
В этой статье разберем одну из тем практического обучения администраторов Apache Kafka и рассмотрим разницу между сохранением сообщений и фиксированных смещений в этой Big Data платформе потоковой обработке событий. Читайте далее про конфигурации потребителя и брокера, отвечающие за время хранения сообщений и политику очистки журналов. Еще раз про offset или...
В данном разделе мы публикуем информационно-аналитические статьи и новости о технологиях Больших Данных (Big Data), машинного обучения (Machine Learning), Data Science, администрировании распределенных кластеров Hadoop, NoSQL, Kafka, Spark, а также реальные истории и лучшие практики их прикладного использования (use cases и best practices) в российских и зарубежных компаниях.
Машинное обучение с Apache Spark: битва пакетов или отличия библиотек MLLib от ML

Сегодня рассмотрим Apache Spark с точки зрения Data Science специалиста: поговорим про сходства и отличия библиотек машинного обучения в этом фреймворке. Также ответим на вопрос «Spark ML vs MLLib», разберем, зачем Data Scientist’у и аналитику больших данных нужны курсы по Apache Spark, а в заключение отметим наиболее важные улучшения библиотеки...
Еще 4 особенности бакетирования таблиц в Apache Spark и 7 конфигураций их настройки

Продолжая разбирать особенности бакетирования таблиц в Apache Spark, сегодня мы рассмотрим несколько примеров, как дата-инженер и аналитик данных могут работать с этим методом оптимизации SQL-запросов. Также читайте далее, какие конфигурации Apache Spark SQL связаны с бакетированием таблиц и что нового появилось в 3-ей версии этого Big Data фреймворка, чтобы такой...
Apache Spark для дата-инженеров: трудности бакетирования и способы их решения
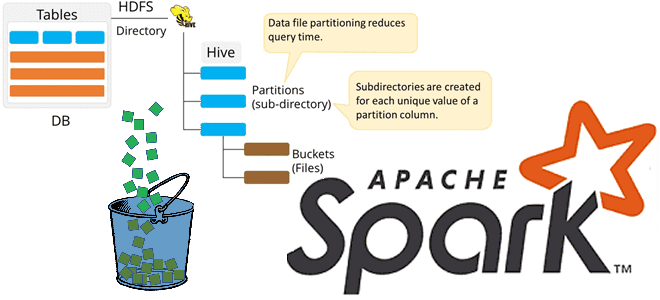
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов. Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark Напомним, бакетирование ускоряет выполнение...
Масштабируемая видеоаналитика в реальном времени с нейросетями YOLO на Apache Kafka, Spark Structured Streaming и Cassandra

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...
Где развернуть Apache AirFlow: 3 инфраструктуры для дата-инженера

Для практического использования Apache Airflow в production дата-инженеру необходимо не только обучение основам работы с этим фреймворком, но и знания о базовой инфраструктуре его развертывания. Поэтому сегодня поговорим о 3-х популярных средах для развертывания и сопровождения этого ETL-фреймворка: Astronomer, Google Cloud Composer и Amazon Managed Workflows, разобрав их основные возможности...
7 новых фич Apache Kafka Streams в релизе 2.8.0

Вчера мы говорили про важные обновления Apache Kafka 2.8.0, помимо долгожданного KIP-500, который позволяет избавиться от Zookeeper для синхронизации метаданных в распределенном кластере с помощью встроенного Quorum Controller. Сегодня рассмотрим, какие KIP’ы нового релиза коснулись одного из основных инструментов разработчика Apache Kafka – библиотеки Streams для создания распределенных приложений потоковой...
Не только KIP-500: 15 важных улучшений Apache Kafka 2.8.0

KIP-500, который позволяет наконец-то избавиться от Zookeeper в кластере Apache Kafka, заменив его Quorum Controller – далеко не единственное важное обновление в релизе 2.8.0. Сегодня рассмотрим, какие еще улучшения реализованы в новой версии главной Big Data платформы потоковой обработки событий, выпущенной в апреле 2021 года. Apache Kafka 2.8.0: новинки главных...
Проблема межкластерных транзакций в Apache Kafka и способы ее решения
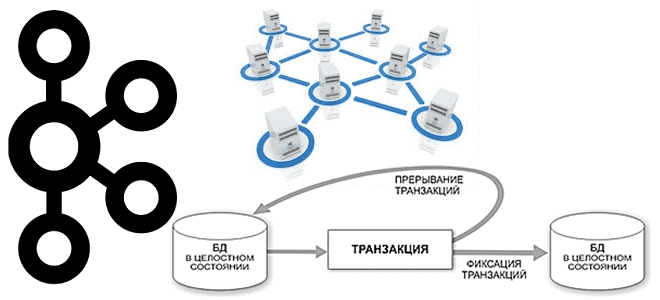
Продолжая говорить про обучение разработчиков и администраторов Apache Kafka, сегодня разберем сложности семантики строго однократной доставки сообщений (exactly once) в случае нескольких экземплярах, находящихся в разных кластерах. Читайте далее, что не так с межкластерными транзакциями, какие KIP’ы связаны с этой проблемой и при чем здесь MirrorMaker. Что не так с...
На заметку разработчику: 3 причуды Apache Spark и как с ними бороться

Развивая наши курсы по Apache Spark, сегодня мы рассмотрим несколько особенностей, с разработчик которыми может столкнуться при выполнении обычных операции, от чтения архивированного файла до обращения к сервисам Amazon. Читайте далее, что не так с методом getDefaultExtension(), зачем к AWS S3 так много коннекторов и почему PySpark нужно дополнительно конфигурировать...