Обучая дата-инженеров и разработчиков распределенных приложений для аналитики больших данных, сегодня рассмотрим кейс компании Pinterest по построению масштабируемого решения для индексации записей в Apache HBase. Чем хранилище Ixia отличается от Lily HBase Indexer, зачем понадобился собственный аналог Solr и ElasticSearch, а также как все это работает в реальном времени с Apache Kafka и Hadoop HDFS.
Постановка задачи: проблема вторичного индекса в Apache HBase
В соцсети Pinterest, фотохостингом которой ежедневно пользуются миллионы людей по всему миру, Apache HBase является одной из наиболее важных систем хранения данных. На этом NoSQL-хранилище работают многие сервисы компании: хранение онлайн-трафика, графовая база данных Zen и колоночное хранилище UMS. HBase имеет множество преимуществ: сильная согласованность на уровне строк в больших объемах запросов, гибкая схема, доступ к данным с малой задержкой и интеграция с Apache Hadoop. Но эта нереляционной СУБД класса «семейство столбцов» изначально не поддерживает расширенное индексирование и стандартные SQL-запросы.
Напомним, вторичным считается индекс, который определен на поле файла данных, отличном от поля, по которому выполняется упорядочение. Этот альтернативный путь доступа к данным может содержать не адреса, а значения атрибутов, чтобы обслуживать определенный класс запросов без обращения к записям данных. На практике вторичное индексирование довольно востребовано, но поддерживать его непосредственно в HBase довольно сложно. Ведение отдельных индексных таблиц по мере роста количества индексов – не лучшее решение с точки зрения масштабируемости, эффективности выполнения запросов и сложности кода. Поэтому дата-инженеры и ИТ-архитекторы Pinterest разработали собственный продукт для хранения данных под названием Ixia, который обеспечивает вторичное индексирование HBase практически в реальном времени [1]. Как это было сделано, мы рассмотрим далее.
Что такое Ixia и Lily HBase Indexer
Дизайн Ixia во многом похож на Lily HBase Indexer от NGDATA – инструмент, который позволяет быстро и легко искать любой контент, хранящийся в HBase [1]. Он быстро и легко индексирует строки HBase без написания строчки кода, обеспечивая индексацию контента через полнотекстовый поисковой движок Apache Solr, похожий на Elasticsearch. Это реализует гибкий, масштабируемый и расширяемый способ определения правил индексации. Индексирование выполняется асинхронно и не влияет на пропускную способность записи в HBase [2]. SolrCloud используется для хранения фактического индекса, чтобы обеспечить масштабируемость индексации. Индексатор HBase работает как приемник репликации HBase. Когда обновления записываются на серверы региона HBase, они асинхронно «реплицируются» в процессы HBase Indexer. Индексатор анализирует входящие события мутации HBase, создает документы Solr и отправляет их на серверы SolrCloud.
Проиндексированные документы в Solr содержат достаточно информации, чтобы однозначно идентифицировать строку HBase, на которой они основаны, что позволяет использовать Solr для поиска контента в HBase. Репликация HBase основана на чтении файлов журнала HBase, которые являются точным источником истинной информации о том, что хранится в HBase без пропущенных или дополнительных событий. Обычно лог содержит всю информацию, необходимую для индексирования, поэтому не требуется дорогостоящее случайное чтение HBase.
Репликация HBase доставляет небольшие пакеты событий, чтобы избежать двойной индексации одной и той же строки, если она была обновлена дважды за короткий промежуток времени. Также это пакетирует/буферизует обновления для Solr, повышая производительность. Обновления применяются к Solr до подтверждения обработки событий в HBase, поэтому потеря событий невозможна.
Вся информация об индексаторах хранится в ZooKeeper, а вся работа по индексированию для одного настроенного индексатора распределяется между всеми машинами в кластере. Таким образом, добавление дополнительных узлов индексатора позволяет горизонтальное масштабирование. Будучи основанным на HBase, индексатор обладает способностью успешно обрабатывать аппаратные сбои. Поэтому отказ узлов индексирования или выход из строя узлов Solr не приведет к потере проиндексированных данных [3].
Ixia предоставляет общий интерфейс поиска поверх HBase, который играет роль источника истины. Поисковая система изначально оптимизирована для поиска по инвертированному индексу и хранит индексы, поддерживает большой набор поисковых и агрегированных запросов в бизнес-сценариях Pinterest. По сути, Ixia – это хранилище документов из следующих логических компонентов:
- пространство имен, однозначно сопоставленное с пространствами имен HBase и Muse – собственной поисковой системой Pinterest, по функциональным возможностям аналогичной Solr и ElasticSearch. Muse оптимизирован для онлайн-обслуживания, поисковых и агрегированных запросов. Он применяется в Pinterest для различных критически важных задач, таких как домашняя лента, реклама, покупки и пр. Ixia использует Muse в качестве своей поисковой системы, чтобы обеспечить расширенные функции поиска в столбцах, не являющихся ключевыми строками.
- ключ документа, который однозначно идентифицирует документ Ixia и имеет однозначное сопоставление с ключом строки HBase;
- таблица, сопоставленная с таблицей HBase;
- поле со структурой <namespace>: <table>: <hbase_column_family>: <hbase_column_name>, которая однозначно идентифицирует ячейку HBase и поле индекса Muse.
Ixia поддерживает изменение схемы онлайн. HBase не имеет схемы, а Muse использует заранее объявленные типизированные схемы. Пока Ixia поддерживает добавление новых индексов, не влияющих на онлайн-трафик. Эти индексы необходимо развернуть в конфигурации Muse и уровне хранения Ixia. Новые индексы могут позже быть заполнены клиентами для более старых документов. Ixia поддерживает TTL с гарантией Hbase TTL (Time To Life) и кэшем. Для сценариев, чувствительных к точности истечения срока действия TTL, когда документ кэшируется и истекает в HBase, установлен более короткий TTL кэша [1].
Администрирование кластера HBase
Код курса
HBASE
Ближайшая дата курса
26 августа, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
Архитектура индексации в реальном времени
Напомним, HBase — это колоночное NoSQL-хранилище поверх распределенной файловой системы Hadoop HDFS. Она похожа на Google BigTable и написана на Java. HBase хорошо подходит для обработки данных в реальном времени или произвольного доступа для чтения/записи к большим объемам данных. В Pinterest HBase играет роль базы данных источника достоверной информации для Ixia.
Репликация HBase — это механизм копирования данных из первичного кластера HBase в другой (вторичный). Это выполняется асинхронно путем воспроизведения записей журнала предварительной записи (WALEdits) в журнале предварительной записи (WAL, Write Ahead Log) из активного кластера на резервные серверы региона кластера. WALEdit — это объект, который представляет одну транзакцию и может иметь более одной операции мутации. Поскольку HBase поддерживает транзакции на уровне одной строки, один WALEdit может иметь записи только для одной строки.
Дата-инженеры Pinterest представили настраиваемые серверы приемников репликации HBase, которые реализуют API приемников репликации резервных кластеров. Служба приемника репликации предоставляет бизнес-логику для преобразования событий WAL в сообщения и асинхронной публикации их в Apache Kafka без изменения кода HBase. Сервер приемника репликации отправляет подтверждение (ACK) в первичный кластер источника репликации, если он может опубликовать это событие в Kafka.
Ixia, как и HBase, поддерживает строго согласованные запросы GET. Индекс обновляется только после успешного запроса записи в базу данных. Это естественное следствие инфраструктуры отслеживания измененных данных (CDC, Change Data Capture), поскольку события WAL гарантированно публикуются в службе приемника репликации и в Apache Kafka. Платформа уведомлений использует эти сообщения и отправляет запрос индексации в Muse через Ixia.
API запросов используется для поиска документов в поисковой системе с различными вариантами фильтрации на основе совпадения, сходства, диапазона и т.д., а также результаты агрегирования на основе суммы, среднего, максимума, минимума и пр. Благодаря асинхронной индексации архитектуры, API запросов в конечном итоге согласован. Задержка между временем написания документа и временем, когда он доступен для поиска, составляет около 1 секунду.
Внутренняя структура уведомлений под названием Argus получает события Kafka и запускает бизнес-логику на основе событий. Механизм приемника репликации гарантирует, что все WAL публикуются в Kafka, потребители которого выполняют определенную клиентом бизнес-логику для каждого события. Ixia использует инфраструктуру распределенного кеширования Pinterest, поддерживаемую Memcached и Mcrouter, чтобы оптимизировать производительность чтения и снизить нагрузку на HBase.
Шаблон запроса Ixia характеризуется очень высоким соотношением чтения-записи (~ 15: 1), поэтому добавление кэша позволило существенно сэкономить затраты на инфраструктуру. Каждая запись в кэше соответствует документу ixia, который, в свою очередь, соответствует строке HBase. Запросы на чтение сначала синхронно проверяются в кэше и возвращаются клиенту, если они доступны, а отсутствующие записи асинхронно заполняются обратно из хранилища источника истины. Все запросы на запись сначала удаляются из кэша, чтобы поддерживать согласованность данных Ixia. API запросов в Ixia позволяет запрашивать подмножество полей из документа. Чтобы упростить реализацию сборки документа из кэша и HBase, кэшированные записи, которые не содержат всех запрошенных полей, отклоняются и асинхронно направляются их обратно в кэш.
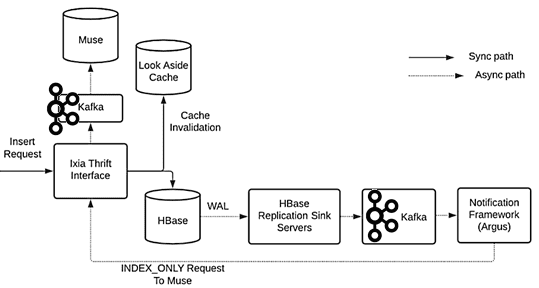
Таким образом, сквозной поток запросов выглядит так [1]:
- когда поступает запрос на вставку, обновление или удаление данных, Ixia удаляет этот ключ из кэша и синхронно выполняет запись в HBase. WAL публикуется в Kafka после репликации на серверы-приемники репликации. Платформа уведомлений Argus использует событие обновления и отправляет запрос в Ixia с флагом, который указывает сервису обновлять Muse только через Kafka.
- Ixia отправляет запрос в Muse для поиска по инвертированному индексу и выполняет прямой поиск всех ключей документов, возвращаемых Muse в HBase, чтобы убедиться в существовании документов в источнике истинны.
- Когда поступает запрос GET, Ixia получает результат прямо из базы данных и возвращает его клиентам. Этот RPC-вызов представляет собой тонкую оболочку для прямого Key/Value-доступа к Apache
Преимущества и недостатки решения в эксплуатации
Эксплуатируя Ixia в production более года, Pinterest активно использует описанную систему в разных критически важных сценариях: покупки, реклама, доверие и безопасность. Развернуты выделенные и общие кластеры в зависимости от критичности варианта использования, объема данных и пр. В частности, один из кластеров обслуживает около 40 000 запросов в секунду с зедржкой не более 5 мс для размера ответа примерно 12 КБ со SLA 99,99%. Максимальная пропускная способность всей системы составляет около 250 тысяч запросов в секунду.
Для обеспечения отказоустойчивости Ixia поддерживается двумя кластерами HBase. Активный кластер обслуживает онлайн-трафик и непрерывно реплицируется в резервный кластер. В случае отказа активного кластера есть механизмы переключения с нулевым временем простоя и активации режима ожидания без ущерба доступности. Также развернуты системы периодического создания моментальных снимков HBase и непрерывного резервного копирования WAL, чтобы обеспечить восстановление достоверных данных на определенный момент времени.
Задания MapReduce могут детерминировано получить индекс на основе моментального снимка, который можно использовать для запуска нового кластера Muse в любой момент, если источник достоверных данных не поврежден.
Однако, решение имеет некоторые недостатки [1]:
- Системная сложность из-за отсутствия поддержки вторичного индексирования в HBase – конвейер асинхронного индексирования имеет несколько компонентов, увеличивающих операционную нагрузку. Поскольку клиенты имеют большую гибкость при написании дорогостоящих запросов, дата-инженерам Pinterest необходимо устанавливать системные ограничения на различных уровнях для защиты от каскадных сбоев из-за изменений шаблона запроса. Диагностика и устранение таких сложных ошибок увеличивает стоимость обслуживания.
- Конечная согласованность — текущая архитектура не может поддерживать строгую согласованность индексов в текущей модели. Поскольку уровень API является общим с подключаемым хранилищем и backend’ами поиска, требуются другие базы данных NewSQL для использования с Ixia, которые могут поддерживать строгую согласованность и снижать сложность конвейера асинхронного индексирования.
Тем не менее, пока представленная система на базе Apache HBase активно используется в Pinterest, обеспечивая согласованную индексацию с задержкой в несколько миллисекунд и высокой доступностью (SLA 99,5%). Небольшое количество неудачных обновлений индекса регистрируется на дисках и обрабатываются позже с использованием внутренних конвейеров, которые перемещают данные с дисков в Data Lake с помощью систем «Издатель/Подписчик». Запускаются периодические автономные задания, чтобы прочитать эти неудачные проиндексированные запросы из озера данных, и повторные попытки их обработки.
Интеграция Hadoop и NoSQL
Код курса
NOSQL
Ближайшая дата курса
5 августа, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Про инкрементное резервное копирование таблиц HBase в облачное хранилище AWS S3 читайте в нашей новой статье.
Узнайте больше интересных примеров администрирования и эксплуатации Apache HBase для разработки распределенных приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

