
Недавно мы разбирали, что такое Apache Pulsar: архитектуру, принципы работы, сходства и различия с Kafka и RabbitMQ. В продолжение этого разговора, сегодня рассмотрим основные мифы и их опровержения в горячем споре о технологиях Big Data. Читайте далее про холивар Apache Kafka vs Pulsar vs RabbitMQ: что лучше выбрать для построения надежной системы потоковой аналитики больших данных и почему.
3 причины не сравнивать Apache Pulsar с Kafka и RabbitMQ
В real-time обработке больших данных и интеграции распределенных систем RabbitMQ считается самым популярным конкурентом Apache Kafka – Big Data платформы потоковой передачи событий. Об этом мы подробно рассказывали здесь. Однако, RabbitMQ – далеко не единственная альтернатива Kafka. С 2019 года все большую известность получает новый проект Apache Software Foundation (ASF) – фреймворк Pulsar. Изначально разработанный в Yahoo! для собственных нужд корпорации, в 2016 году Pulsar получил статус open-source, а еще через 2 года – стал проектом фонда ASF высшего уровня.
Прежде всего поясним, что напрямую сравнивать эти 2 Big Data фреймворка не совсем корректно по следующим причинам [1]:
- появившись в разное время, они отличаются степенью зрелости – Pulsar приобрел широкую известность и стал проектом верхнего уровня Apache Software Foundation только с 2018 года, а Kafka находится в этом статусе с 2012 года и успешно используется в качестве надежной распределенной платформы потоковой обработки событий, интеграционной шины и брокера сообщений;
- несмотря open-source статус обоих систем под лицензией Apache0, Pulsar развивается, в основном, благодаря профессиональному сообществу энтузиастов, в то время как вокруг Kafka выросла целая инфраструктура на коммерческой поддержке, например, благодаря компании Confluent.
Возможно, поэтому Apache Kafka воспринимается как устоявшаяся зрелая технология, которая подходит для крупных корпораций с повышенными требованиями к надежности, тогда как Pulsar – вариант для стартапов. Например, китайская инвестиционная холдинговая компания Tencent пробует Pulsar в проекте биллинга, но превалирующую часть основного бизнеса использует Kafka, которая объединяет более 1000 брокеров в единый логический кластер [2].
Наконец, по аналогии с вопросом Kafka vs Pulsar стоит подчеркнуть нерелевантность прямого сравнения c RabbitMQ, который представляет собой промежуточное open-source ПО для обмена сообщениями на основе стандарта AMQP для организации очередей с низкой задержкой. Поэтому скорость работы и пропускная способность этого фреймворка зависит от обмена сообщениями как на стороне производителя, так и на уровне очередей, связанных с ними на стороне потребителя [3]. С этим связан следующий миф о преимуществе Pulsar над Kafka и RabbitMQ, который мы рассмотрим далее.
Очереди сообщений vs потоки Big Data: объединить нельзя разделить
Мы уже упоминали, что Pulsar сочетает некоторые возможности Kafka и RabbitMQ, например, организацию очереди сообщений и потоковую передачу событий. Однако, в действительности реализовать оба этих направления на приемлемом уровне достаточно сложно из-за разницы самих архитектурных моделей. В частности, очереди сообщений (Message Queue, MQ) используются для точечной связи, обеспечивая асинхронное взаимодействие отправителя и получателя данных. В свою очередь, потоковая обработка событий предполагает обработку данных в режиме онлайн с минимальной временной задержкой в общении между их производителем (producer) и получателем (consumer).
Apache Pulsar имеет ограниченную поддержку очереди сообщений, т.к. в нем отсутствуют такие функции обмена данными, как транзакции, маршрутизация, фильтрация сообщений и прочие возможности, которые обычно присутствуют в типовых MQ-системах, например, IBM MQ, RabbitMQ и ActiveMQ. Даже MQ-адаптеры Pulsar не слишком помогают решить эту проблему из-за ряда функциональных ограничений. Таким образом, как и Kafka, Pulsar не полностью реализует MQ-концепцию. Поэтому если требуется готовое решение для непосредственного обмена сообщениями, его следует искать среди соответствующих брокеров: RabbitMQ, IBM MQ, RabbitMQ, ActiveMQ, NATS и другие аналоги.
С другой стороны, Pulsar также не 100% поддерживает потоковую обработку событий. К примеру, он не обеспечивает семантику строго однократной доставки сообщений (exactly-once), о которой мы рассказывали здесь. Это существенно сокращает число вариантов использования Apache Pulsar в реальных Big Data системах. В частности, с этим фреймворком не получится реализовать обработку онлайн-платежей, т.к. при отсутствии exactly-once гарантии любой сбой может вызвать дублирование или потерю данных о финансовых проводках. Справедливости раи стоит отметить, что Pulsar предоставляет функцию дедупликации, которая гарантирует, что сообщение не будет сохранено в брокере дважды. Однако, это не мешает потребителю прочитать сообщение несколько раз, что не соответствует концепции exactly-once.
Кроме того, Pulsar предоставляет только некоторые элементарные функции для потоковой передачи, что подходит для простых обратных вызовов, но не становится полноценной онлайн-обработкой. Поэтому нельзя назвать Pulsar 100%-ной альтернативой возможностям Kafka Streams или KSQL для создания stateful-приложений, которые включают информацию о состоянии, скользящие окна и прочие идеи настоящей потоковой обработки Big Data. Примеры потоковой аналитики больших данных с Pulsar обычно используют его в сочетании с Apache Spark или Flink, что предполагает усложнение распределенной Big Data инфраструктуры.
Наконец, в отличие от транзакций в Kafka, в Pulsar невозможно точно привязать сообщения, зафиксированные к состоянию, записанному внутри потокового процессора. Таким образом, Pulsar не хватает функций потокового соединения, агрегирования, оконной обработки, отказоустойчивого управления состоянием и вычислений на основе времени событий. А обратной стороной гибкой многоуровневой архитектуры за счет BookKeeper является снижение функциональных возможностей топиков по сравнению с Kafka. Напомним, Apache BookKeeper изначально был задуман как журнал упреждающей записи для узла имен HDFS Hadoop в случае кратковременного хранения данных [2]. Об особенностях эксплуатации и администрирования Apache Pulsar в сравнении с Kafka мы поговорим в следующий раз.
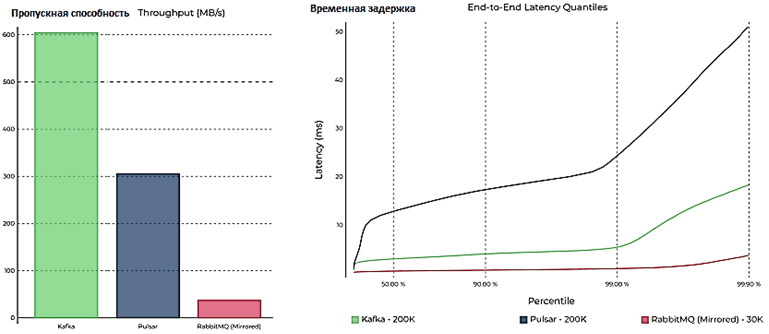
В заключение отметим, что некорректность прямого сравнения Apache Pulsar с Kafka и RabbitMQ показывает бенчмаркинговый тест, проведенный компанией Confluent, в рамках которого не получилось оценить производительность всех 3-х фреймворков по одному сценарию из-за разных концепций работы с данными. В частности, RabbitMQ работает с устойчивой очередью, которая сохраняет сообщения на диск тогда и только тогда, когда сообщения еще не были использованы. В отличие от Kafka и Pulsar, RabbitMQ не поддерживает «перемотку» очередей для повторного чтения старых сообщений. Кроме того, RabbitMQ не предполагает разделов в топике, используя обмен для маршрутизации сообщений в связанные очереди с помощью атрибутов заголовка, ключей маршрутизации или привязок обмена, из которых потребители могут обрабатывать сообщения. Наконец, в случае RabbitMQ накладные расходы на репликацию данных серьезно снижают пропускную способность всей системы, т.к. этот фреймворк не предполагает неограниченного масштабирования. Все это сказалось на процессе бенчмаркингового тестирования и его результатах, которые в очередной раз показали первенство Apache Kafka по пропускной способности и скорости обработки данных, а также соотношению цена-качество (стоимость записанного байта) [3]. Впрочем, не стоит безоговорочно доверять этому тесту, о чем мы расскажем завтра.
Освоить на практике специфику администрирования кластеров и разработки Kafka-приложений для аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.confluent.io/kafka-vs-pulsar/
- https://dzone.com/articles/pulsar-vs-kafka-comparison-and-myths-explored
- https://www.confluent.io/blog/kafka-fastest-messaging-system/

