
В этой статье для инженеров данных и разработчиков Hadoop-приложений рассмотрим опыт индийской компании Wynk по применению Apache Flink в качестве средства потоковой аналитики больших данных пользовательского поведения в мобильных приложениях прослушивания музыки. Особое внимание уделим вопросу формирования и обработки пользовательских сессий.
Постановка задачи и выбор решения
Wynk Music является одним из популярных приложений потоковой передачи музыки в Индии. Чтобы улучшить пользовательский опыт, продакт-менеджеры и аналитики Wynk решили изучить модели прослушивания и понять, как пользователь ведет себя в каждом сеансе прослушивания музыки, а также какие факторы влияют на это поведение. При этом были поставлены следующие вопросы:
- как новый продукт или отдельная функция влияет на время сеанса;
- каковы основные причины прекращения сеансов;
- сколько сеансов создается или закрывается одномоментно.
Пользовательский сеанс или сессию можно рассматривать как период непрерывного прослушивания музыки с небольшими перерывами между ними со следующими характеристиками:
- две сессии разделены перерывом неактивности не менее 30 минут;
- сеанс длится более 30 секунд, чтобы исключить случайные запуски приложения;
- окончание суток не влияет на определение сеанса;
- перезапуск приложения из-за сбоев или удаления открывает новый сеанс.
Чтобы измерять активность пользователей, нужны маркеры, которые могут отслеживать и передавать намерения пользователя. Поскольку в Wynk уже существовала система аналитики приложений, которая дает нам к более чем 150 маркерам событий, именно она выступала в качестве отправной точки для определения требований к приложениям потоковой обработки:
- система должна быть способна обрабатывать около 2 ТБ логов событий в день, выдавая результаты почти в реальном времени;
- поддержка нескольких версий мобильных клиентов для Android и iOS, а также веб-сайтов. Каждый клиент отправляет динамическую полезную нагрузку с логом событий.
- способность к быстрому восстановлению в случае сбоя любого компонента без потери данных.
Из-за невозможности контролировать, когда клиент будет отправлять логи событий, все клиентские реализации буферизуют события в течение короткого периода времени перед их отправлением, чтобы уменьшить количество вызовов API к серверной системе. Например, если клиент отключается до отправки пакета с логами событий, этот пакет будет поступать для обработки всякий раз при подключении клиента к сети. Построение полностью точной системы в таком сценарии потребует огромных ресурсов. Поэтому в качестве компромисса 100% точность не требуется, однако, stateful-приложение потоковой обработки должно давать результаты, близкие к реальному времени.
В качестве фреймворка, позволяющего реализовать приложение согласно указанным требованиям ИТ-специалисты Wynk выбрали Apache Flink, благодаря наличию в нем следующих функциональных возможностей:
- обработка данных в пакетном и потоковом режимах;
- механизм контрольных точек, о чем мы писали здесь;
- способность создавать различные дополнительные потоки вывода.
Все клиенты Wynk отправляют журналы событий серверной службе через API. Backend запускает Logstash, который перенаправляет эти события в кластер Kafka. Задание Flink считывает события из топика Kafka и назначает каждому событию идентификатор сеанса.
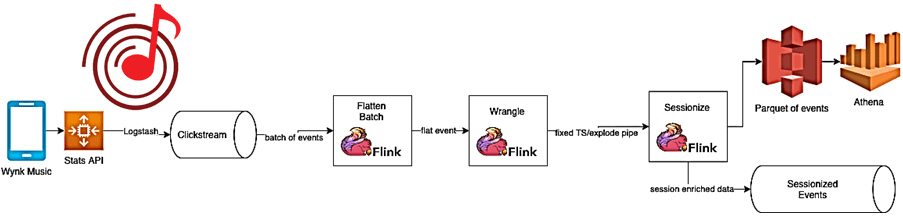
Как работает представленная архитектура потокового Flink-приложения, рассмотрим далее.
Потоковая обработка событий с Apache Flink: особенности операторов
Для распределенного выполнения заданий Flink, подобно Apache Spark, использует концепцию направленного ациклического графа (DAG, Directed Acyclic Graph) – цепочки работ из нескольких зада. Каждая задача выполняется одним потоком, а для оптимизации подзадачи оператора объединяются в задачи, что снижает накладные расходы на передачу обслуживания между потоками и буферизацию, а также увеличивает общую пропускную способность при одновременном снижении задержки.
Работу приложения Wynk обеспечивает потоковый конвейер из следующих операторов Flink:
- Оператор преобразования (Transformation Operator), который поддерживает структурную целостность данных, выполняя фильтрацию и очистку данных, чтобы сделать их пригодными для дальнейшей обработки. Здесь исправляются структурные ошибки, обрабатываются отсутствующие значения и проверяется качество данных, чтобы избежать ненужных накладных расходов на вычисления в следующих операторах.
- Оператор обработки (Wrangler Operator), который обрабатывает все операции во временной области, назначая временные метки и водяные знаки входным данным, чтобы сопоставить время обработки события приложением с временем фактического создания события. В реальности из-за сетевых задержек или сбоев эти временные метки отличаются друг от друга. Кроме того, в распределенной системе события могут поступать не по порядку, поэтому нужна дополнительная задержка в ожидании этих событий, что дополнительно влияет на время обработки. Здесь же отсеиваются события, в которых разница между временем события и текущим водяным знаком больше определенной временной дельты. Наконец, Wrangler-оператор сохраняет состояние окон предыдущих сеансов для событий, прибывающих с опозданием, но в пределах временной разницы, и назначает событие его окну с соответствующими временными рамками.
- Оператор сеанса (Session Operator) реализует саму суть бизнес-логики, разделяя события на временные когорты, которые и представляют собой сеансы. Это результат работы всего Flink-конвейера, полученный с помощью DataStream API.
Хотя у Flink есть оконный API для объединения данных в сеансы, он не слишком удобен. Поэтому разработчики Wynk решили реализовать собственный оператор окна сеанса с помощью KeyedProcessFunction:
var timerState: ValueState[Long] = _ var sessionState: ValueState[GenericRecord] = _ var closedSessions: ListState[GenericRecord] = _val STATE_SERIALIZER: AvroSerializer[GenericRecord] = _val MAX_SESSION_GAP: Long = Time.minutes(30).toMilliseconds
Здесь поддерживается 3 состояния для каждого ключевого события;
- состояние таймера (timer state) показывает время последнего увиденного события для этого ключа, чтобы проверить, выходит ли текущее событие за пределы сеанса или нет
eventTimestamp — timerState.value().get > MAX_SESSION_GAP
- состояние сессии (sessionState) содержит текущий объект сеанса и поддерживает список закрытых сеансов, где каждый имеет TTL, равный максимально допустимому времени задержки события;
- устаревшие состояния (Stale state) периодически очищаются путем регистрации таймера времени обработки, который запускает метод onTimer, предоставляемый функцией KeyedProcessFunction:
context.timerService().registerProcessingTimeTimer(currentTime + CLEAN_UP_INTERVAL)
Обогащенные сеансом события выводятся в два основных приемника топик Kafka в реальном времени и файл Parquet. Также собираются соответствующие метаданные, такие как данные сеанса, сообщения об ошибках, события не по порядку в различных побочных выводах. Например, следующий код показывает, как приложение-потребитель может считывать из топика Kafka обогащенные события:
val kafkaConsumer: KafkaSource[Event]val source: DataStream[Event] = env.fromSource(kafkaConsumer, WatermarkStrategy.noWatermarks(), "Events")source .process(new EventTransformationProcess) .assignTimestampsAndWatermarks(new CustomWatermarkStrategy) .keyBy(EventKeySelector) .process(new SimpleEventTimeWrangler) .keyBy(EventKeySelector) .process(new Sessionizer)
Поскольку Apache Flink разрешает доступ только к состояниям в KeyedStream, необходимо разделить поток по логическому ключу. Это гарантирует, что данные, соответствующие определенному ключу, всегда обрабатываются в одной и той же подзадаче. Оператор KeyBy вводит дополнительные сетевые буферы между последовательными подзадачами. Это приводит к более равномерной обработке переполнения противодавления от нижестоящих подзадач.
При загрузке данных на операторы целесообразно проверить, что:
- логический ключ, используемый для партиционирования, не вызывает искажения данных. Обычно ключи с высокой кардинальностью, такие как userID или deviceID, являются подходящим выбором в качестве ключа раздела.
- значение maxParallelism кратно параллелизму. Для абсолютно равномерного распределения
no of key groups (maxParallelism) = k * num operators (parallelism)
В дополнение к основному потоку, который является результатом операций DataStream, также можно создавать любое количество дополнительных выходных потоков, типы данных в которых могут отличаться от основного потока. Это полезно, когда нужно разделить поток данных, чтобы реплицировать его, а затем отфильтровывать из каждого потока ненужные данные. Про динамическое изменение условий фильтра без перезапуска потокового приложения читайте в нашей новой статье.
Для защиты данных от потери и обеспечения последовательного восстановления после сбоев заданий Flink поддерживает технологию моментальных снимков (snapshot) состояния приложения. Фреймворк предлагает две готовые конфигурации серверной части состояния:
- HashMapStateBackend — сохраняет данные в виде объектов Java в памяти. Размер состояния ограничен общим объемом памяти, доступной в кластере.
- EmbeddedRocksDBStateBackend — хранит данные в виде сериализованных массивов байтов в базе данных RocksDB, о чем мы писали здесь. Размер состояния в этом случае ограничен общим доступным дисковым пространством.
С точки зрения производительности бэкенд состояния HashMap быстрее RocksDB, поскольку не требует десериализации/сериализации для чтения/сохранения данных с диска при обращении к ним. Однако, HashMapStateBackend ограничен общей доступной памятью, что влияет на производительность, особенно во время контрольных точек, когда все состояние приложения необходимо агрегировать в диспетчере заданий перед сохранением в файловой системе. Поэтому в приложении Wynk из-за большого количества ключей в потоке используется EmbeddedRocksDBStateBackend в качестве бэкенда состояния. А чтобы обеспечить полную эволюцию схем всех объектов перед сериализацией они преобразуются в общую запись AVRO.
После развертывания рассмотренного Flink-приложения в кластере AWS EMR были получены ответы на некоторые изначально поставленные вопросы относительно пользовательского опыта:
- средняя продолжительность сеанса колеблется от 20 до 25 минут;
- в среднем пользователи слушают около 6–8 песен за сеанс;
- в часы пик музыкальным стриминговым сервисом пользуются более миллиона человек – таково количество одновременно активных сеансов.
Больше подробностей про администрирование и эксплуатацию Apache Flink, а также другие технологии потоковой обработки событий для распределенных приложений аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

