
В этой статье рассмотрим, как сделать SQL-запросы к колоночному хранилищу больших данных с поддержкой ACID-транзакций Delta Lake еще быстрее с помощью Apache Presto. Читайте далее про синергию совместного использования Apache Spark и Presto в Delta Lake для ускорения OLAP-процессов при работе с Big Data.
Еще раз об OLAP: схема звезды для BI-отчетов по Big Data
Рассмотрим типичную BI-задачу, когда по продажам товаров разных брендов и категорий необходимо генерировать сложные агрегированные отчеты. Данные структурированы по столбцам Дата (Date), Бренд (Brand), Категория (Category), Продукт (Product) и Продажа (Sale). Классический подход к моделированию многомерных данных, часто используемый при работе с КХД (DWH, Data WareHouse), предполагает создание таблиц измерений и фактов, где хранятся ключи. В рассматриваемом примере по схеме «звезда» таблицами измерений (Dim, Dimension) могут быть таблицы с датами (Dim Date), категориями (Dim Category) и пр., а таблицей фактов – продажи (Sale). Таким образом, таблица фактов (центр звезды) содержит агрегированные данные для составления отчетов, а денормализованные таблицы измерений (лучи) описывают хранимые данные. Это позволяет запустить процессы аналитической обработки данных OLAP (Online analytical processing), чтобы свернуть хранилище в кубы с предварительной агрегацией для расчета сложных многомерных показателей. Упростить этот процесс, одновременно ускорив работу с большими данными, поможет создания столбцового предварительно агрегированного набора данных с одной таблицей и расширения его в зависимости от потребностей. Как это реализовать с помощью SQL-механизмов Apache Spark и Presto, а также колоночного и быстрого колоночного хранилища Delta Lake, мы рассмотрим далее.
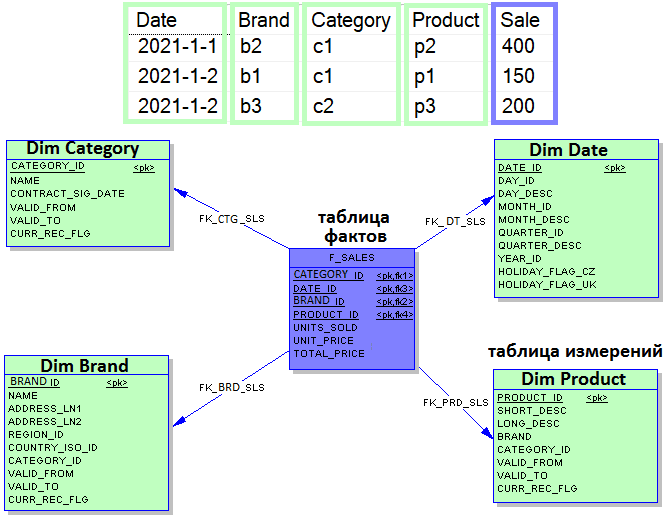
SQL-агрегация данных в Delta Lake с Apache Spark и Presto
Обеспечить максимально быстрое и гибкое выполнение аналитических запросов поможет SQL-агрегация данных GROUPING SET, которая позволяет получить результат в виде одной объединенной таблицы, созданной разными группами из целого датасета. В рассматриваемом примере с колонками {Date, Brand}, {Brand, Category} и {Category} это будет выглядеть следующим образом [1]:
SELECT Date, Brand, Category, SUM(Sale) AS Sum_Sale FROM data GROUP BY GROUPING SETS ( (Date, Brand), (Brand, Category), (Category) )
Далее можно отфильтровать результат и получить другой отчет из этого же набора данных. Благодаря колоночной структуре Delta Lake хранение таких данных более эффективно и имеет меньший размер по сравнению со строковыми СУБД.
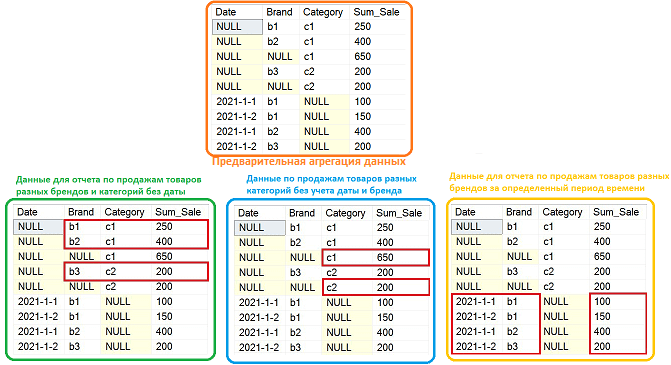
Предварительная агрегация данных, хранящихся в Delta Lake, с помощью Spark SQL будет выглядеть следующим образом:
df = sparkSession.read.format("delta") \
.load(read_path) \ --or anywhere else
.select(col('data.*'))
df.persist()
df.createOrReplaceTempView("dataset")
result = sparkSession.sql("""
SELECT Date, Brand, Category, SUM(Sale) AS Sum_Sale
FROM dataset
GROUP BY GROUPING SETS (
(Date, Brand),
(Brand, Category),
(Category)
)
""")
Запись результатов в Delta Lake на PySpark:
result.write.format('delta').mode("overwrite") \ .save(write_path)
Увеличить скорость выполнения SQL-запросов поможет Apache Presto, который просто запрашивает данные, без их копирования или перемещения. Presto оптимизирован именно под SQL-запросы из нескольких из нескольких источников, причем не только реляционных СУБД, но и NoSQL. Таким образом, можно сказать, что Apache Presto – это механизм интерактивного выполнения распределенных параллельных аналитических запросов, оптимизированный для малой задержки. Максимальные результаты Apache Presto показывает на данных, которые уже подготовлены для структурированных запросов [2], т.е. как в рассматриваемом примере.
Чтобы работать с Presto в Delta Lake следует создать внешние Hive-таблицы. Напомним, высокая скорость аналитики больших данных в Delta Lake обеспечивается в т.ч. благодаря тому, данные представлены в виде Hive-таблиц.
sparkSession.sql("""GENERATE symlink_format_manifest FOR TABLE
delta.`{}`""".format(
table_path))
ddl = """CREATE EXTERNAL TABLE if not exists {}({})
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '{}/_symlink_format_manifest'""" \
.format(table_name, col_name_type, table_path)
sparkSession.sql(ddl)
В результате даже сложный аналитический SQL-запрос к Delta Lake с Apache Presto будет выглядеть очень просто. Например, требуется получить данные о продажах товаров двух категорий с незаданными датами и брендами [1]:
SELECT Category, Sum_Sale FROM result WHERE Category IS NOT NULL AND Brand IS NULL AND Date IS NULL
Таким образом, рассмотренный подход объединяет скорость Apache Spark для вычислений и мощность Delta Lake в качестве колоночного хранилища Big Data с гибкостью SQL-движка Presto для ускорения OLAP-отчетов по большим данным с помощью их предварительной агрегации. Это существенно облегчает работу аналитика данных (Data Analyst) по поиску полезных для бизнеса сведений в огромных объемах информации, не налагая чрезмерной нагрузки на дата-инженера. А как сократить стоимость подобной OLAP-системы, развернутой на Delta Lake в облаке AWS, мы рассмотрим завтра. О другом кейсе построения системы аналитики больших данных для мониторинга финансовых транзакций в реальном времени на базе облачного Delta Lake и конвейера распределенных приложений Apache Kafka, Spark Structured Streaming и других технологий Big Data читайте в нашей новой статье.
Освоить эти и другие инструменты аналитики больших данных в экосистеме Apache Hadoop вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

