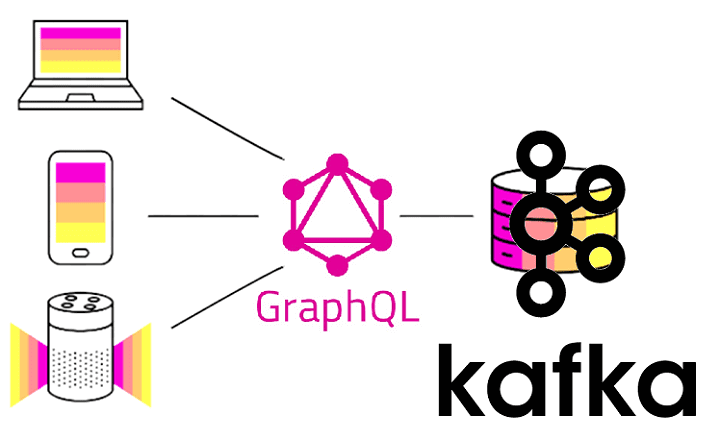
В рамках продвижения нашего нового курса Apache Kafka для разработчиков недавно мы рассматривали RESTful API к этой Big Data платформе потоковой обработки событий на примере Confluent REST Proxy. Сегодня разберем альтернативу REST-интерфейсам в виде GraphQL и применимости этой технологии к разработке распределенных Kafka-приложений. Что такое GraphQL и чем он лучше...
В данном разделе мы публикуем информационно-аналитические статьи и новости о технологиях Больших Данных (Big Data), машинного обучения (Machine Learning), Data Science, администрировании распределенных кластеров Hadoop, NoSQL, Kafka, Spark, а также реальные истории и лучшие практики их прикладного использования (use cases и best practices) в российских и зарубежных компаниях.
Чем хорош REST Proxy для Apache Kafka и что с ним не так: ключевые достоинства и недостатки RESTful API от Confluent
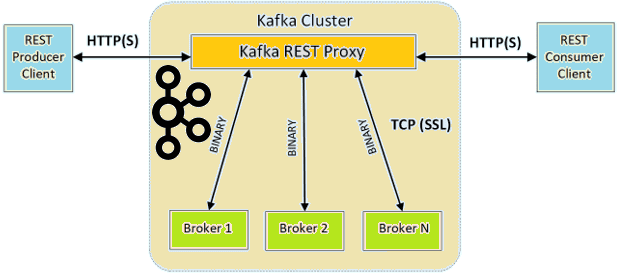
Продолжая разбираться с Confluent REST Proxy для Apache Kafka, сегодня рассмотрим основные достоинства и недостатки этого RESTful API. Читайте далее, что Confluent REST Proxy позволяет делать с Apache Kafka и что ограничивает его взаимодействие с самой популярной Big Data платформой потоковой обработки событий. 6 главных преимуществ RESTful API к...
Что такое REST Proxy к Apache Kafka: разбираемся с RESTful API от Confluent
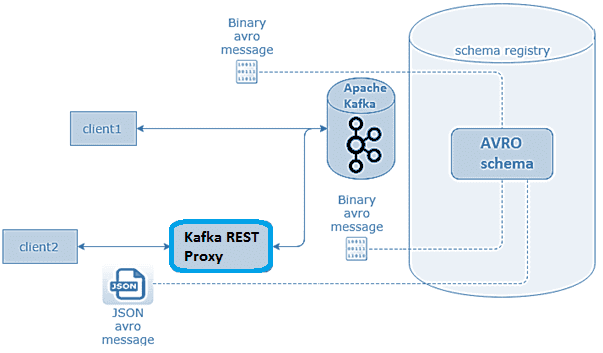
В этой статье разберем, что такое Confluent REST Proxy для Apache Kafka, как работает этот RESTful API, каким образом он связан с облачным сервисом этой популярной Big Data платформой потоковой обработки событий, а также при чем здесь Schema Registry. Основы Confluent REST Proxy для Apache Kafka Широко известная в области...
Как удаленному сервису достучаться к Apache Kafka по HTTP: REST API
Сегодня поговорим про обучение Apache Kafka и рассмотрим сценарии применения HTTP и RESTful протоколов в этой Big Data платформе потоковой обработки событий. Читайте далее, чем парадигма request-response отличается от event streaming processing, как связаны REST и HTTP, каковые преимущества RESTful API и где это используется на практике для обработки и...
5 лучших практик работы с кэшем в Apache Spark SQL

Продолжая рассказывать про курсы Apache Spark для разработчиков на практических примерах, сегодня рассмотрим, как кэширование данных позволяет оптимизировать распределенные вычисления в этом Big Data фреймворке. Читайте далее, как ускорить выполнение запросов в Spark SQL, чем отличаются функции cache() и persist(), из чего состоит план запроса и каковы альтернативы кэшированию данных...
Как перейти от Python к PySpark: ТОП-10 рекомендаций по настройке Spark-заданий

Говоря про обучение Apache Spark для разработчиков, сегодня мы рассмотрим, как быстро конвертировать Python-скрипты в задания PySpark и какие конфигурационные параметры при этом нужно настроить, чтобы эффективно использовать все возможности распределенных вычислений над большими данными (Big Data). Читайте далее, чем отличаются датафреймы в Pandas и Apache Spark, для чего нужны...
Преобразование столбцов в PySpark

Обработка данных является одной из самых первоочередных задач анализа Big Data. Сегодня мы расскажем о самых полезных преобразованиях PySpark, которые можно выполнить над столбцами. Читайте далее, как привести значения к 0 или 1, как преобразовать из строк в числа и обратно, а также как обработать недостающие значения(Nan) с примерами в...
От open-source до Confluent: 3 клиента Python для Apache Kafka

Развивая наш новый курс по Apache Kafka для разработчиков, сегодня мы рассмотрим 3 способа о взаимодействии с этой популярной Big Data платформой потоковой обработки событий с помощью языка Python, который считается самым распространенным инструментом в Data Science. Читайте далее, что такое librdkafka, чем PyKafka отличается от Kafka-Python и почему решение...
Как опередить спрос на модные новинки с облачными технологиями Big Data: кейс компании Boden по Apache Kafka и Snowflake

Интерактивная аналитика больших данных - одно из самых востребованных и коммерциализированных приложений для технологий Big Data. В этой статье мы рассмотрим, как крупный британский ритейлер запустил цифровую трансформацию своей ИТ-архитектуры, уходя от традиционного DWH с пакетной обработкой к событийно-стриминговой облачной платформе на базе Apache Kafka и Snowflake. Зачем модному ритейлеру...
DataOps и инженерия больших данных: 10 лучших практик от корпорации DNB

Чтобы добавить в наши курсы для дата-инженеров еще больше реальных примеров и лучших DataOps-практик, сегодня мы расскажем, как специалисты крупной норвежской компании DNB обеспечивают надежный доступ к чистым и точным массивам Big Data, применяя передовые методы проектирования данных и реализации конвейеров их обработки. В этой статье мы собрали для вас...