
Дополняя наши курсы дата-инженеров полезными примерами, сегодня рассмотрим, как упростить разработку и мониторинг ETL-конвейеров с помощью дополнительных технологий Big Data, совместимых с Apache Spark. Читайте далее, когда и зачем инженеру данных пригодятся SaaS-продукт Prophecy.io, движок StreamSets Transformer и REST-интерфейс Apache Livy, а также как все они связаны со Spark.
3 проблемы Apache Spark для инженера данных
При работе с Apache Spark инженер данных может столкнуться со следующими трудностями [1]:
- высокий порог входа в технологию – необходимо понимать особенности распределенной обработки данных в Спарк-кластере, знать возможности оптимизации конфигурационных настроек для заданий и задач, а также разбираться в тонкостях Java-кода;
- эффективная эксплуатация конвейера Spark-приложений и ETL-процессов в production требует полноценного инструментария для их разработки, тестирования, развертывания и мониторинга, что невозможно реализовать только в рамках самого фреймворка;
- при использовании Apache Spark в изолированной среде Amazon EMR из-за ограничений безопасности невозможно напрямую получить доступ к главному узлу Spark с внешнего компьютера, например, чтобы передать jar-файлы приложений через AWS S3 [2].
Решить все эти и другие проблемы помогут специализированные надстройки над Apache Spark и средства инженерии Big Data, о которых мы поговорим далее.
Не только StreamSets: что такое Prophecy.io и зачем это нужно
Мы уже писали о популярной ETL-платформе StreamSets Data Collector и возможностях ее исполнительного движка StreamSets Transformer для запуска конвейеров обработки данных в кластерах Apache Spark, включая различные дистрибутивы Hadoop. Однако, это далеко не единственный продукт на базе Спарк с наглядным GUI. С учетом тренда на демократизацию технологий Big Data активно развиваются SaaS-решения, упрощающие процессы инженерии больших данных. Одним из них является Prophecy.io, основанный на Спарк и Kubernetes для командной инженерии корпоративных данных и замены устаревших проприетарных ETL-продуктов. Prophecy в первую очередь позиционируется как средство НЕ для разработчиков (low code) – пользователю не нужно знать особенности Spark, чтобы создать собственный конвейер обработки данных: задачи определяются в визуальном интерфейсе и соединяются с помощью механизма drag-and-drop. А для спецификации некоторых выражений используется встроенный SQL-редактор. Кроме того, продукт поддерживает принципы DevOps и Agile, предоставляя средства разработки кода на Scala и Python, тестов, непрерывной интеграции и развертывания. Планирование рабочих процессов обеспечивается с помощью Apache Airflow [1].
Обратной стороной этого удобства эксплуатации является снижение контроля и свободы конфигурирования. Используя любое low-code решение, инженер данных ограничен возможностями его интерфейса и не может глубоко погрузиться в код, чтобы оптимизировать data pipeline, например, настроив некоторые конфигурации заданий, как мы разбирали здесь. Впрочем, с аналогичными ограничениями можно столкнуться и при работе с так называемым native Spark, развернутом в облачном кластере, что рассмотрим далее. А о комплексных Big Data платформах на базе Спарк читайте в нашей следующей статье, где мы разбираем, что такое SnappyData (TIBCO ComputeDB).
Роль Apache Livy в инженерии Big Data
О типовых сценариях совместного использования Apache Livy со Спарк в инженерии Big Data мы писали здесь и здесь. Напомним, эта служба работает как агент Spark, обеспечивая взаимодействие с кластером через REST-интерфейс, включая отправку заданий, запросов или других фрагментов кода, синхронное или асинхронное получение результатов, а также управление контекстом и единую сессию для нескольких клиентов. А благодаря наличию Apache Zeppelin в качестве интерпретатора код можно писать непосредственно в записной книжке и выполнять через REST API, без самостоятельной обработки HTTP-запросов в стиле гибкой разработки на Python. Именно поэтому связка Spark + Livy + Zeppelin проста в настройке и удобна использовании. Дата-инженер может обращаться к Spark через Livy в роли HTTP-прокси, даже если сам кластер недоступен напрямую, например, при его развертывании во внешнем облаке [2].
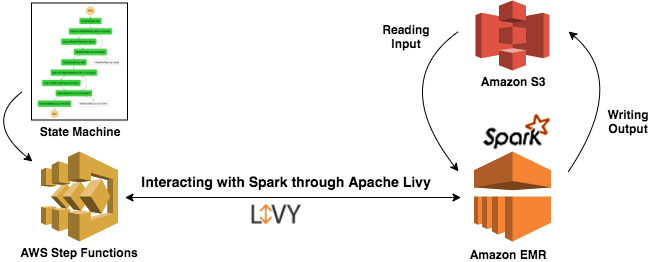
А если нужно всего лишь запустить в облаке AWS несколько заданий Spark в определенном порядке, но не тратить время на их организацию или поддержку отдельного приложения, это можно сделать это без сервера с помощью AWS Step Functions. Достаточно создать весь рабочий процесс в AWS Step Functions и взаимодействовать со Spark в Amazon EMR через Apache Livy [3].
Узнайте больше об эффективных инструментах современного инженера данных для работы с Apache Hadoop и Spark на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Hadoop для инженеров данных
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
Источники
- https://medium.com/prophecy-io/prophecy-saas-low-code-data-engineering-for-your-spark-free-for-small-teams-a83657a9aa7e
- https://medium.com/@takezoe/try-apache-spark-from-apache-zeppelin-via-apache-livy-e6d38064a83b
- https://aws.amazon.com/ru/blog/big-data/orchestrate-apache-spark-applications-using-aws-step-functions-and-apache-livy/

