Поскольку разработка и развертывание ML-систем отличаются от традиционного ПО, о чем мы писали здесь и здесь, процесс тестирования модели машинного обучения тоже имеет свою специфику, которую учитывает концепция MLOps. Читайте далее, что и как тестировать при разработке систем Machine Learning, а также при чем здесь подход Arrange-Act-Assert.
MLOps и тестирование систем машинного обучения
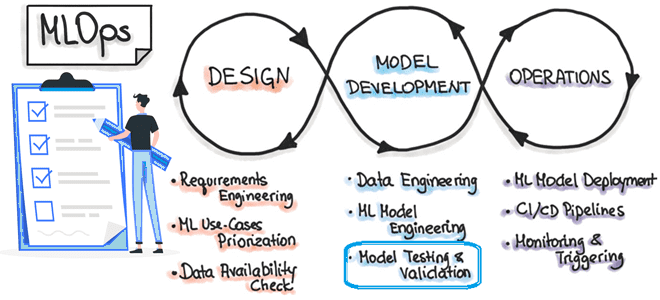
Напомним, концепция MLOps стремится учесть специфику разработки, тестирования, развертывания и эксплуатации систем машинного обучения, интегрировав ее с лучшими практиками программной инженерии. В частности, MLOps поможет избежать «технического долга» в ИИ-приложениях. Задача команды MLOps — автоматизировать развертывание ML-моделей в основной программной системе или в качестве сервисного компонента. Это означает автоматизацию всех этапов рабочего процесса машинного обучения без какого-либо ручного вмешательства. Триггерами для автоматизированного обучения и развертывания модели могут быть события календаря или мониторинга, поступление новых сообщений, изменения данных, кода ML-алгоритма и/или кода приложения.
Таким образом, при внедрении MLOps можно выделить три уровня автоматизации по возрастающей сложности:
- Ручной процесс обработки всех данных и кода — каждый шаг в каждом конвейере, например, подготовка и проверка датасета, обучение и тестирование модели, выполняются вручную. Чаще всего здесь применяются инструменты быстрой разработки приложений (RAD) типа Jupyter Notebooks и Cron/AirFlow для запуска скриптов по простому расписанию.
- Автоматизация ML-конвейера с непрерывным обучением модели и перезапуском при появлении новых данных. Этот уровень автоматизации также включает этапы проверки данных и модели.
- Автоматизация конвейера непрерывной интеграции и поставки (CI/CD) для быстрого и надежного развертывания модели машинного обучения в производственной среде (production). Здесь автоматически создаются, тестируются и развертываются компоненты данных, модели Machine Learning и ML-конвейеры.
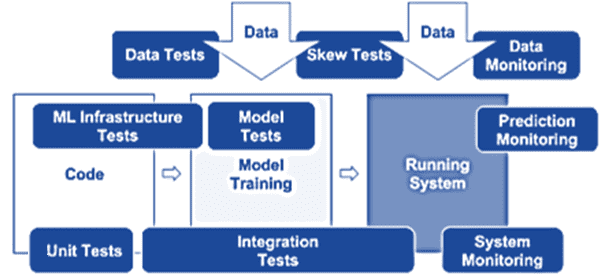
Автоматизированное тестирование помогает обнаруживать проблемы быстро и на ранних стадиях, позволяя быстро исправлять ошибки и учиться на них. Поскольку сам ML-конвейер включает разработку данных, модели машинного обучения и приложения, в тестирования систем машинного обучения тоже можно выделить 3 категории тестов: для фичей и данных, разработки моделей и инфраструктуры ML. Что и как проверять в каждой категории тестов, мы рассмотрим далее, но сперва вспомним основы тестирования ПО.
Основы тестирования ПО: типы тестов
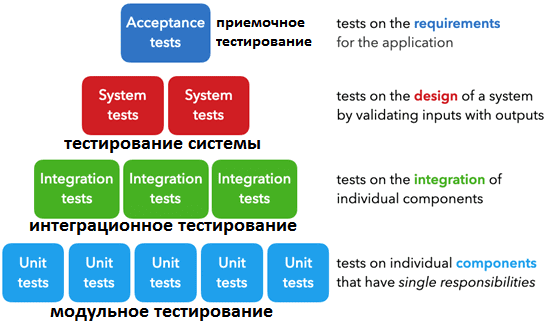
В программной инженерии выделяют пять основных типов тестов, которые используются на разных этапах цикла разработки ПО:
- модульные тесты для отдельных компонентов, каждый из которых имеет одну область ответственности и дает один конечный результат, например, функция фильтрации списка. Подробнее про модульное тестирование читайте в нашей новой статье на примере проверки качества Kafka-приложений.
- интеграционные тесты для комбинированной проверки совокупной работы нескольких отдельных компонентов, например, обработка данных. Про инструменты интеграционного тестирования Kafka-приложений мы рассказываем здесь.
- системные тесты для проверки дизайна системы в целом через сопоставление ожидаемых результатов с входными данными;
- приемочные тесты для проверки выполнения требований, указанных в критериях приемки, обычно называемые пользовательскими приемочными тестами (UAT);
- регрессионные тесты для проверки ранее известных ошибок, чтобы убедиться, что новые изменения не вызывают их повторно.
При разработке тестов рекомендуется использовать подход 3А (Arrange-Act-Assert), который упорядочивает входы, действия и результаты:
- Arrange – настроить различные входы для тестирования;
- Act – применить входные данные к тестируемому компоненту;
- Assert – подтвердить получение ожидаемого результата.
К примеру, в Python есть много инструментов для тестирования: unittest, pytest и пр., которые позволяют реализовывать тесты, придерживаясь описанной выше структуры 3А. Они предлагают множество встроенных возможностей (параметризация, фильтры и т.д.) для масштабной проверки различных условий. Многие MLOps-фреймворки, такие как MLFlow, H2O и пр. поддерживают различные виды и категории тестов, о которых мы поговорим далее.
Тестирование фичей и данных
Прежде всего необходима валидация данных, включая проверку схемы. Чтобы построить схему данных, важную с точки зрения предметной области, пригодится статистика обучающего датасета. Эту схему можно использовать в качестве определения ожидания или семантической роли для входных данных на этапах обучения и обслуживания.
Валидация фичей нужна, чтобы проверить их важность с точки зрения бизнеса, например, повышают ли новые фичи точность прогноза ML-модели. Для этого можно вычислить коэффициент корреляции в столбцах признаков, обучить модель с одной или двумя фичами и сравнить результаты, измерив зависимости данных, задержку вывода и использование памяти. По результатам тестирования следует исключить неважные, неиспользуемые и/или устаревшие фичи, задокументировав внесенные изменения.
Тесты разработки моделей Machine Learning
Тестирование ML-моделей включает процедуры, которые проверяют, что алгоритмы принимают решения, соответствующие бизнес-целям. Это означает, что показатели потерь алгоритма ML (MSE, log-loss и пр.) должны коррелировать с показателями влияния на бизнес (доход, вовлеченность пользователей и т. д.). Измерить взаимосвязь между показателями потерь и показателями воздействия можно измерить в ходе мелкомасштабного A/B-тестирования с использованием преднамеренно ухудшенной модели.
Также полезно выполнить тест на устаревание модели. Модель Machine Learning считается устаревшей, если она не содержит актуальных данных и/или не удовлетворяет требованиям по влиянию на бизнес. Здесь поможет эксперимент A/B-тестирования с устаревшими моделями, чтобы понять, насколько часто следует переобучать ML-алгоритмы. Целесообразно оценить стоимость более сложных моделей машинного обучения, сравнив производительность, например, глубокой нейросети с простой линейной регрессией.
Для проверки производительности модели рекомендуется разделить команды и процедуры, собирающие обучающие и тестовые данные, чтобы удалить зависимости и избежать распространения ложной методологии из обучающего набора в тестовый набор. Для этого нужен дополнительный тестовый датасет, который не пересекается с обучающей и валидационной выборками. Использовать этот тестовый датасет следует только для окончательной оценки.
Чтобы оценить непредвзятость модели, необходимо собрать как можно больше данных, включающих потенциально недопредставленные категории, дополнительно проверив входные фичи. Здесь подойдет простое модульное тестирование для создания любых фич, обучения и тестирования ML-модели. Подробнее об этом читайте в нашей новой статье.
Тесты ML-инфраструктуры
Обучение ML-моделей должно быть воспроизводимым, т.е. на одних и тех же данных должно давать идентичные результаты. Различное тестирование моделей машинного обучения основано на детерминированном обучении, чего трудно достичь из-за невыпуклости алгоритмов машинного обучения, генерации случайных начальных чисел или распределенного обучения модели машинного обучения.
Сперва необходимо определить недетерминированные части в кодовой базе обучения модели и свести к минимуму недетерминированность. Затем проверить стресс-тестирование с использованием ML API. Провести модульные тесты для случайной генерации входных данных и обучения модели одному шагу оптимизации, например, градиентный спуск.
Следует выполнить крэш-тесты для обучения модели, которая должна восстанавливаться из контрольной точки после сбоя в середине обучения. Проверив алгоритмическую правильность, можно переходить к следующему действию — модульному тестированию, которое предназначено не для завершения обучения ML-модели, а для ее итерационной тренировки и снижения потерь. Рекомендуется избегать тестирования различий с ранее созданными моделями, поскольку такие тесты сложно поддерживать.
Наконец, весь ML-конвейер должен пройти интеграционное тестирование через полностью автоматизированный тест, который регулярно запускает его. Тест должен подтвердить, что данные и код успешно завершают каждый этап обучения, а итоговая ML-модель работает так, как ожидалось. Все интеграционные тесты должны быть выполнены до того, как модель Machine Learning попадет в производственную среду. После запуска модели в production и перед ее обслуживанием, модель следует проверить, установив порог, чтобы проверить ухудшение качества по разным версиям валидационного датасета. Также необходимо проверить, что модель машинного обучения успешно загружается в рабочую среду, а прогноз на основе реальных данных генерируется должным образом.
По сути, MLOps-инженер должен убедиться, что модель в обучающей среде дает тот же результат, что и в реальной, оценив разницу между показателями по фактическими и прогнозными данными. Хотя эта разница может быть вызвана чувствительностью некоторых фич ко времени, ее следует избегать. В идеале применение модели Machine Learning к обучающей и реальной выборке должно давать один и тот же прогноз, а большая разница чаще всего указывает на инженерную ошибку.
Узнайте, как внедрить лучшие практики MLOps с Apache Spark и другими инструментами аналитики больших данных, на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://sakshamgulati123.medium.com/overview-of-testing-in-mlops-abc5fdcff785
- https://medium.com/swlh/productionizing-machine-learning-models-bb7f018f8122
- https://github.com/visenger/awesome-mlops

