
Вчера мы упоминали, что с марта 2021 года в версии Apache Spark 3.1.1 с развертывания на Kubernetes снят экспериментальный режим, внесено множество улучшений для стабильной работы контейниризованных приложений и добавлены другие полезные обновления. Читайте далее, почему развертывание Spark на Kubernetes стало еще проще, как реализуется плавное завершение работы узла без потери данных, зачем нужны дополнительные способы монтирования томов и в чем суть других фич нового релиза.
Apache Spark on Kubernetes: 7 новинок релиза 3.1.1
С точки зрения практического развертывания Спарк-приложений в кластере Kubernetes (K8s) релиз Apache Spark 3.1.1, выпущенный в марте 2021 года, особенно выделяется, поскольку в нем устранены многие недостатки такого совместного использования этих технологий Big Data, о которых мы рассказывали здесь. Это второй выпуск линейки 3.x, где добавлены аннотации типов Python и поддержка управления Python-зависимостями, улучшено соответствие Spark SQL стандарту ANSI, реализован сервер истории для Structured Streaming для отображения статистики выполненных запросов структурированной потоковой передачи в пользовательском интерфейсе после завершения работы приложения. Но наиболее важным из 1500 обновлений для DevOps-инженера и разработчика Spark-приложений стала общая доступность (GA, General Availability) Kubernetes и снятие экспериментального режима с этого варианта развертывания благодаря следующим возможностям [1]:
- плавный вывод из эксплуатации (завершение работы) узлов Kubernates и Standalone без потери данных;
- монтирование томов Kubernetes NFS;
- динамическое создание и удаления PVC;
- учет переменных среды и конфигураций для исполняемых файлов Python, а также поддержка зависимостей;
- настраиваемые тайм-ауты исполнителя в распределении по подам с ExecutorPodsAllocator;
- планирование с ожидающими подами на уровне этапа, чтобы контролировать в коде количество и тип ресурсов исполнителя, позволяя настроить ресурсы приложения на каждом шаге. Например, разные типы процессоров для ETL и тренировки моделей машинного обучения.
- поддержка JDBC Kerberos.
Некоторые из этих новых возможностей мы подробнее рассмотрим далее.
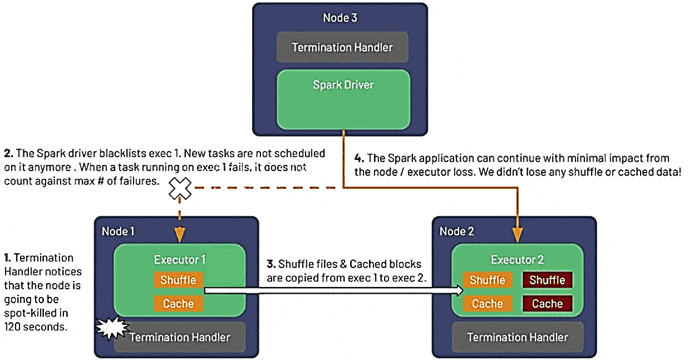
Graceful shutdown для исполнителей Спарк в K8s
О том, как плавное завершение (Graceful shutdown) заданий Apache Spark при потоковой обработке событий с помощью библиотеки Structured Streaming предотвращает потерю данных, мы писали здесь и здесь. В релизе 3.1.1 аналогичная функция доступна и для Kubernetes, позволяя Spark предвидеть точечные остановы и корректно завершать работу исполнителей без потери их перетасовки и кэшированных данных еще до того, как они будут прерваны. Это дает следующие преимущества [2]:
- повышение надежности и производительности распределенных приложений за счет перемещения кэшированных и shuffle-данных с узлов, которые будут выведены из эксплуатации;
- сокращение времени вычислений благодаря отсутствию повторного запуска задач в случае точечного отказа отдельных узлов, где велась обработка данных;
- отсутствие необходимости в отдельной совместимой с Kubernetes внешней shuffle-службы, которая корректную работу дорогостоящих узлов хранения по требованию (on-demand).
Работу этой функции можно описать так [2]:
- уходящий исполнитель заносится в «черный список», чтобы драйвер Spark не планировал для него новые задачи. При этом выполняющиеся на нем задачи не прерываются принудительно, но, в случае неудачного завершения из-за останова исполнителя, они будут повторены на другом исполнителе, а их сбой не будет учтен в итоговой сумме отказов.
- Shuffle-файлы и кэшированные данные из удаленного исполнителя переносятся на другой исполнитель или резервное хранилище, например, AWS S3;
- после переноса данных исполнитель останавливается, а приложение Spark продолжать успешно работать.
Функция плавного останова включается в следующих ситуациях [2]:
- в случае точечных/вытесняемых узлов, о чем предупреждает облачный провайдер (AWS, GCP, Azure), выдав уведомление за 60–120 секунд. Этот период времени позволяет Spark перенести shuffle-файлы и сохранить данные, даже если экземпляр облачного провайдера выходит из строя по другим причинам, например, по событиям обслуживания AWS EC2;
- узел Kubernetes выведен из эксплуатации, например, для настройки или под исполнителя Spark исключен, будучи вытеснен подом с более высоким приоритетом;
- бездействующий исполнитель удален или исключен динамическим распределением при масштабировании кластера в меньшую сторону.
Для включения функции плавного завершения исполнителей необходимо настроить 4 основных конфигурации Spark:
- decommission.enabled
- storage.decommission.rddBlocks.enabled
- storage.decommission.shuffleBlocks.enabled
- storage.decommission.enabled
А чтобы получать от облачного провайдера предупреждающие уведомления, необходимо вручную настроить интеграции с проектом NodeTerminationHandler для AWS, GCP и Azure.
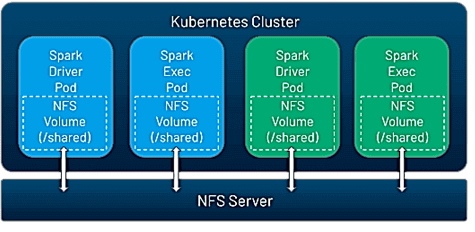
2 новых тома для обмена данными между разными приложениями
Начиная с версии 2.4, можно монтировать 3 типа томов при использовании Spark в Kubernetes [2]:
- emptyDir – изначально пустой каталог для временного хранения данных, ограниченный временем жизни пода на диске узла, твердотельном накопителе или сетевом хранилище;
- hostpath для подключения каталога из базового узла к поду;
- статический PersistentVolumeClaim (PVC) – предварительно созданный файл, абстракция Kubernetes для различных типов постоянных хранилищ, таких как AWS EBS, Azure Disk или постоянные диски Google Cloud Platform. PersistentVolumeClaim должен быть создан пользователем заранее, и его жизненный цикл не привязан к поду.
Spark 3.1 включает два новых параметра: NFS (Network File System, сетевая файловая система) и динамический PVC. NFS подходит для обмена данными между всеми Spark-приложениями – том, который может совместно использоваться многими подами одновременно и может быть предварительно заполнен данными. Это позволяет обмениваться данными, кодом, конфигурациями между приложениями Spark, а также между драйвером и исполнителем в рамках отдельного задания.
Kubernetes не запускает сервер NFS, поэтому его нужно запустить самостоятельно или использовать облачный сервис, например, AWS EFS, GCP Filestore или Azure Files. Как только создан общий ресурс NFS, его можно смонтировать в приложения Spark 3.1, используя конфигурации:
- kubernetes.driver.volumes.nfs.myshare.mount.path=/shared
- kubernetes.driver.volumes.nfs.myshare.mount.readOnly=false
- kubernetes.driver.volumes.nfs.myshare.options.server=nfs.example.com
- kubernetes.driver.volumes.nfs.myshare.options.path=/storage/shared
Динамический PVC — это просто более удобный способ использования постоянных томов. Теперь не требуется предварительное создание PVC, их монтирование и самостоятельная очистка. При отправке приложения Spark или запросе новых исполнителей во время динамического распределения в Kubernetes динамически создаются PVC. Они автоматически подготавливают новые постоянные тома (PersistentVolumes) для запрошенных классов хранилища: AWS EBS, Azure Disk или постоянные диски GCP. Когда под удаляется, связанные ресурсы автоматически уничтожаются.
Освойте практику эффективной аналитики больших данных с Apache Spark на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

