Какие бывают режимы вывода в структурированной потоковой передаче Spark, чем они отличаются и как их использовать на практике: разбираемся на практическом примере. Краткий ликбез по output modes в Apache Spark Structured Streaming для обучения дата-инженеров и разработчиков распределенных приложений.
Что такое режимы вывода в Apache Spark Structured Streaming
Apache Spark Structured Streaming позволяет выполнять потоковую обработку данных, поступающих из таких источников, как Kafka, и отправлять их в различные приемники: файловая система, СУБД и пр. Режим вывода определяет, как данные обрабатываются и помещаются в приемник. После определения окончательного результата DataFrame/Dataset следует начать вычисление потоковой передачи. Для этого нужно использовать DataStreamWriter, возвращаемые через метод Dataset.writeStream(). В этом интерфейсе нужно указать одно или несколько значений:
- подробная информация о выходном приемнике (формат данных, местоположение и пр.);
- сам режим вывода, т.е. что записывается в выходной приемник;
- уникальное имя запроса – опционально, нужно для идентификации;
- интервал срабатывания — если он не указан, система проверит наличие новых данных, как только завершится предыдущая обработка. Если время триггера пропущено из-за того, что предыдущая обработка не была завершена, система немедленно инициирует обработку.
- расположение контрольной точки, куда система будет записывать всю информацию о контрольной точке для некоторых выходных приемников, где может быть гарантирована сквозная отказоустойчивость. Это должен быть каталог в отказоустойчивой файловой системе, совместимой с Hadoop
Анализ данных с Apache Spark
Код курса
SPARK
Ближайшая дата курса
13 мая, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
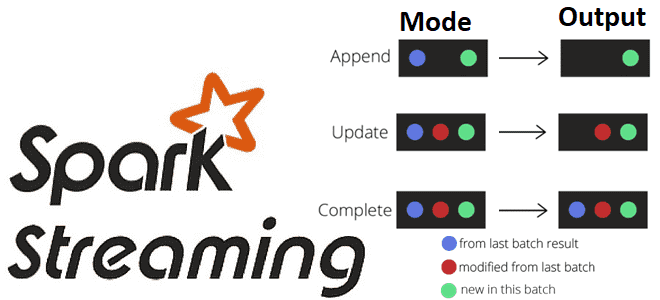
Существует несколько типов режимов вывода:
- Append — режим добавления (по умолчанию), при котором в приемник будут выводиться только новые строки, добавленные в таблицу результатов с момента последнего триггера. Это поддерживается только для тех запросов, где строки, добавленные в таблицу результатов, никогда не изменяются. Этот режим гарантирует, что каждая строка будет выведена только один раз при условии отказоустойчивого приемника. Например, запросы, где есть только выражения select, where, map, flatMap, filter, join, и т.д. будут поддерживать режим добавления. Кстати, именно этот режим поддерживается для stateful-оераций в Apache Spark 3.4.0, что мы рассматриваем в новой статье.
- Complete — полный режим — вся таблица результатов будет выводиться в приемник после каждого триггера. Это поддерживается для запросов агрегации.
- Update — режим обновления, доступный в Spark с версии 2.1.1, когда в приемник будут выводиться только те строки в таблице результатов, которые были обновлены с момента последнего триггера.
Потоковая обработка в Apache Spark
Код курса
SPOT
Ближайшая дата курса
16 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
В Spark Structured Streaming различные типы потоковых запросов поддерживают разные режимы вывода:
- Запросы с агрегацией. Запросы с агрегацией по времени события с водяным знаком поддерживают режимы вывода Append, Update и Complete. Режим добавления использует водяной знак для удаления старого состояния агрегации. Но вывод оконной агрегации задерживается до позднего порога, указанного в функции withWatermark(), поскольку по семантике этих режимов строки могут быть добавлены в таблицу результатов только один раз после их завершения, т. е. после пересечения водяного знака. Режим обновления использует водяной знак для удаления старого состояния агрегации. Полный режим не удаляет старое состояние агрегации, поскольку по определению этот режим сохраняет все данные в таблице результатов. Другие запросы с агрегацией, где водяной знак не определен, не поддерживают режим добавления, так как агрегаты могут обновляться, что нарушает семантику этого режима.
- Запросы с mapGroupsWithState поддерживают только режим обновления, а агрегации здесь не разрешены.
- Запросы с flatMapGroupsWithState в режиме операций добавления поддерживают Append с разрешенными агрегациями после flatMapGroupsWithState. В режиме операций обновлении (Update) агрегации с flatMapGroupsWithState не разрешены.
- Запросы с соединениями таблиц (JOIN) пока поддерживают только режим Append, а Update и Complete еще нет.
- Остальные запросы поддерживают режимы добавления и обновления, а Complete – нет, так как невозможно сохранить все неагрегированные данные в таблице результатов.
Задать режим вывода можно в интерфейсе датафрейма writeStream, например:
dF.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
Чтобы лучше понять принципы работы режимов вывода в Apache Spark Structured Streaming, рассмотрим их далее на практических примерах. Перед этим напомним, что хотя Spark Structured Streaming называется потоковой передачей, обработка данных ведется в микропакетах.
Режим добавления
Этот режим вывода используется по умолчанию и включает запись в приемник только новых входящих данных. Его можно применять, когда требуется вставить только новые данные, но не обновлять предыдущее состояние данных. Append mode не поддерживает операции агрегирования, так как они зависит от старых данных.
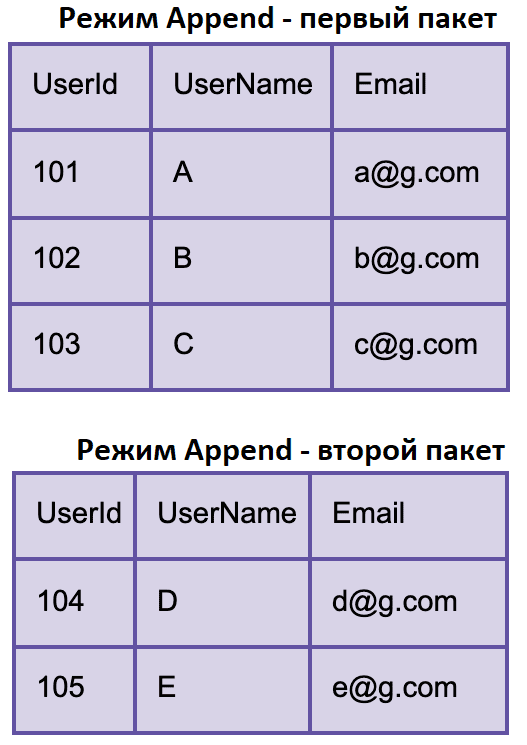
Например, необходимо передать регистрационные данные пользователей. Предположим, каждый раз, когда пользователь регистрируется на веб-сайте, это событие отправляется в Apache Kafka. И это событие считывается потоком Spark и помещается в таблицу результатов, которую может прочитать приемник.
Допустим, пользователи A, B и C регистрируются, и эти события обрабатываются в одном пакете. Позже регистрируются пользователи D и E, события обрабатываются в следующем пакете, запускаемом через определенный интервал. Тогда в таблицу результатов выводятся только эти новые события. А данные, записанные во время второго пакета, не включают имеющиеся данные по пользователям A, B и C.
При применении водяных знаков агрегирование может происходить в столбце времени события. Поэтому результаты будут записаны только после того, как пройдет время с водяными знаками.
Режим обновления
Update mode включает запись записей данных, которые являются новыми или для них обновлено старое значение. Этот режим можно использовать при агрегациях выходных данных. Если агрегация не применяется, режим обновления работает так же, как и режим добавления.
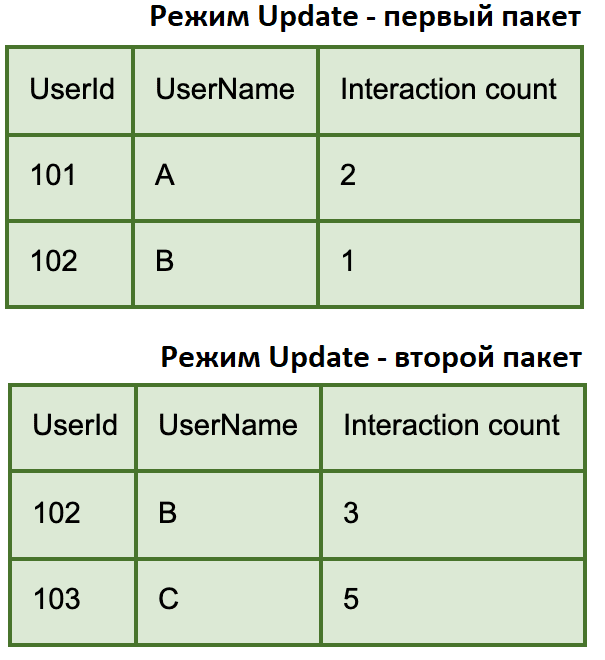
Например, нужно проанализировать пользовательское поведение на сайте. Каждый раз, когда пользователь совершает определенные действия на сайте, событие передается в Apache Kafka. Потоковая передача Spark считывает данные из Kafka, суммирует количество взаимодействий на пользователя и выводит в таблицу результатов.
Допустим, требуется вывести данные только для пользователей, взаимодействующих с текущим пакетом. Для этого следует применять режим вывода Update. Предположим, в первом пакете пользователь А совершил 2 действия на сайте, а пользователь B — 1. Данные подсчета действий для этих пользователей попали в один микропакет. Во втором пакете пользователь B совершил 2 действия на сайте, а пользователь C — 5. Второй пакет содержат данные от пользователя B, который изначально был в 1-м пакете, поскольку событие от этого пользователя также попали во 2-й пакет.
Если применяется водяной знак, старое состояние данных, прошедшее время с водяным знаком, будет очищено.
Полный режим
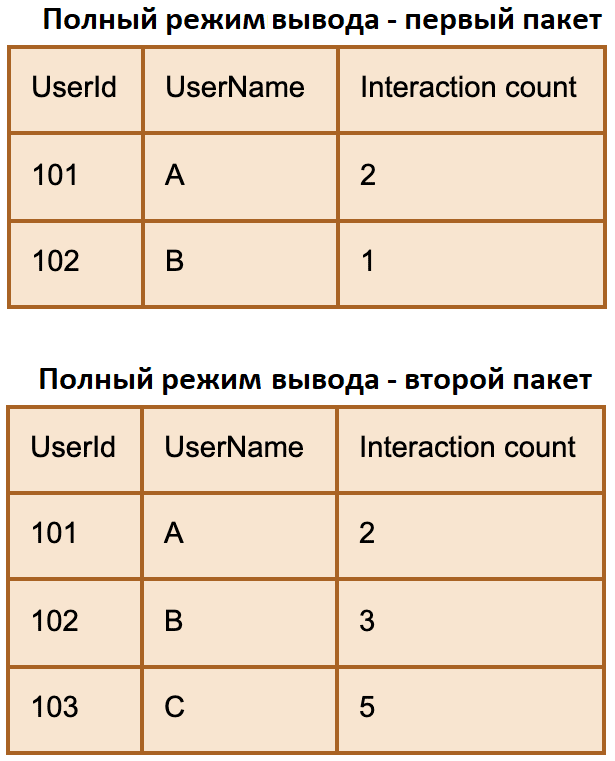
Complete mode включает повторную запись полных данных, каждый раз записывая в выходную таблицу результатов все данные. Этот режим применяется, когда требуется перезаписать все предыдущие данные и его можно использовать только при агрегирующих функциях.
К примеру, нужно выводить данные по действиям всех активных пользователей, а не только тех, что попали в текущий пакет. Предположим, в 1-м пакете пользователь А совершил 2 действия на сайте, а пользователь B — 1. Во 2-м пакете пользователь B совершил 2 действия на сайте, а пользователь C – 5. Во 2-й пакет при полном режиме вывода также попадут данные пользователя А, хотя он не генерировал никаких событий.
Читайте в нашей новой статье, почему режимы Complete и Update нельзя применять в обработке данных несколькими stateful-операторами в пределах одного потока.
Освойте практику использования Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
Источники

