
Мы уже рассказывали, как некоторые принципы Agile отражаются в Big Data системах. Сегодня рассмотрим это подробнее на примере коннекторов Кафка и KSQL – SQL-движка для Apache Kafka. Он который базируется на API клиентской библиотеки для разработки распределенных приложений с потоковыми данными Kafka Streams и позволяет обрабатывать данные в режиме реального времени с использованием SQL-операторов вместо Java-кода.
Падайте быстро, поднимайтесь еще быстрее c Kafka Connect
Напомним, Agile предполагает высокую скорость и частоту каждой итерации проекта, включая быструю реакцию на неудачи. Принцип непрерывной адаптации к изменяющимся обстоятельствам отражается в подходе «fail fast, learn faster»: падайте быстро, учитесь быстрее – не стоит бояться ошибок, следует оперативно их исправлять [1].
Этот принцип используется в среде коннекторов – Kafka Connect, которая позволяет связать Кафка с внешними источниками (хранилища документов и объектов, файлы, NoSQL и реляционные СУБД, очереди сообщений и пр.) через организацию потоковых конвейеров данных (data pipelines). В случае ошибок при передаче данных по причине несовпадения формата между источником и приемником, например, JSON вместо AVRO и наоборот, начиная с версии Кафка 2.0, Kafka Connect позволяет остановить обработку, как только обнаружен сбой. Для этого в конфигурационном файле коннектора по умолчанию задана настройка errors.tolerance = none [2]. Как это работает, мы рассматривали здесь на примере интеграции Кафка с NoSQL-СУБД Elasticsearch.
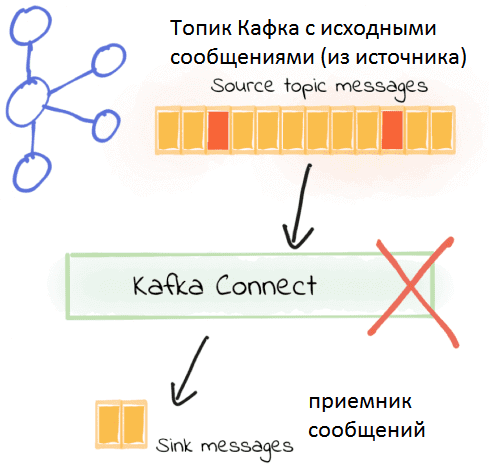
Бесперебойная поставка сообщений по Agile
С настройкой errors.tolerance связан еще один Agile-принцип, реализованный в Kafka Connect: удовлетворение клиента за счёт ранней и бесперебойной поставки ценного программного обеспечения [3]. В частности, при установке этого параметра errors.tolerance = all можно определить так называемую «мертвую очередь» (dead letter queues) – место, где будут сохраняться ошибочные сообщения, задав имя соответствующего топика errors.deadletterqueue.topic.name. При этом Connect продолжает отправку сообщений в соответствующие топики, складируя ошибочные отдельно в dead letter queues. Таким образом, корректные сообщения обрабатываются как обычно, и сам data pipeline не останавливается работать. Ошибочные сообщения потом можно проверить из «мертвой очереди», игнорируя или исправляя их по мере необходимости с целью повторной обработки [2].
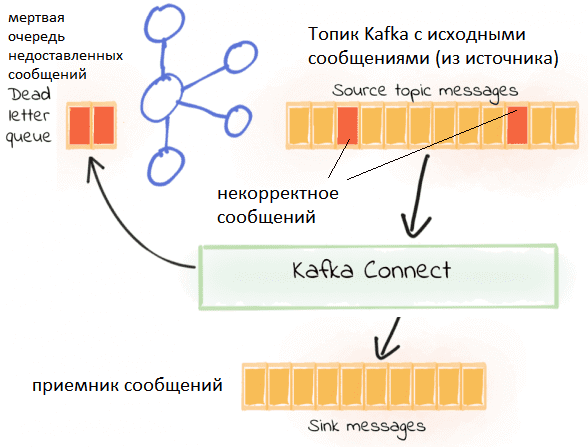
Сотрудничество и взаимодействие
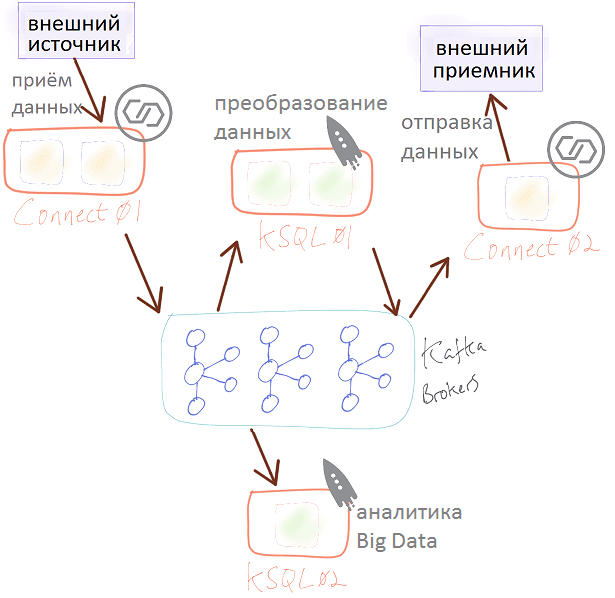
2 из 4-х основных идей Agile гласят «люди и взаимодействие важнее процессов и инструментов» и «сотрудничество с заказчиком важнее согласования условий контракта» [3]. Эти принципы отражаются в работе серверов Кафка, когда в рамках одной Big Data системы организуется взаимодействие Connect и KSQL. Например, есть пара кластеров Connect и KSQL. Кластеры Connect управляются отдельными командами: одна получает данные из источника, а другая принимает преобразованные данные и передает их в СУБД. KSQL используется для двух потоковых приложений [4]:
- одно из них берет загруженные данные и преобразует вложенные структуры в плоскую для потоковой передачи событий в базу данных;
- второе приложение KSQL используется для аналитики больших данных по мере их поступления.
В следующей статье мы продолжим говорить про Agile-принципы в Apache Kafka и рассмотрим особенности DveOps-подхода в KSQL и Connect. А как эффективно использовать компоненты Apache Kafka для потоковой обработки больших данных, вы узнаете на практических курсах по Кафка в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков Big Data) в Москве:
Источники
- https://agileinitiatives.com/fail-fast-learn-faster-innovate/
- https://www.confluent.io/blog/kafka-connect-deep-dive-error-handling-dead-letter-queues/
- https://ru.wikipedia.org/wiki/Гибкая_методология_разработки
- https://www.confluent.io/blog/dawn-of-kafka-devops-managing-multi-cluster-kafka-connect-and-ksql-with-confluent-control-center/

