В этой статье разберем кейс бразильской фудтех-компании Ifood по реализации микросервисной ML-системы на Apache Kafka и serverless NoSQL-СУБД DynamoDB с пропускной способностью миллиарды сообщений в секунду. Сложности масштабирования микросервисов и оперативное чтение данных из Feature Store с помощью библиотеки Sarama – Go-клиента для Apache Kafka.
Проблема микросервисов при множестве обращений к DynamoDB
Ifood — это бразильская компания по производству пищевых продуктов, которая доставляет более 1 миллиона заказов в день и ежегодно растет примерно на 110%. Обычно пиковые часы работы платформы приходятся на время обеда и ужина в будни, а также по выходным. Иногда например, из-за маркетинговых кампаний, нагрузка растет еще больше, достигая 2 миллионов запросов в минуту.
Платформа построена по микросервисной архитектуре. Один микросервис хранит метаданные клиентов (аккаунтов), и в часы пик он особенно востребован: к нему обращаются мобильные и веб-приложения, а также внутренние команды для получения данных о клиентах. Данные хранятся в единой таблице key-value NoSQL-СУБД DynamoDB с 1,3 миллиардами элементов объемом более 750 ГБ.
В базе данных эти метаданные разделены на разные контексты – пространства имен. У клиента (customer_id в качестве ключа раздела) может быть от одного до N пространств имен. Пространство имен является ключом сортировки, и каждое из них имеет фиксированную JSON-схему данных, которая определяется и проверяется перед вставкой.
Этот подход позволяет разделить чтение и запись, выполняемые разными подразделениями компании. Вставка делает Data Science команда, ежедневно экспортируя миллионы записей из своих внутренних инструментов в этот микросервис через API. Эти миллионы записей разделены на пакеты по примерно 500 элементов. Таким образом, в определенное время суток микросервис принимает миллионы вызовов с интервалом 10-20 минут для вставки данных в DynamoDB. Если пакетный API будет записывать их сразу в базу данных, могут возникнуть проблемы с масштабированием Dynamo и увеличится задержка отклика. Устранить это узкое место поможет запись данных непосредственно в базу, если элементы JSON-схемы соответствуют пространству имен, где они будут храниться. Это ответственность микросервиса.
API получает партию элементов и размещает их в распределенной системе массового обслуживания публикации и подписки SNS/SQS, которая используется другой частью приложения, проверяющей элемент и сохраняющей его в Dynamo. При таком подходе конечная точка, которая получает пакет элементов, может отвечать очень быстро, позволяя записывать данные независимо от сбоев HTTP-соединения с DynamoDB. Также можно контролировать скорость процесса чтения данных из SQS и записи их в DynamoDB, управляя потребителями.
Вне этого процесса метаданные аккаунтов также ежедневно вызываются другим сервисом, когда платформа получает заказ, для обновления информации о нем. Учитывая, что Ifood выполняет более 1 миллиона заказов в день, нагрузка на микросервисы очень велика. При этом 95% нагрузки приходится на вызовы API для чтения данных, что упрощает масштабирование системы. К примеру, для этого можно использоваться DAX в качестве встроенного кэша для DynamoDB.
Возвращаясь к микросервису метаданных аккаунтов, отметим, что он нужен для персонализации данных о клиентах Ifood, обрабатывая их предпочтения и особенности пользовательского поведения, например, счетчик суммы заказов, ТОП-3 любимых блюда, любимые рестораны и сегмент целевой аудитории.
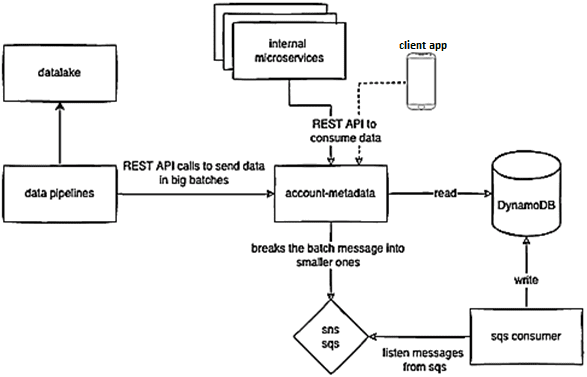
Конвейер Data Science команды экспортирует данные из корпоративного озера (Data Lake), обрабатывает их с помощью Databricks и Airflow, а затем отправляет их в метаданные аккаунтов. Этот data pipeline состоит из множества шагов и может очень легко выйти из строя. Чтобы повысить надежность, необходимо изменение инфраструктуры для приема сотен миллионов записей в день.
Feature Store для ML-системы на Apache Kafka
За персонализацию отвечают алгоритмы машинного обучения, которые обрабатывают множество данных о пользовательском поведении, называемых фичами (feature). Для хранения этих фич используются специальные хранилища — Feature Store, о чем мы писали здесь. Можно сказать, то Feature Store — это отличный способ легко предоставлять и обмениваться данными для расширения возможностей ML-приложений, обучения моделей и прогнозирования в реальном времени. Хранилище фичей считывает данные из топика Kafka, корпоративного озера или DWH, агрегирует их, выполняет какую-то обработку или вычисление, а затем экспортирует результаты в место назначения: API, СУБД, топик Kafka и пр. При этом можно использовать Feature Store как централизованный инструмент для задач, напрямую не связанных с ML-приложениями. Именно этот сценарий и реализован в Ifood, чтобы заменить сложный и хрупкий конвейер обработки данных на надежный и прочный механизм, получая фичи из топика Kafka.
Но экспорт даже 20 фич из Feature Store по каждому клиенту Ifood, которых около 60 миллионов предполагает экспорт сообщения. А если количество фич возрастет до 30-40, понадобится потреблять около 1,5 миллиардов сообщений из Kafka в день. Схема данных выглядит так:
{
account_id: string
feature_name: string
feature_value: string
namespace: string
timestamp: int
}
Зная схему данных, можно создать потребителя, который будет считывать данные из Kafka и сохранять фичи в DynamoDB. В таблице Dynamo поле account_id используется в качестве ключа раздела с сортировкой по пространству имен. Пространство имен разделяет метаданные аккаунта по разным контекстам.
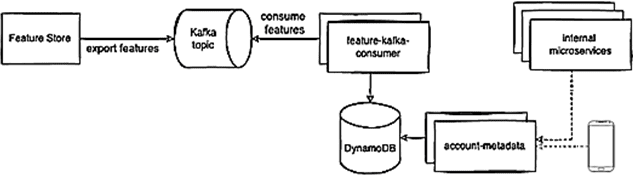
Первая версия потребителя была написана на Java, но работала медленно. Повысить скорость помогла реализация с использованием Go-клиента для Apache Kafka, библиотеки Sarama, позволяющая обрабатывать 1 миллион событий в минуту или 20 тысяч фич в секунду для каждого потребителя. Такой объем данных сильно увеличил количество операций записи в DynamoDB, поэтому дата-инженерам Ifood пришлось масштабировать эту NoSQL-СУБД до 50 КБ единиц записи в секунду.
Несмотря на высокую пропускную способности системы, тестирование показало высокие накладные расходы на базу данных из-за того, что операция записи выполняется для каждого сообщения в DynamoDB, при том что есть несколько сообщений от одного и того же account_id в топике Kafka. Напомним, поле account_id используется в качестве ключа раздела. Логично, что сообщения с одним и тем же account_id будут использоваться одним и тем же потребителем. Для этого можно создать своего рода буфер в памяти, чтобы агрегировать и объединить события одного и того же account_id, а также пространства имен вместе и за раз записать их в DynamoDB.
Чтобы реализовать эту идею, был изменен потребитель Kafka, получающий данные в пакетном режиме: увеличено значение параметра fetch.min.bytes и количество сообщений. Теперь вместо того, чтобы получать и обрабатывать по одному сообщению за раз, можно получать сразу 1000 сообщений, где ключом является account_id, а значением – список фич. Далее выполняется всего одно сохранение в DynamoDB для каждого account_id. Так удалось в 4 раза сократить количество операций записи в NoSQL-базу данных.
Узнайте больше подробностей про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

