
Сегодня рассмотрим тему анализа и оптимизации бизнес-процессов средствами графовой аналитики больших данных. Как устроены информационные системы класса Process Mining, где еще применяются эти идеи и другие приложения теории графов в бизнесе на примере Python-библиотеки PM4Py.
Что такое Process Mining
Чтобы понять, как выполняется процесс, бизнес-аналитик строит его схему в виде подробной EPC или BPMN-диаграммы, которая представляет собой направленный граф действий с логическими операторами. Именно эта идея – представления графа событий пользовательского поведения по логам информационных систем лежит в основе процессной аналитики (Process Mining, PM). Помимо анализа логов и прикладных информационных систем типа СЭД, ERP, CRM и пр., решения Process Mining также включают некоторые возможности BI-продуктов, например, визуализация выявленных трендов в данных и формирование рекомендаций.
В отличие от Data Mining, PM-системы сфокусированы не на семантических взаимосвязях данных, а на представлении их в виде процессов. На вход подаются транзакционные данные по объектам управленческого учета: заданиям, заказам, заявкам и пр. Примечательно, что процессная аналитика использует данные для анализа бизнес-процессов без классического анализ самих данных. Process Mining не ищет низкоуровневые закономерности в исходных данных и не пытается вырабатывать управленческие решения на их основе, а пытается определить оптимальный путь выполнения процесса по событиям пользовательского поведения, используя методы выборки данных для построения модели процесса по наиболее представительным сценариям в бизнес-процессе. Определяются связи между шагами процесса, отклонения от «успешного сценария», причины этих отклонений и их влияние на результат, а также анализируется эффективность процесса и выявляются его узкие места.
Примерами PM-систем являются Proceset, Minit, ARIS Process Performance Manager, ProM, Celonis Process Mining. Также Data Analyst может самостоятельно реализовать некоторые идеи процессной аналитики, используя специализированные библиотеки. Например, PM4Py – Python-пакет интеллектуального анализа процессов. Как она работает в Google Colab, мы рассмотрим далее.
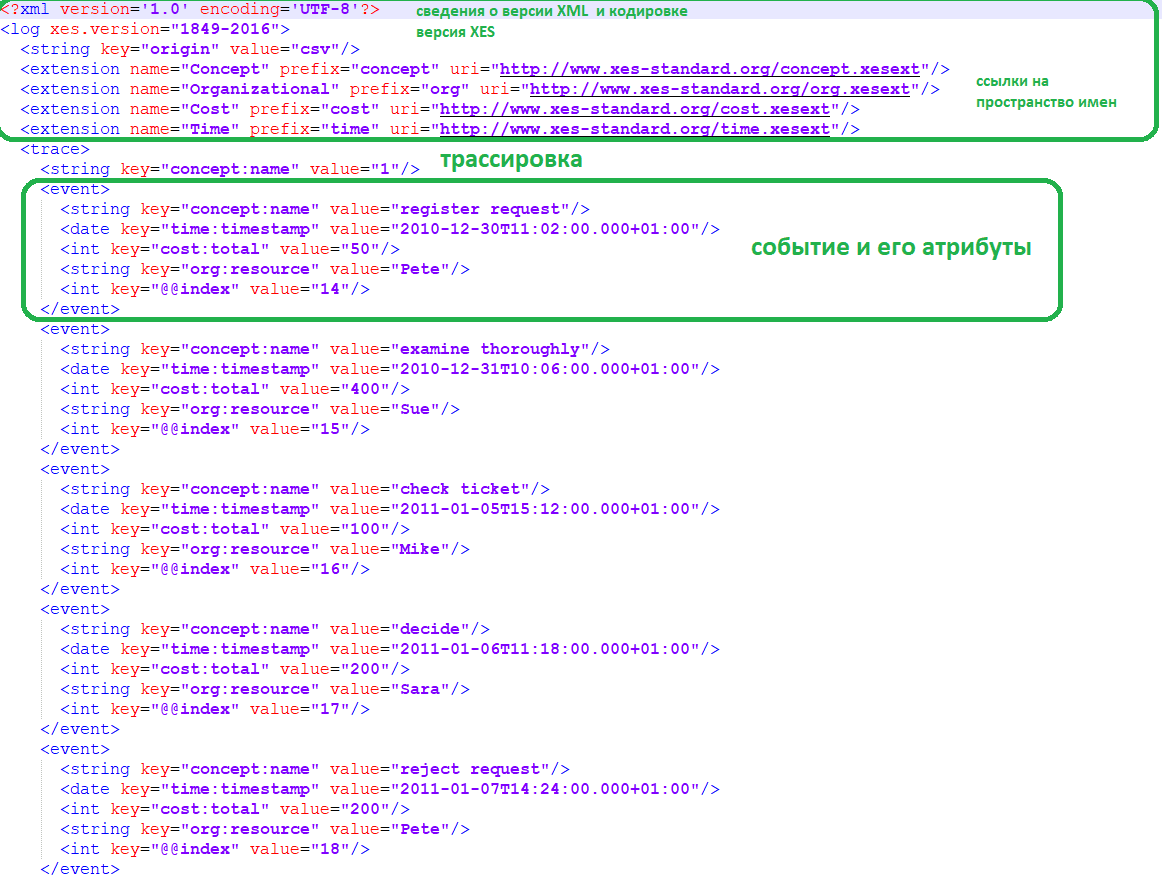
На вход в PM-систему подается лог событий пользовательского поведения, который содержит как минимум идентификатор сессии, дату и время события, а также его название. Рассмотрим пример журнала событий обработки жалоб клиентов. Данные о событиях могут храниться в CSV-файлах, так и в XML-подобном формате XES. В отличие от CSV, в файле XES можно описать отношение вмещения, т. е. включить ряд трассировок, которые содержат несколько событий. Также сам объект в XES, т. е. лог, трассировка или событие, может иметь атрибуты. Таким образом, определенные атрибуты данных, которые являются постоянными для журнала или трассировки, могут храниться на этом уровне.
Предположим, известна только общая стоимость дела, а не стоимость отдельных событий. Если сохранять эту информацию в CSV-файле, нужно реплицировать эту информацию, т. е. хранить данные только в строках, которые напрямую относятся к событиям или явно определить, что определенные столбцы получают только значение один раз, ссылаясь на атрибуты уровня конкретного случая. Стандарт XES более естественно поддерживает хранение такого типа информации.
В рассматриваемом примере XES-файл содержит данные о событиях пользовательского поведения. Например, трассировка с номером 1, маркированная тегом <string key=»concept:name»>, является первой трассировкой, записанной в этот журнал событий. Первое событие трассировки представляет действие «запрос на регистрацию» (register request), выполненное ресурсом Pete. Второе событие — это действие «тщательно изучить» (examine thoroughly), выполняемое Sue и т.д.
Как работать с этим файлом пользовательских событий, чтобы получить схему бизнес-процесса с помощью библиотеки PM4Py, рассмотрим далее.
Использование PM4Py в Google Colab: примеры
Чтобы работать в интерактивной облачной среде легковесных блокнотов Google Colab с библиотекой PM4Py, ее сперва надо установить, а затем импортировать.
!pip install pm4py import pm4py
Далее прочитаем XES-файл и визуализируем имеющиеся в нем сведения в виде BPMN-диаграммы бизнес-процесса через вызов соответствующих методов PM4Py-библиотеки. В настоящее время в PM4Py поддерживаются три различных нотации моделирования процессов: BPMN, деревья процессов и сети Петри. Все это по сути направленные графы. Из-за своей математической природы сети Петри менее неоднозначны по сравнению с BPMN. Деревья процессов представляют собой строгое подмножество сетей Петри и описывают поведение процессов иерархическим образом. Примечательно, что ни один из алгоритмов, реализованных в PM4Py, напрямую не обнаруживает модель BPMN. Но любое дерево процессов можно легко преобразовать в модель BPMN. С помощью специального алгоритма индуктивный майнер. Он позволяет преобразовать дерево процессов в BPMN на основе текущего набора данных о событиях.
if __name__ == "__main__":
log = pm4py.read_xes('/content/running-example.xes')
process_tree = pm4py.discover_tree_inductive(log)
bpmn_model = pm4py.convert_to_bpmn(process_tree)
pm4py.view_bpmn(bpmn_model)
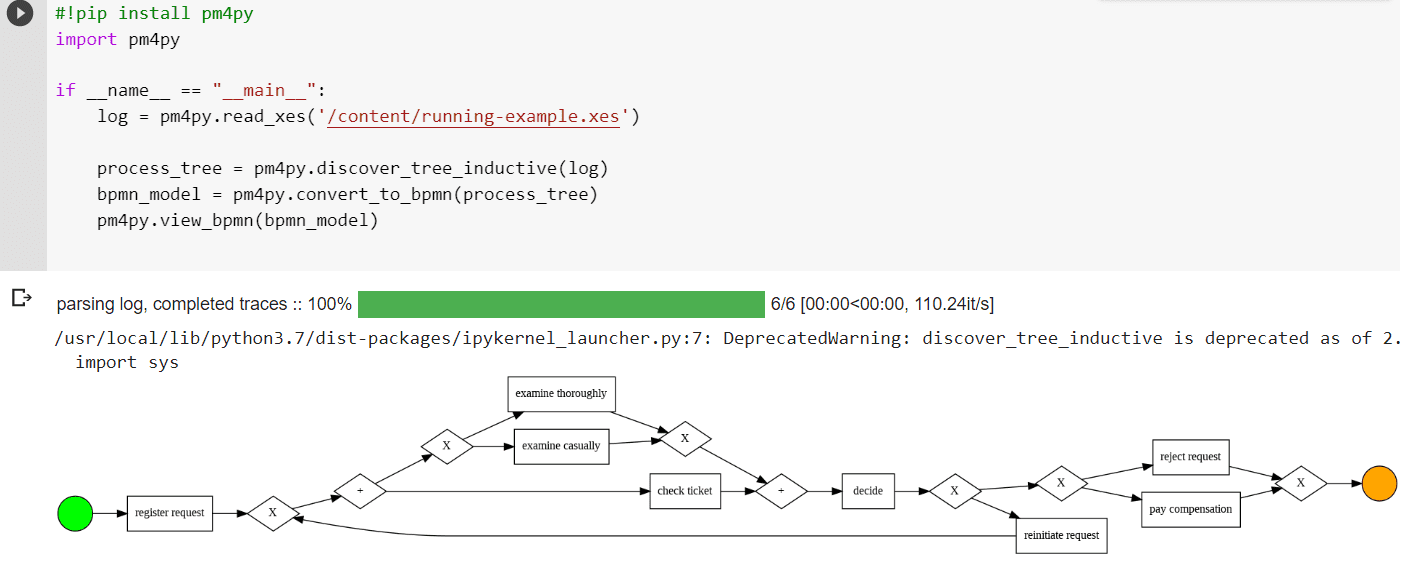
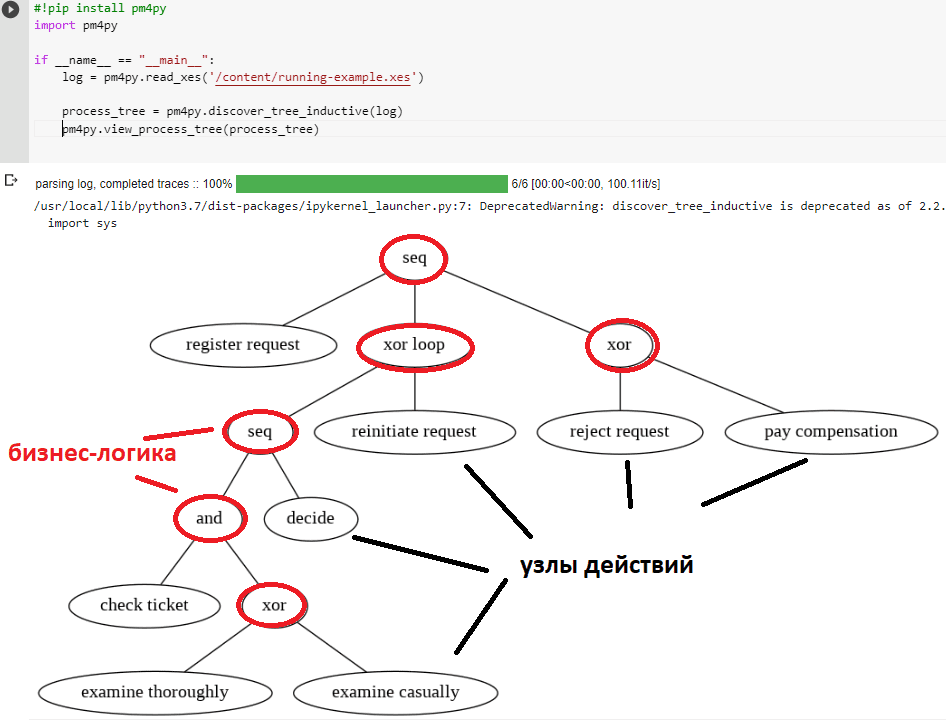
Алгоритм в этом примере фактически обнаруживает дерево процессов. С математической точки зрения оно представляет собой корневое дерево, аннотированное информацией о потоке управления. Дерево процессов моделируется сверху вниз и, аналогично BPMN-диаграмме также включает логические операторы и циклы, т.е. бизнес-логику.
Многие коммерческие решения Process Mining системы не предоставляют расширенной поддержки для обнаружения моделей процессов, используя в качестве основной визуализации процессов карты процессов. Карта процесса содержит действия и связи между ними. Связь между двумя действиями обычно означает наличие некоторой формы отношения предшествования. В своей простейшей форме это означает, что «исходная» деятельность непосредственно предшествует «целевой» деятельности. Следующий фрагмент кода создает карту процесса на основе «Directly Follows Graph» (DFG):
dfg, start_activities, end_activities = pm4py.discover_dfg(log) pm4py.view_dfg(dfg, start_activities, end_activities)
Функция pm4py.discover_dfg(log) возвращает три значения:
- dfg — словарь, отображающий пары действий, которые непосредственно следуют друг за другом, в число соответствующих наблюдений;
- второй и третий аргументы — это начальные и конечные действия, наблюдаемые в журнале событий (счетчики).
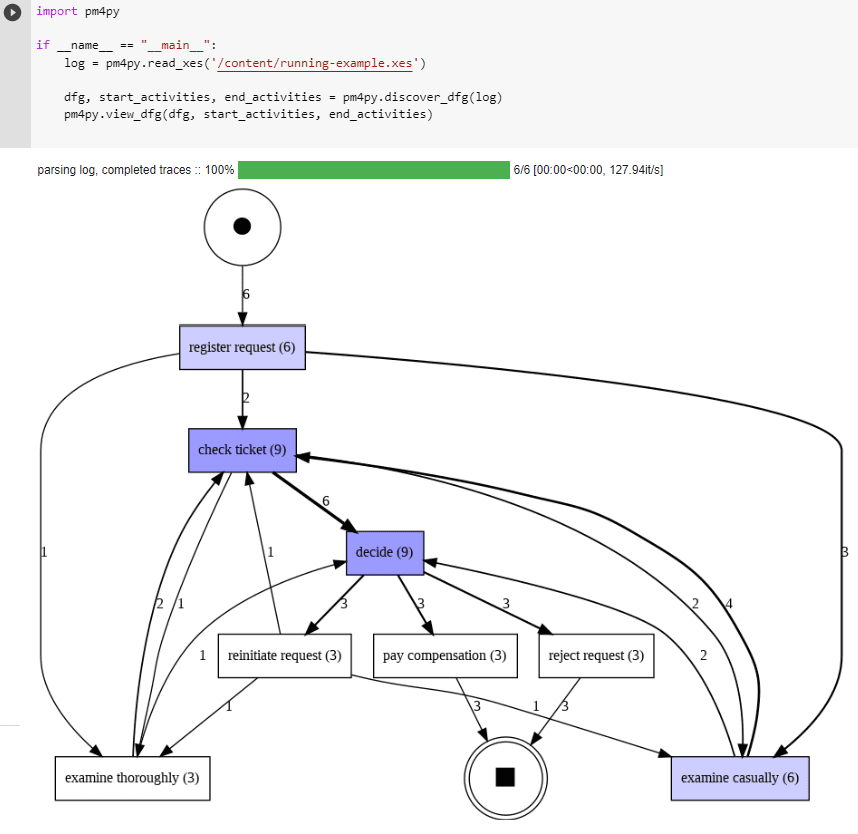
В нашем примере в 6 случаях запрос на регистрацию является первым наблюдаемым действием (представленным дугой, помеченной значением 6). В журнале событий действие проверки билета выполняется непосредственно после действия запроса регистрации. Тщательно изучить активность следует после регистрации один раз, внимательно изучить следует 3 раза. Всего за регистрационной активностью следует 6 различных событий, т. е. в журнале событий работающего примера есть 6 трассировок. На практике существует намного больше взаимосвязей по сравнению с количеством случаев в журнале событий. Поэтому представление DFG намного сложнее, чем модели процессов в виде BPMN-диаграммы или иерархического дерева. Кроме того, в DFG-графе намного сложнее сделать вывод о фактическом выполнении процесса.
В PM4Py также есть более продвинутый алгоритм построения эвристических карт процессов — Heuristics Miner, расширяющий возможности DFG. В карте процессов Heuristics Miner дуги между действиями представляют наблюдаемый параллелизм. Например, алгоритм может определить, что проверка билета и осмотр происходят одновременно. Следовательно, эти действия не будут связаны в карте процесса. Таким образом, эвристическая карта процессов с алгоритмом Heuristics Miner обычно проще, чем DFG-граф.
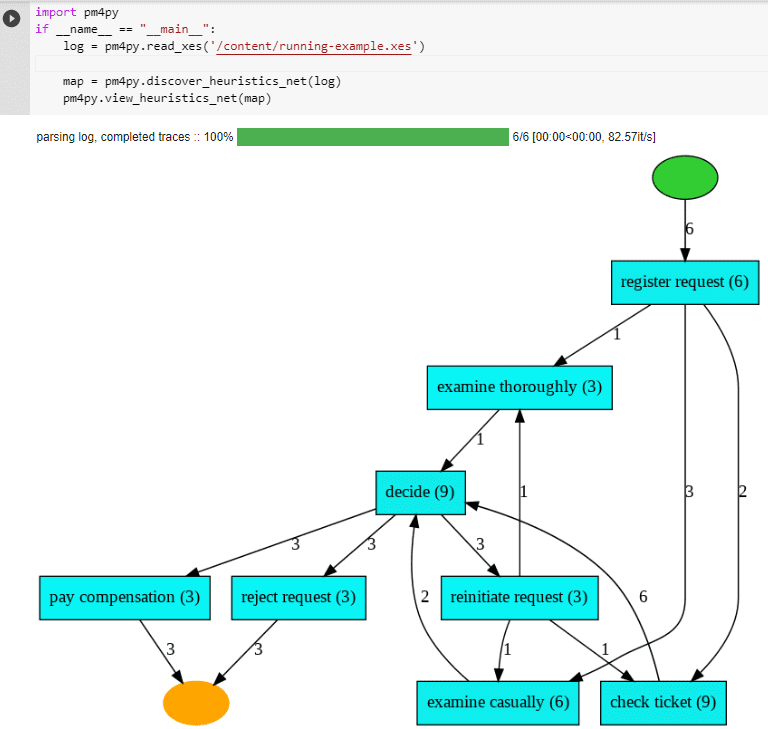
В заключение отметим, что подобные графы можно построить, используя методы классов, упакованных в библиотеки работы с графами в Apache Spark: GraphFrames и GraphX. Таким образом, самостоятельно реализовать идеи Process Mining можно с помощью типовых инструментов стека Big Data. Однако, лучше воспользоваться специализированными средствами, например, графовой СУБД Neo4j, аналитические возможности которой мы рассматривали здесь на примере анализа графа европейской газотранспортной системы. А про решение проблемы с зависимостями Python-моделей с помощью графов читайте в нашей новой статье.
Как сделать это на практике, используя средства графовой аналитики больших данных в реальных проектах, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

