Когда и зачем переходить от пакетной парадигмы обработки к потоковой, как это сделать с помощью микросервисной архитектуры, какие проблемы могут при этом возникнуть и что за решения позволят их избежать. А в качестве примеров инструментальных средств рассмотрим сервисы AWS, Apache AirFlow и Kafka.
От пакетов к потокам через микросервисы: архитектура конвейеров обработки данных
Примерно до 2010-хх годов для большинства проектов традиционно применялась пакетная парадигма обработки данных, когда они собирались за какой-то период времени и записывались в нужное место для последующего использования. Однако, современный бизнес требует более быстрых результатов. Например, вместо того, чтобы получать ежечасные пакеты данных из вышестоящего источника и ежедневно обрабатывать их, можно делать это быстрее, производя вычисления на лету. Для этого придется отказаться от пакетной парадигмы и перейти к потоковой, реализовать которую можно с помощью микросервисной архитектуры. Рассмотрим это на примере сервисов Amazon.
В пакетной обработке приходилось забирать файлы из озера данных или объектного хранилища, например, AWS S3 в конце дня из почасовых разделов и применять к ним требуемые преобразования. Далее нужно было добавить все необходимые разделы в соответствующую таблицу Glue, а также генерировать оператор создания для представления. Это можно делать динамически на тот случай, если есть дополнительные столбцы для добавления данных в зависимости от объекта загрузки. Реализовать это можно с помощью Apache AirFlow и AWS EMR.
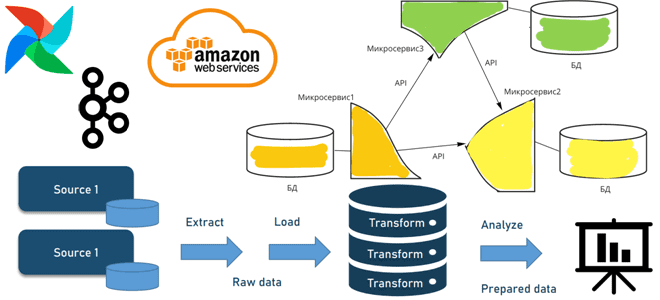
В потоковой парадигме не нужно ждать до конца дня, чтобы обработать данные, поскольку это можно делать по мере их поступления. Достаточно добавить уведомления корзины S3 для любых добавленных или удаленных файлов. Эти уведомления фильтруются в топик SNS, который подключен к очереди SQS, поскольку микросервис существует в отдельной учетной записи от самих данных. Микросервис существует в кластере ECS и выполняет необходимые преобразования для каждого файла по мере их прохождения.
Для недоставленных сообщений есть соответствующая DLQ-очередь (Dead-Letter Queue), настроенная для обработки любых файлов, которые изначально не проходят через очередь. Когда это происходит, запускается соответствующее оповещение, чтобы выяснить причину инцидента и исправить проблемы до новой попытки выполнить обработку данных. Для реализации повторной обработки данных нужно средство повторного запуска микросервиса с необходимыми параметрами. Для этого средства могут быть два способа ввода: попадание файла в DLQ или указание пользователем набора входов самому микросервису. В качестве реализации можно взять паттерн шлюза API или сделать это с помощью AirFlow, который будет запускать лямбда- функции посредством DAG через API-вызовы каждый раз, когда нужно повторно обработать сообщения. Лямбда-функции будут отправлять сообщения в соответствующую очередь воспроизведения SQS, которая запускает их повторную обработку.
Из-за отсутствия DAG, где можно сделать шаг, чтобы убедиться, что правильные разделы добавлены в таблицы Glue, а также создать соответствующее представление, рекомендуется создать ежедневное задание Databricks. Поскольку таблицы Glue не разделены по часам, что приведет к слишком большому количеству разделов, можно создать меньший DAG, чтобы просто обрабатывать создание представления. Это также может быть заданием Databricks.
Возвращаясь к микросервисной архитектуре, отметим, что их реализация на HTTP достаточно спорная идея. Поскольку микросервис реализует принцип единой ответственности и имеет изолированный контекст, можно столкнуться с проблемой синхронности HTTP-запросов. HTTP-запросы работают последовательно, если один этап не отвечает, весь запрос удерживается до тех пор, пока он не будет обработан. Получив сотни запросов, которые обрабатываются, вся система может выйти из строя или зависнуть, что называется каскадным сбоем. Например, третий запрос будет находится в состоянии обработки до завершения второго, что является проблемой использования HTTP в качестве бэкенда для микросервисов. Избежать этого поможет фреймворк обмена сообщениями типа Apache Kafka или JMS-брокеров, о чем мы рассказываем здесь.
Отметим возможные способы оповещения потребителей о доступности данных:
- файлы триггеров, например, S3Sensor для AirFlow. Это простое решение требует соответствующей инфраструктуры для обслуживания. Придется создать новую папку в AWS S3 для хранения триггеров или еще одну корзину. Также нужно убедиться, что все потребители имеют доступ к этому местоположению.
- Топик SNS или очередь SQS, предоставляемые сервисами Amazon. В конце обработки следует отправить сообщение в топик или очередь, а затем сообщить потребителям, которые подписаны на них, что данные готовы к использованию. С точки зрения инфраструктуры обслуживания по сравнению с предыдущим вариантом, она не не стала проще: топик или очередь должны быть созданы, а потребители должны быть подписаны на них. Кроме того, AirFlow предлагает датчик для SQS, но не для SNS, поэтому потребуется специальная реализация.
- Записи в специальные таблицы как сигнал о том, что обработка завершена. Следует убедиться, что схема для указанной таблицы охватывает все, что нужно (дата, количество записей, любые другие необходимые столбцы). В AirFlow есть SqlSensor, который поддерживает множество различных вариантов подключения в зависимости от того, где на самом деле хранятся данные. Это самое простое решение с точки зрения обслуживания. Получить доступ к таблице намного проще, чем настраивать политики AWS и постоянно поддерживать их.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

