
Чтобы дополнить наши курсы по Spark для разработчиков распределенных приложений и инженеров данных практическими примерами, сегодня рассмотрим кейс американской ИТ-компании ThousandEyes, которая разрабатывает программное обеспечение для анализа производительности локальных и глобальных сетей. Читайте далее, как создать надежный конвейер и устойчивое озеро данных (Data Lake) для быстрой аналитики Big Data в облаке AWS с помощью Apache Kafka, Spark и NoSQL-СУБД Redis.
Потоковая аналитика больших данных в облаке AWS
В 2020 году компания ThousandEyes, сейчас приобретенная корпорацией Cisco [1], задумалась о создании надежного и стабильного решения для аналитики больших данных о своих SaaS-продуктах, которое прослужит 2-3 года без значительного ручного вмешательства. Данные для интеллектуального анализа собирались в центральный кластер Kafka с агентов ThousandEyes по всему миру. Первоначальную архитектуру всей Big Data системы можно описать следующим образом [2]:
- приложение Apache Spark Structured Streaming принимало потоковые данные из Kafka, обогащало их с помощью информации из NoSQL-СУБД Redis, разделяло по времени и сохраняло в AWS S3 в формате Parquet.
- Apache AirFlow запускал пакетное задание в конце каждого часа, которое сжимало данные из файлов меньшего размера, сгенерированных Spark Structured Streaming, в файлы большего размера, оптимизированные для SQL-запросов через EMR Presto.
- Конечные пользователи (дата-аналитики или инструменты визуализации данных) подключались к Apache Presto, чтобы использовать его для SQL-запросов тестовых данных и получения аналитической информации.
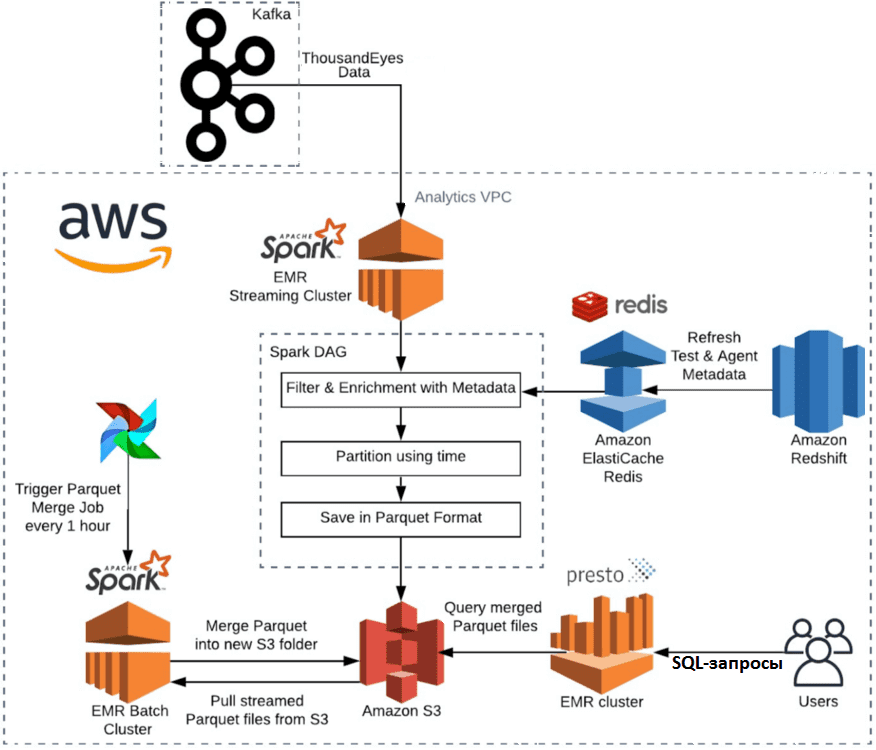
Чтобы проверить гипотезу о минимизации ручного вмешательства в последующие несколько лет, дата-инженеры и аналитики экстраполировали накопленные исторические данные о пропускной способности и объемах для различных топиков своего Kafka-кластера. Согласно расчетам, через 3 года ожидался показатель 3 Гбит в секунду. Для оценки возможности справиться с этой нагрузкой, был создан тестовый кластер Kafka и настроены следующие стандартные конфигурации Spark:
- executor.instances
- executor.cores
- driver.cores
- executor.memory and spark.executor.memoryOverhead
- driver.memory and spark.driver.memoryOverhead
- memory.storageFraction
- dynamicAllocation.enabled
Еще были изменены некоторые конфигурации, специфичные для интеграции Kafka и Spark Streaming: trigger, failOnDataLoss, maxOffsetsPerTrigger. О том, как устроена интеграция между этими Big Data платформами, мы рассказывали здесь. Также были заданы и настроены с помощью Prometheus пороговые значения для предупреждений о критических показателях всего Data Pipeline’а. Тестирование такого конвейера показало приемлемую скорость потоковой обработки больших данных, а потому было принято решение о его развертывании в production-среде. Однако, здесь дата-инженеры ThousandEyes столкнулись с нетривиальными проблемами, о которых мы поговорим далее.
Проблема с памятью при потоковой записи в Amazon S3
Через две недели после начала развертывания вышеописанной Big Data системы в production, приложение Spark Structured Streaming стало периодически выходить из строя. Сначала автоматический перезапуск YARN помогал справляться с этим без нарушения работы всего сервиса аналитики. Но через некоторое время это стало учащаться, а само Spark-приложение перешло в постоянный цикл перезапуска из-за сбоев. Оказало, причина ошибки была в том, что в версиях 2.4.3, 2.4.4, 3.0.0 Spark Structured Streaming не позволял иметь постоянно запущенный поток, записывающий миллионы файлов, без увеличения памяти драйвера Spark до десятков ГБ [2].
Когда Spark Structured Streaming используется для получения сообщений из кластера Kafka, их преобразования и записи в виде сжатых файлов Parquet в объектное хранилище AWS S3, каждый новый пакет из потока данных раз в 30 секунд записывает сотни объектов. Это приводит к созданию миллионов объектов в S3. А, поскольку для обеспечения строго однократной доставки сообщений (exactly once) в Apache Spark Structured Streaming, о чем мы писали здесь, все записанные объекты сохраняются в _spark_metadata, возрастает размер компактных файлов. Это заполняет память драйвера Spark, приводя к OOM-ошибкам (OutOfMemoryError) из-за нехватки heap-памяти для виртуальных машин Java, которые запускаются как исполнители или драйверы в составе Spark-приложения. Утечкам памяти и способам борьбы с Apache Spark мы посвятили отдельную статью.
Эта проблема настройки запуска Spark Structured Streaming без загрузки всех исторически накопленных метаданных в память, а также сброса _spark_metadata и папок контрольных точек была решена только в релизе 3.1.0 [3], опубликованного в Maven без официального выпуска для зеркал Apache. Поэтому в январе 2021 года было объявлено, что вместо версии 3.1.0 выйдет версия 3.1.1, чтобы предотвратить потенциальные проблемы для конечных пользователей [4].
Однако, на начало 2020 года эта ошибка еще не была исправлена, потому дата-инженеры ThousandEyes создавали собственное решение для обхода такого ограничения. В результате им удалось создать стабильное озеро данных в облаке AWS [2].
Как разрабатывать надежные конвейеры распределенных приложений аналитики больших данных с Apache Spark и повысить эффективность существующих Data Pipeline’ов, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Hadoop для инженеров данных
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
- Администрирование кластера Hadoop
Источники

