
В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД Cassandra.
Видеоаналитика в реальном времени с Deep Learning и нейросетями YOLO
Создавая уникальное решение для анализа видео в режиме, близком к реальному времени, британская ИТ-компания Southworks использовала сразу несколько популярных технологий Big Data и Machine Learning, чтобы обрабатывать сложные вычисления масштабируемым и распределенным способом. В качестве входных данных поступает видеопоток из различных источников: видеофайлы, веб-камеры и камеры наружного/внутреннего наблюдения. Для процессов интеллектуального анализа данных используются две предварительно обученные нейросети и модель обучения без учителя.
Реализован конвейер распараллеленного анализа видео в реальном времени с помощью нескольких моделей глубокого обучения, которые выполняют обработку по фрагментам данных (кадрам), включая следующие распространенные сценарии видеоаналитики [1]:
- распознавание эмоций;
- обнаружение объекта;
- извлечение цветовой палитры
Для этого используются методы машинного обучения (Machine Learning) на базе нейронных сетей семейства YOLO, которые сегодня считаются одними из наиболее быстрых и точных алгоритмов обнаружения объектов в реальном времени. В частности, в декабре 2020 года Scaled YOLO v4 показала наилучшие результаты (55.8% AP) на датасете Microsoft COCO среди аналогов, обогнав по точности нейросети Google EfficientDet D7x/DetectoRS or SpineNet-190 (self-trained on extra-data), Amazon Cascade-RCNN, ResNest200 Microsoft RepPoints v2 и Facebook RetinaNet SpineNet-190. Такие результаты были достигнуты в условиях оптимального соотношения скорости к точности во всем диапазоне точности и скорости от 15 FPS до 1774 FPS [2].
Примечательно, что YOLO – это первая нейросеть, которая распознавала объекты в реальном времени на мобильных устройствах. Ее отличительной особенностью является отсутствие цикло for в архитектуре слоев, что обеспечивает высокие скорость и точность распознавания за один прогон, как это и следует из названия YOLO (You Look Only Once) [3].
В решении Southworks используется 3-я версия YOLO-модели, а для извлечения цветовой палитры из нескольких входных кадров применяется ML-алгоритм кластеризации без учителя под названием K-средние (K-means). Он группирует или сегментирует датасеты с общими или похожими атрибутами, чтобы оценить некоторые параметры алгоритмов Machine Learning.
Предварительно обученные модели используются по двум основным причинам:
- простота интеграции, даже с учетом модификаций модели, вызванных изменениями контекста;
- надежность между несколькими запусками, что означает получение таких же или лучших результатов в следующих итерациях.
Поскольку речь идет о сборе и агрегации потоковых данных из нескольких источников, в данном решении используется Apache Kafka. А для распределенной аналитической обработки применяется Apache Spark Structured Streaming. Наконец, в качестве в качестве уровня сохраняемости выбрана высокоскоростная NoSQL-СУБД Cassandra, которая может обрабатывать как структурированные, так и неструктурированные данные. Как именно выглядит лямбда-архитектура этой Big Data системы, мы рассмотрим далее.
Computer vision на Python
Код курса
VISI
Ближайшая дата курса
29 июля, 2024
Продолжительность
40 ак.часов
Стоимость обучения
90 000 руб.
Apache Kafka, Spark Structured Streaming и Casandra для Machine Learning в режиме онлайн
Архитектуру и принцип действия всей big Data системы видеоаналитики в реальном времени от Southworks можно представить следующим образом [1]:
- входной точкой является API, с помощью которого пользователь может сделать запрос на запуск анализа видео, запросить статус анализа, его результаты или показатели;
- NoSQL-СУБД Cassandra хранит данные видеоанализа в 3-х таблицах: само видео, метрики и результаты анализа.
- Данные во все таблицы Cassandra вносят задания Apache Spark Structured Streaming.
- При запуске нового видеоанализа, входные данные сохраняются в Cassandra, а сообщение об этом записывается в топик Kafka под названием video, включая идентификатор видео, URL-адрес источника и список ML-моделей вывода для запуска;
- Сообщение из Kafka используется Spark-заданием, которое отвечает за извлечение кадров из предоставленного видео, а также за их постановку в очередь в топике кадров (frames) Kafka. Остальные задания Spark также используют этот топик с кадрами, который содержит идентификатор видео, номер кадра, изображение, закодированное в base64 (буфер), временную метку кадра в видео и список ML-моделей для запуска.
- Spark-задание анализа видео использует модели глубокого обучения (Deep Learning) для прогнозирования каждого извлеченного кадра и сохранения их в Cassandra.
- Spark-задание по хранению кадров заботится о сохранении каждого извлеченного кадра в файловой системе, которое позже будет использоваться API для отображения результатов.
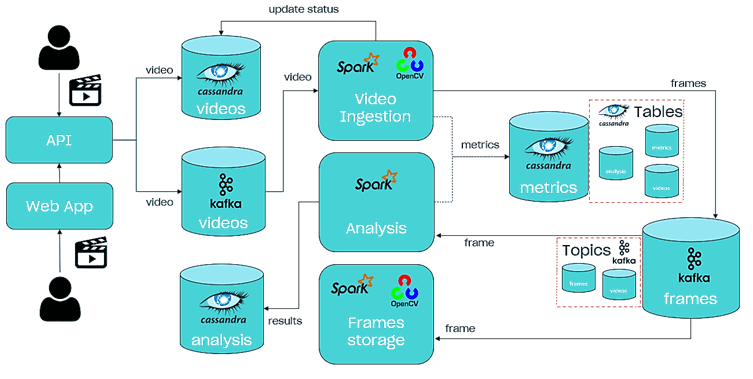
Для простоты развертывания и сопровождения каждый компонент решения (Apache Kafka, Spark и Cassandra) упакован в Docker-контейнер. Взаимодействие с пользователем происходит в рамках веб-интерфейса приложения, разработанного с помощью библиотеки ReactJS [1]. А исходный код всей Big Data системы доступен на Github [4]. Другой пример построения потокового конвейера обработки видео с Apache Kafka и алгоритмами Machine Learning смотрите в нашей новой статье.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
27 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Узнайте больше про возможности Apache Spark и Kafka для разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://medium.com/southworks/scalable-real-time-data-analysis-with-apache-spark-structured-streaming-3292256768c1
- https://habr.com/ru/post/531786/
- https://habr.com/ru/post/482794/
- https://github.com/southworks/spark-streaming-live-video-ai/tree/master/src/video-app

