
Недавно мы разбирали особенности интеграции Apache Kudu и Spark. В продолжение этой темы, сегодня поговорим про некоторые особенности выполнения SQL-операций с данными при интеграции этих Big Data фреймворков, а также рассмотрим пример записи данных в мульти-мастерный кластер Куду через Impala с помощью API Data Frame на PySpark.
Что приносит Kudu в Spark: 3 преимущества совместного использования
Напомним, Apache Kudu – это механизм хранения больших данных с открытым исходным кодом для экосистемы Hadoop, который обеспечивает высокоскоростную аналитику Big Data практически в режиме онлайн, соблюдая баланс между высокой пропускной способностью для объемных сканирований и низкой задержкой для произвольного доступа. Совмещая Spark и Kudu, можно создавать приложения, которые с помощью SQL запрашивают и анализируют постоянно изменяющиеся наборы данных. При этом производительность системы остается высокой на уровне основного формата больших данных, такого как Parquet, благодаря отказоустойчивой распределенной архитектуре Kudu и колоночному принципу хранения информации на диске.
В контексте этого отметим 3 наиболее существенных преимущества совместного использования Apache Kudu и Spark, которые были отмечены в видеозаписи доклада software-инженера компании Cloudera на ежегодной конференции Spark Summit Europe в 2016 году. Доклад назывался «Apache Kudu and Spark SQL for Fast Analytics on Fast Data» и был посвящен применению Apache Kudu и Spark SQL для быстрой аналитики быстро меняющихся данных. Некоторые аспекты этого доклада мы рассматривали здесь, на примере кейса кампании Xiaomi. Итак, объединение Kudu и Spark обеспечивает следующие возможности [1]:
- высочайшая скорость вставок и обновлений с минимальной задержкой аналогично производительности сканирования данных в формате Parquet;
- фильтрация данных с помощью предикатов для быстрого и эффективного сканирования;
- индексация по первичному ключу для быстрого поиска по lookup-таблицам, по скорости сравнимого с Parquet.
Формат Parquet не случайно выступает сравнительным эталоном: он демонстрирует лучшие показатели последовательного сканирования данных на HDFS, также как HBase показывает оптимальные результаты в операциях произвольного доступа к неструктурированным данным. Kudu находится между 2-мя этими движками хранения данных, обеспечивая оперативное последовательное сканирование и быстрый произвольный доступ. Подробный бенчмаркинговый тест, сравнивающий быстродействие Kudu и Impala на формате Parquet рассмотрен в источнике [2].
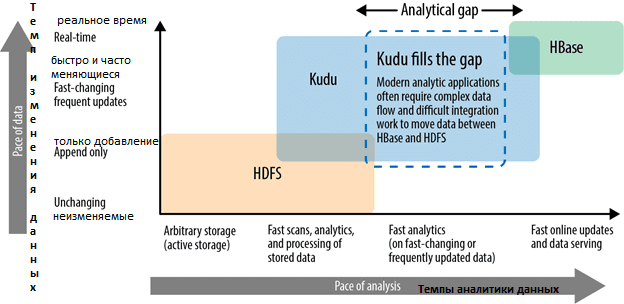
Возвращаясь к совместному использованию Spark SQL с Kudu, отметим, что эти фреймворки отлично согласуются в т.ч. потому, что NoSQL-СУБД Куду поддерживает строго типизированную табличную модель и прочие структуры данных, а также операции с ними [3]:
- операции создания и удаления (Create/Delete);
- структуры данных Spark RDD и DataFrame, о которых мы рассказывали здесь;
- операции чтения, вставки, обновления и удаления данных из Kudu;
- поддержка предикатов, таких как равно (=), больше чем (>), больше или равно (> =), меньше чем (<), меньше или равно (<=);
- отображение (маппирование) схем данных между Kudu и Spark SQL.
PySpark и 5 особенностей SQL-операций с данными
Spark поддерживает следующие операции над объектами Kudu DataFrame [3]:
- Вставка (INSERT), когда строки DataFrame вставляются в таблицу Kudu. Хотя API полностью поддерживает INSERT, его использование в Spark не рекомендуется, т.к. задачи Spark могут потребовать повторного выполнения. В этом случае уже вставленные строки могут быть запрошены для повторной вставки, что приведет к сбою, т.к. команда INSERT не позволит вставлять строки, если они уже существуют. Вместо этого рекомендуется использовать команду INSERT_IGNORE.
- INSERT-IGNORE позволяет вставить строки DataFrame в таблицу Kudu, игнорируя записи, которые уже существуют там.
- УДАЛИТЬ (DELETE) удаляет строки DataFrame из таблицы Kudu.
- Обновляемая вставка (UPSERT), которая обновляет строки DataFrame в таблице Kudu, если они там существуют, иначе выполняется простая вставка.
- Обновление (UPDATE), когда строки DataFrame просто обновляются в таблице Kudu
Для всех этих операций рекомендуется использовать KuduContext, хотя, многие из них также могут быть выполнены через API DataFrame. Подробные примеры кода SQL-запросов и инструкций через API DataFrame приведены в источнике [3].
Также стоит отметить, что PySpark, который позволяет разрабатывать Spark-приложения на языке Python, также поддерживает API DataFrame. Например, запись данных в кластер Kudu, который работает в мульти-мастерном режиме, на PySpark через Impala выглядит следующим образом [4]:
test_DF.write.format (‘org.apache.kudu.spark.kudu’). options (** {‘kudu.master’: ‘master1: port’, ‘kudu.master’: ‘master2: port’, ‘kudu .master ‘:’ master3: port ‘,’ kudu.table ‘:’ impala :: table_name ‘}). mode (“append”). save ()
Больше подробностей про применение Apache Spark, Kudu и других компонентов экосистемы Hadoop на практике для своих бизнес-задач вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Анализ данных с Apache Spark
- Cloudera Impala Data Analytics
- Интеграция Hadoop и NoSQL
- Hadoop для инженеров данных
Источники
- https://databricks.com/session/apache-kudu-and-spark-sql-for-fast-analytics-on-fast-data
- https://boristyukin.com/benchmarking-apache-kudu-vs-apache-impala/
- https://www.cnblogs.com/seaspring/p/6508413.html
- https://medium.com/@sciencecommitter/how-to-read-from-and-write-to-kudu-tables-in-pyspark-via-impala-c4334b98cf05

