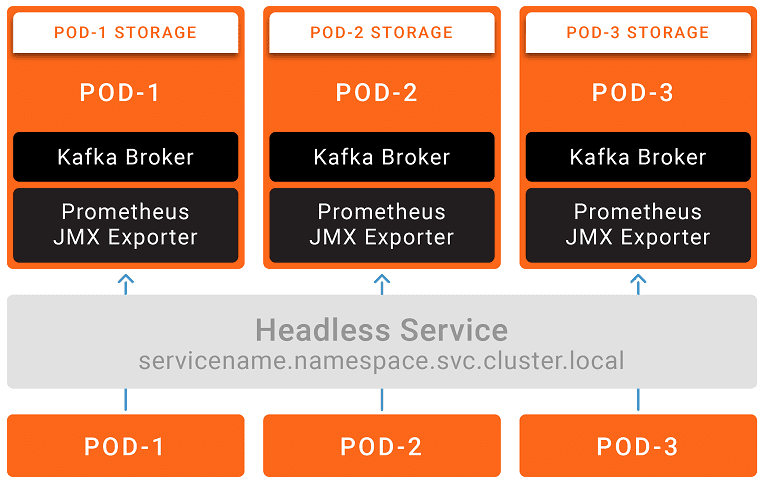
- данные в контейнерах теряются при их перезапуске – для сохранения сообщений Кафка потребуется внешнее, долговременное и нелокальное хранилище данных, чтобы K8s гибко выбирал новый узел после перезапуска или релокации;
- снижение производительности узла – работающий брокер Apache Kafka потребляет очень много оперативной памяти, поскольку активно использует страничный кэш. Это следует учитывать при определении ресурсных пределов для контейнеров K8s. Также стоит иметь ввиду, что клиенты и брокеры Кафка могут существенно нагружать CPU.
- снижение отказоустойчивости – в случае отказа узла Kubernetes, откажет весь кластер Kafka. Поэтому следует найти баланс между распределением брокеров и рабочих узлов. Не стоит размещать все брокеры Кафка на одном узле K8s, также, как и рассредоточивать их по разным датацентрам. Можно поэкспериментировать с разными зонами доступности в поиске приемлемого компромисса между узловой нагрузкой и пропускной способностью сети. Для снижения рисков потери данных в случае сбоя необходимо резервное копирование сообщений и логов Apache Kafka, например, в облачное хранилище Amazon S3, базу данных или распределенную файловую систему HDFS.
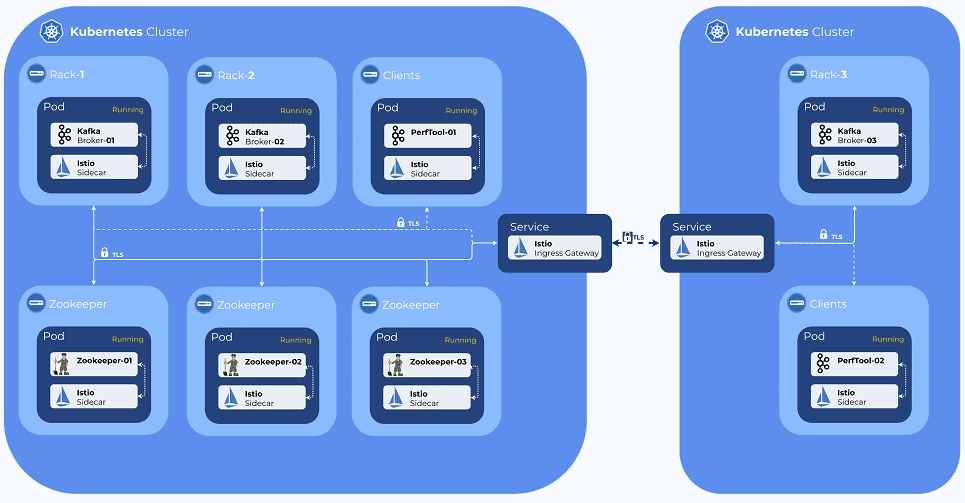
На практике развертывание Кафка на Kubernetes пока не слишком распространено. Сегодня наиболее крупным апологетом совместного использования этих 2-х технологий является компания Confluent, которая продвигает коммерческую версию Apache Kafka и сопутствующих Big Data технологий: Confluent Platform, Confluent Cloud. В частности, для автоматизации развертывания и управления кластером Кафка на Kubernetes предлагается проприетарная реализация API-оператора K8s – Confluent Operator [3]. Тем не менее, с учетом распространения DevOps-инструментов, в т.ч. в мире Big Data, можно сделать вывод о будущей востребованности совместного использования Apache Kafka и Kubernetes. Это подтверждает опыт логистической компании Sixfold, о чем мы рассказываем здесь. А, как получить все преимущества этих двух технологий, избежав недостатков с помощью специального сервиса KubeMQ, читайте в нашей новой статье.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
27 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Узнайте больше про Apache Kafka и другие технологии больших данных на наших практических курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
Источники

