
Аналитика больших данных для руководителей и других конечных бизнес-пользователей – это не только графические дэшборды BI-систем. Сегодня рассмотрим, что такое самообслуживаемая аналитика Big Data, какова ее польза для бизнеса и чего не стоит ждать от self-service BI.
Что такое self-service BI: определение, назначение и примеры
Еще в 2018 году исследовательское агентство Gartner анонсировало тренд на увеличение интереса к самообслуживаемой бизнес-аналитике (self-service Business Intelligence, BI). Это стало возможным благодаря росту объема информации, распространению технологий Big Data и популяризации Data Science. Кроме того, цифровизация как основная идея современного подхода к бизнесу продвигает принципы data-driven, когда управленческие решения принимаются на основе объективного анализа данных [1].
Gartner предлагает следующее определение self-service BI: аналитика самообслуживания — это форма бизнес-аналитики, где профессионалы предметной области могут самостоятельно выполнять запросы к нужным данным и генерировать обобщающие отчеты при номинальной поддержке ИТ. Аналитика самообслуживания характеризуется простыми в использовании BI-инструментами с базовыми аналитическими возможностями и упрощенной моделью данных, которая легко воспринимается и предоставляет прямой доступ к нужной информации [2].
Таким образом, self-service BI – это концепция, суть которой в предоставлении бизнес-пользователям удобного инструментария для самостоятельного и эффективного анализа данных, в зависимости от их функциональных потребностей и рабочих ролей: от простой фильтрации и группировки до модификации структуры отчетов и изменения семантических моделей. Это провоцирует уход от привычной парадигмы работы с данными, когда бизнес-аналитика централизована на корпоративном хранилище данных (КХД) и развернутых витринах (Data Mart). Гибкость self-service BI позволит пользователям создавать собственные дэшборды с теми данными, которые им необходимы в заданный промежуток времени, не привлекая ИТ-специалистов [3].
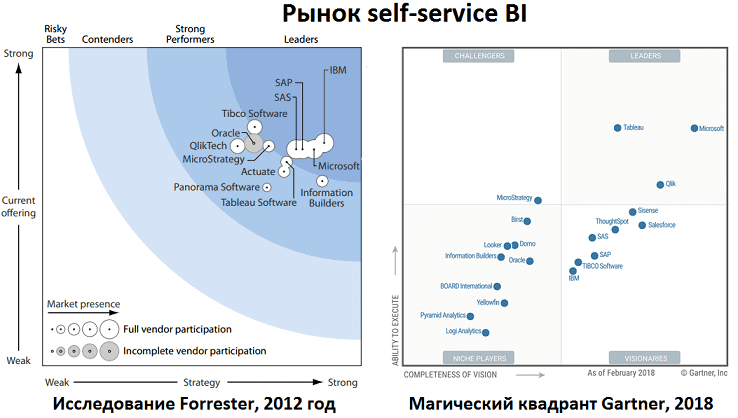
Согласно Gartner, лидерами рынка самообслуживаемой BI-аналитики в 2018 году являлись Tableau, Qlik и Microsoft Power BI [4]. Примечательно, что подобное исследование 5-летней давности от Forrester в сегмент наиболее перспективных решений включило продукты IBM, SAP, SAS и Microsoft [5]. Многие из этих продуктов активно применяются в российских и зарубежных компаниях, в т.ч. для аналитики больших данных. Однако, область Big Data накладывает некоторые ограничения на саму концепцию self-service BI, о которых мы поговорим далее.
Взгляд со стороны Big Data: самообслуживаемая аналитика в мире больших данных
На практике понятие самообслуживаемой аналитики, особенно в области Big Data, отличается от того, как это позиционируют сами вендоры BI-платформ. Прежде всего, стоит учитывать, что self-service BI, как и любая информационная система, требует предварительной подготовки перед ее использованием. В частности, многообразие форматов и источников больших данных усложняет процесс встраивания BI-системы в существующую ИТ-инфраструктуру.
Кроме того, даже наличие встроенных алгоритмов машинного обучения и прочих методов искусственного интеллекта, как это предполагает расширенная аналитика Big Data (augmented analytics), не отменяет необходимости человеческой работы, хотя бы в части корректной постановки бизнес-задач. Таким образом, self-service BI – это инструмент автоматизации процессов сбора и визуализации отдельной области предметно-ориентированных данных, а не универсальное средство оптимизации всей корпоративной деятельности для руководителя или самостоятельной генерации бизнес-инсайтов для аналитика или Data Scientist’a [6].
Системы класса SQL-on-Hadoop (Cloudera Impala, Apache Hive, Phoenix и пр.) можно рассматривать как self-service BI для анализа больших данных, хранящихся в корпоративном озере данных (Data Lake) на базе Apache Hadoop. Например, вчера мы рассматривали несколько подобных кейсов в химической и автомобильной промышленности. С другой стороны, инструментарий Big Data требует определенного уровня компетенций от своих пользователей, что несколько противоречит концепции самообслуживания без привлечения ИТ-специалистов. Впрочем, современные BI-системы, в т.ч. вышеупомянутые лидеры рынка self-service (Tableau, Qlik и Microsoft Power BI), включают коннекторы и другие специализированные решения для анализа данных, хранящихся в кластере Hadoop. Это немного облегчает развертывание и эксплуатацию BI-систем, повышая уровень самообслуживания в аналитике больших данных. Тем не менее, пока self-service BI остается лишь концепцией, которую стремятся реализовать data-driven компании с помощью технологий Big Data в рамках цифровизации своего бизнеса. В следующей статье мы продолжим разговор про self-service системы и рассмотрим, что такое самообслуживаемое машинное обучение и при чем тут AutoML.
Как это сделать на практике с максимальной эффективностью и минимальными затратами, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Аналитика больших данных для руководителей
- Cloudera Impala Data Analytics
- Интеграция Hadoop и NoSQL
- Hadoop SQL администратор Hive
- Анализ данных с Apache Spark
Источники
- https://www.gartner.com/en/newsroom/press-releases/2018-01-25-gartner-says-self-service-analytics-and-bi-users-will-produce-more-analysis-than-data-scientists-will-by-2019
- https://www.gartner.com/en/information-technology/glossary/self-service-analytics
- https://bi-survey.com/self-service-bi
- http://powerbirussia.ru/2019/02/03/self-service-bi/
- https://www.tadviser.ru/index.php/Статья:Self-Service_BI
- https://www.qleversolutions.ru/myth-of-self-service-analytics

