
Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью типовых или пользовательских функций PySpark.
Чтение данных из AWS S3 с Apache Spark и boto3
Озеро данных (Data Lake) часто организуется на базе облачного объектного хранилища AWS S3. Чтобы использовать эти данные в задачах прогнозирования с помощью ML-моделей или анализировать их, необходимо сперва считать эту информацию. Это можно сделать с помощью заданий PySpark и учетных записей в IAM (Identity and Access Management) – службе Amazon, которая позволяет получить доступ к другим сервисам AWS. IAM дает возможность указать, кто или что может получить доступ к сервисам и ресурсам AWS, централизованно управлять мелкими разрешениями и анализировать доступ для уточнения разрешений.
Роли IAM позволяют предоставить права доступа пользователям или сервисам, у которых обычно нет доступа к корпоративным AWS-ресурсам. Пользователям IAM или сервисам AWS можно присвоить роли для получения временных данных для доступа к данным и вызовов API. Это исключает необходимость предоставления долгосрочных данных для доступа или назначения разрешений для каждого объекта, которому требуется доступ к определенному ресурсу.
Разрешения предоставляют доступ к ресурсам AWS и предоставляются объектам IAM (пользователям, группам и ролям), которые не могут выполнять никаких действий на платформе AWS без необходимых разрешений. Чтобы предоставить объектам разрешения, можно назначить правило, определяющее тип доступа, допустимые действия и ресурсы для их выполнения. Также можно указать любые условия, которые должны выполняться для разрешения или запрещения доступа.
Чтобы считать данные из AWS S3 средствами Apache Spark, напишем небольшой PySpark-скрипт в интерактивной веб-среде Google Colab или Jupyter Notebook. Сперва установим необходимые библиотеки, используя менеджер пакетов pip. Помимо пакета pyspark следует установить библиотеку boto3, которая непосредственно позволяет обращаться к сервисам AWS. Вообще boto3 – это SDK-пакет от Amazon, дающий возможность разработчикам Python писать код, использующий AWS-сервисы S3 и EC2. Используя boto3, можно получить набор учетных данных AWS для чтения данных с помощью PySpark. При этом важно убедиться, что используемая IAM-роль имеет доступ к корзине S3. Для этого создадим набор временных учетных данных S3, доступных в течение 1 часа. Пример кода на PySpark выглядит следующим образом:
pip install pyspark
pip istall boto3
from pyspark import SparkConf
from pyspark.sql import SparkSession
import boto3session = boto3.session.Session()
sts_connection = session.client('sts')response = sts_connection.assume_role(RoleArn="arn:aws:iam::{YOUR_AWS_ACCOUNT_ID}:role/pyspark-iam-role", RoleSessionName='pyspark-s3-role',DurationSeconds=3600)
credentials = response['Credentials']
Далее можно считать данные из S3, используя пользовательские учетные данные, добавив их в конфигурацию задания Apache Spark. При этом важно иметь правильные JAR-файлы в качестве зависимостей для используемой версии PySpark.
builder = SparkSession.builder.appName("pyspark-demo")builder = builder.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")\
.config("spark.hadoop.com.amazonaws.services.s3.enableV4", "true")\
.config("spark.jars.packages", "org.apache.hadoop:hadoop-aws:3.2.2,com.amazonaws:aws-java-sdk-bundle:1.11.888")\
.config("spark.hadoop.fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider")\
.config("spark.hadoop.fs.s3a.access.key", credentials['AccessKeyId'])\
.config("spark.hadoop.fs.s3a.secret.key", credentials['SecretAccessKey'])\
.config("spark.hadoop.fs.s3a.session.token", credentials['SessionToken'])spark = builder.getOrCreate()
Далее можно прочитать данные из AWS S3 в датафрейм PySpark:
df = spark.read.csv("s3a://your/csv/path")
df.show()
Как обеспечить конфиденциальность прочитанных данных, используя типовые и пользовательские функции PySpark, рассмотрим далее.
Безопасность данных с PySpark
Обеспечить конфиденциальность данных можно, применив маскирование или шифрование личной информации на уровне столбца в датасете, используя несколько функций PySpark. В качестве примера рассмотрим, как маскировать или шифровать адреса электронной почты, которые являются персональными данными и должны охраняться согласно 152-ФЗ и GDPR. Самый простой способ замаскировать или зашифровать данные — это использовать функцию lit(), заменив значение электронной почты заданным строковым значением, в данном случае «***Masked***». В следующем примере значения NULL не маскируются с помощью условия when():
conditions_mask = when(col("email").isNotNull(), lit("***Masked***")).otherwise(col("email"))
df_emails = df_emails.withColumn("email", conditions_mask)df_emails.show(5, False)
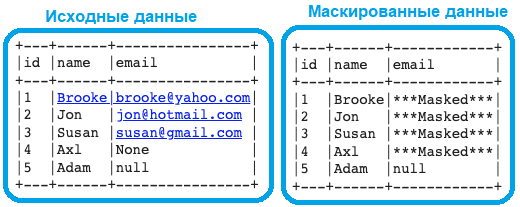
При всей простоте этого метода, он очень быстрый и гибкий, позволяет применять различные условия к данным, например, маскировать только адреса электронной почты, которые содержат символ @. Можно сделать маскирование более сложным, например, отображать первые 2 символа адреса электронной почты и последние 6 символов, заменив остальные на ****. Например, su****il.com и jo****il.com. Это достигается с помощью функции expr():
conditions_mask = (when(col("email")=="None", col("email"))
.when(col("email").isNotNull(), expr('concat(LEFT(email, 2) ,"****", RIGHT(email, 6))'))
.otherwise(col("email"))
)
df_emails = df_emails.withColumn("email", conditions_mask)df_emails.show(5, False)
Также можно функцию expr() на substring(), которая также есть в PySpark. Оба эти метода отлично работают, если не нужно снова получить исходные значения зашифрованных данных. В таком случае следует использовать более сложные техники, например, шифрование и дешифрование AES. Это симметричный тип шифрования, где используется один и тот же ключ как для шифрования, так и для расшифровки данных. Какие еще алгоритмы шифрования используются в Apache Spark, читайте в нашей новой статье.
В следующем фрагменте кода снова применяется PySpark-функция expr(), позволяющая выполнять функции aes_encrypt() и aes_decrypt(), предоставляя 16-битный ключ и режим по умолчанию GCM.
df_emails = df_emails.withColumn("encrypted_email", expr("hex(aes_encrypt(email, '1234567890abcdef', 'GCM'))"))df_emails.show(5, False)
df_emails = df_emails.withColumn("decrypted_email", expr("aes_decrypt(unhex(encrypted_email), '1234567890abcdef', 'GCM')").cast(StringType()))df_emails.show(5, False)

Наконец, можно написать собственную UDF-функцию Python, чтобы применить ее к каждой строке. Но этот метод будет менее эффективным с точки зрения производительности, особенно если речь идет об обработке миллиардов строк. В любом случае, после применения маскирования или шифрования к значениям столбцов с конфиденциальными данными, их можно сохранить, например, в формате файла Parquet, следующим образом:
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
from pyspark.sql.functions import lit, col, when, exprschema = StructType([
StructField("id",IntegerType(),True),
StructField("name",StringType(),True),
StructField("email",StringType(),True)])data_emails=[(1, "Brooke", "brooke@yahoo.com"),
(2, "Jon", "jon@hotmail.com"),
(3, "Susan", "susan@gmail.com"),
(4, "Axl", "None"),
(5, "Adam", None)]df_emails = spark.createDataFrame(data=data_emails, schema=schema)df_emails.show(5, False)
В заключение отметим возможность использования методов криптографических Python-библиотек, например, PyCrypto и PyCryptodome, о которых мы писали здесь.
Про применение Apache Spark при переходе от озера данных на HDFS в облачное хранилище объектов Google, читайте в нашей новой статье.
Освойте использование Apache Spark в аналитике больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark

