Что и насколько часто меняется в системах машинного обучения, почему необходимо отслеживать эти изменения и как MLOps помогает справиться с управлением ML-моделями, данными, кодом и инфраструктурой развертывания. Почему стек технологий MLOps такой разношерстный и какие инструменты выбирать для практического использования.
MLOps для решения дрейфа данных и других проблем ML-систем
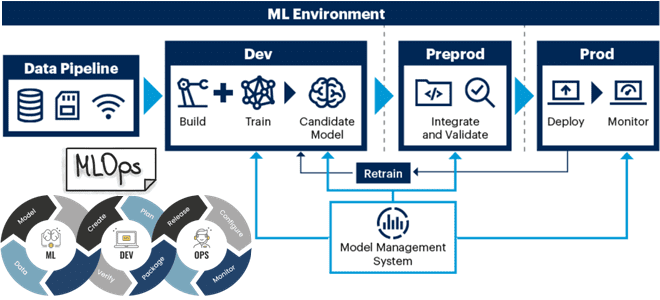
Машинное обучение все еще является относительно новой дисциплиной, где пока отсутствуют стандарты на ряд процессов и инструментов. Помимо программного кода, ML-системы включают сами алгоритмы Machine Learning и данные. Управлять этим широким набором объектов с «зоопарком» инструментальных средств – не самая простая задача. Помочь в этом может MLOps-концепция, которая сочетает машинное обучение, DevOps и управление данными для обеспечения надежного и эффективного цикла разработки, развертывания и обслуживания ML-систем в производстве согласно потребностям бизнеса.
В частности, MLOps рассматривает вопросы управления ML-моделью как набор принципов и практик, позволяющий организации контролировать доступ, внедрять политики и отслеживать активность алгоритмов машинного обучения. Это включает настройку правил и элементов управления для ML-моделей в производстве, от контроля доступа, тестирования, валидации и мониторинг результатов моделирования, а также поддержание актуальности документации и версионирование. MLOps также обеспечивает контроль версий в конвейерах программного кода и данных.
Непрерывный мониторинг ML-моделей считается первым и самым важным шагом в управлении ими. Отслеживание выходных данных модели позволяет обнаруживать и исправлять смещения. Это важно, потому что модели, запрограммированные на обучение по ходу дела, могут случайно стать необъективными или дрейфовать, что может привести к неточным результатам. Актуальная документация позволяет отслеживать и фиксировать все входные данные, которые могут повлиять на результаты модели.
MLOps добавляет к DevOps управление качеством данных, выходными данными моделирования и управление гиперпараметрами ML-модели. Это унифицирует методы совместной работы и общения между дата-инженерами, аналитиками и ML-специалистами c операционными командами для управления жизненным циклом систем машинного обучения в производственной среде. Такое сотрудничество дает огромные преимущества для согласованного управления, автоматизации и масштабирования разработки ML-приложений, а также запуска их в production.
Управление становится особенно важным в моделях, связанных с риском, например, финтех- или медтех-проекты, где очень важно понимать входные данные, чтобы выявлять и исправлять в алгоритмах Machine Learning любые предубеждения или неправильное обучение. Управление моделями позволяет проверять и тестировать их на скорость, точность и дрейф во время работы в производственной среде. Как это сделать, мы подробно разбираем в новой статье.
Обнаружение дрейфа — важный аспект мониторинга работоспособности развернутых ML-моделей, о чем мы упоминали в этой статье. Дрейф — это изменение сущности по отношению к ее базовой линии. В машинном обучении выделяют 2 типа дрейфа:
- Дрейф данных, когда производственные данные радикально отличаются от тех, на которых модель обучалась перед ее развертыванием в производственной среде. Такое изменение чаще всего случается из-за изменения поведения исследуемых объектов в реальном мире с течением времени или изменения меры.
- Дрейф модели — снижение ее прогностической способности из-за изменения взаимосвязи между зависимыми и независимыми переменными. В прогностической аналитике или машинном обучении такой дрейф означает, что статистические свойства целевой переменной, которую модель пытается предсказать, изменяются с течением времени непредвиденным образом. Чаще всего это случается из-за непредсказуемого изменения внешних условий, например, пандемия, стихийные бедствия и пр. Это вызывает проблему, поскольку прогноз становится менее точным с течением времени.
Если дрейф данных не будет обнаружен до их использования в прогнозах, результат ML-моделирования будет ошибочным. Как обнаружить дрейф данных с помощью Python-библиотеки Evidently, читайте в нашей новой статье. Дрейф ML-модели также может случиться из-за дрейфа данных или повторяющихся/циклических колебаний данных с течением времени. Таким образом, качество входных данных является критическим фактором в управлении ML-продуктами и требует большого внимания к управлению сопутствующими рисками.
Из-за роста данных вместе со снижением стоимости процессов и средств их обработки, концепция MLOps сегодня весьма востребована, т.к. она направлена на решение следующих проблем:
- зависимость от данных, которые непрерывно меняются с течением времени и могут стать причиной некорректной работы прежних алгоритмов ML-модели из-за неполного соответствия новым условиям;
- отсутствие общих средств коммуникации в команде разнопрофильных специалистов;
- недостаток у ML-специалистов и дата-аналитиков компетенций в разработке оптимального программного кода и развертывании его в production.
Традиционные подходы к решению этих проблем требуют значительных усилий для совместной работы и коммуникации, дополнительных ресурсов и времени, увеличивая сроки и стоимость достижения бизнес-цели. Практическое внедрение MLOps дает следующие преимущества:
- автоматическое переобучение ML-моделей в связи с изменением данных. Благодаря автоматизации легко обнаруживать дрейфы во входных данных и моделировать результаты, сокращая сопутствующие расходы.
- ускорение циклов разработки и более быстрый выпуск продукта на рынок, т.е. сокращение важной бизнес-метрики TTM – Time To Market;
- улучшение сотрудничества между командами на всех уровнях технической экспертизы;
- повышение надежности, производительности, масштабируемости и безопасности ML-систем;
- оптимизация общих операционных и управленческих процессов;
- повышение эффективности инвестиций, т.е. рост метрики ROI для ML-проектов.
Однако, при практической реализации идей MLOps возникают определенные сложности, о которых мы ранее писали здесь и здесь. С помощью каких инструментальных средств их можно решить, рассмотрим далее.
Инфраструктура и инструменты
Как мы уже отметили, программный код – это не единственный компонент ML-системы. В реальных продуктах есть также конфигурация, автоматизация, сбор и валидация данных, тестирование и отладка алгоритмов, управление ресурсами, процессами и метаданными, а также мониторинг и обеспечение бесперебойной работы обслуживающей инфраструктуры. Поскольку MLOps как концепция появился совсем недавно, ландшафт ее технологий часто меняется. Кроме того, область действия каждого инструмента может охватывать различные компоненты процессов жизненного цикла ML-систем. Поэтому следует внимательно выбирать средство для своего варианта использования с учетом масштаба проекта, уровня управленческой зрелости команды и инфраструктурного окружения. Примером стека технологий могут быть перечисленные ниже инструменты с открытым исходным кодом.
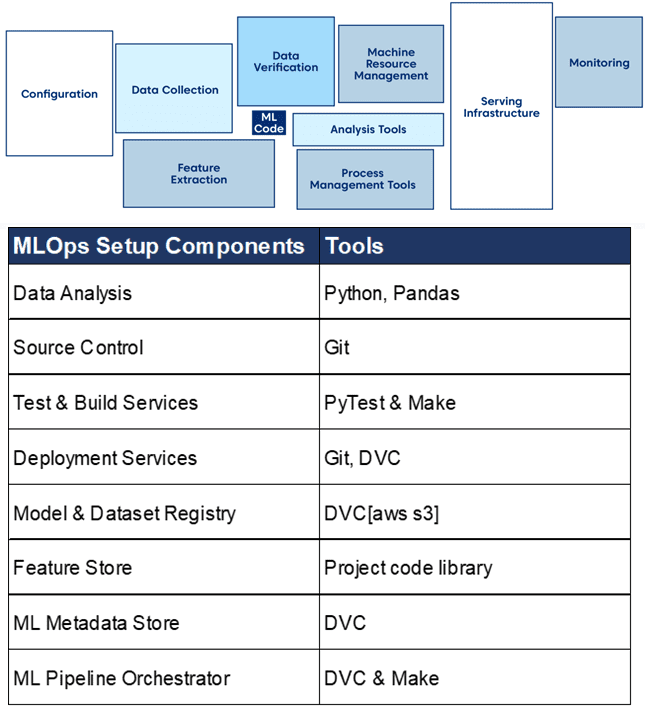
Примечательно, что идеи MLOps становятся более популярными и меняют сам инструментальный стек. В частности, в существующих технологиях появляются новые фреймворки и библиотеки, обеспечивающие MLOps-возможности. Например, Kedro — платформа Python с открытым исходным кодом для создания воспроизводимого, поддерживаемого и модульного кода для обработки данных. Kedro заимствует концепции из разработки ПО и применяет их к коду ML-алгоритма, включая модульность, разделение задач и управление версиями. С Kedro можно создавать модели машинного обучения, реализуя конвейеры предварительной обработки данных и моделирования. А запись процесса и шагов самих конвейеров обеспечит воспроизводимость и ремонтопригодность всей системы Machine Learning. Для более тяжеловесных случаев аналогичные примеры с организацией процесса разработки ML-приложения согласно принципам MLOps на Apache Spark, AirFlow и Kubernetes мы разбирали здесь и здесь. А о том, как MLOps-идеи помогают реализовать концепции федеративного машинного обучения, читайте в нашей новой статье.
Как применить лучшие практики MLOps в реальных проектах для эффективной аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

