
Продолжая разговор про практическое обучение разработчиков Apache Spark, сегодня рассмотрим пример повышения скорости выполнения SQL-запросов к большому датафрейму. Читайте далее, как определить и исправить асимметрию распределения данных по разделам, зачем добавлять контрольные точки в длинные DAG и в чем здесь опасность, чем хороша широковещательная трансляция, для чего фильтровать данные перед shuffle-операциями, а также что общего между методами cache(), count() и show().
4 проблемы выполнения SQL-запросов на большом датафрейме в Apache Spark и их решения
Рассмотрим пример с обработкой большого датафрейма с таблицей из 10 миллиардов записей о транзакциях по кредитным картам всех пользователей за последний год. Предположим, необходимо найти кредитные карты, которые использовались чаще всего за последние 3 месяца и получить записи всех транзакций по ним за прошедший год. Эту задачу можно разделить на 2 этапа [1]:
- фильтрация всей таблицы, чтобы найти записи транзакций за последние 3 месяца с использованием методов groupBy() и aggregation() для получения наиболее часто используемых кредитных карт каждого пользователя;
- join-соединение таблицы наиболее часто используемых кредитных карт с полной таблицей всех транзакций.
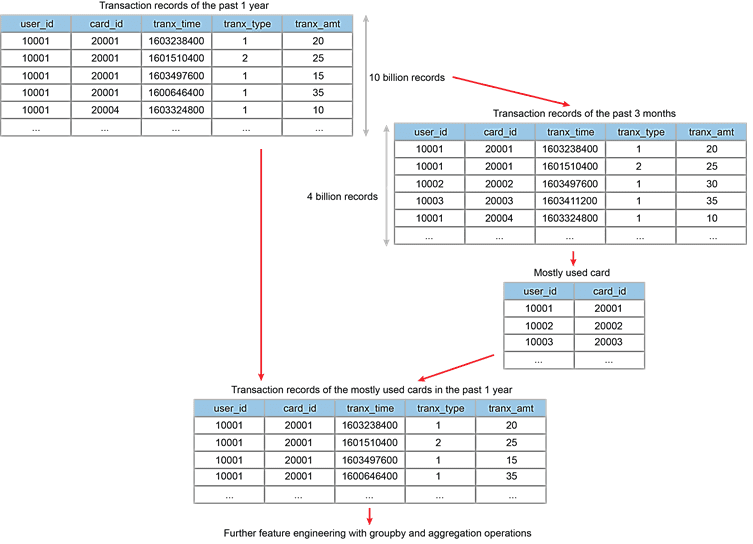
Чтобы ускорить обработку такого большого датафрейма в Apache Spark, необходимо выявить и устранить потенциальные причины торможения с помощью следующих способов [1]:
- проверка асимметрии или перекоса (skew) данных, связанные с неравномерным распределением разделов и перемешиванием (shuffle). Это можно сделать в веб-интерфейсе YARN во время выполнения задачи. Например, несколько этапов состоят из 200 разделов, 199 из которых обрабатываются очень быстро, а последний 1 раздел – долго. В рассматриваемом кейсе применяются shuffle-операции группировки и агрегации. Если исходная таблица транзакций перекошена, то эти операции будут выполняться долго из-за несбалансированной рабочей нагрузки. Проблема асимметрии данных при этих операциях может быть связана с отсутствием значений в ключевом столбце user_id. В этом случае следует отфильтровать исходную таблицу, удалив записи с NULL user_id.
- определить длину пути происхождения данных по виду DAG и понять, когда отказ одного раздела на ранних стадиях вызывает перерасчет всех цепочки более поздних стадий. Добавление контрольной точки (checkpoint) помогает сократить длинный путь к происхождению и сократить время выполнения. Однако, этим способом стоит пользоваться осторожно, о чем мы поговорим далее. В рассматриваемом примере получение наиболее часто используемой кредитной карты занимало много времени, из-за перетасовки больших датафреймов и использования оконных функции Spark SQL. Добавление контрольной точки в таблицу наиболее часто используемых кредитных карт обеспечивает запись промежуточных данных в надежное хранилище Hadoop HDFS, переключая механизм репликации со Spark. Таким образом, более поздние этапы также проходят быстрее.
- широковещательная трансляция небольшого датафрейма при соединении с большим, чтобы избежать перемещения между разделами из-за random-join. Broadcasting малого датафрейма позволяет узлам выполнять соединение в памяти для каждого раздела, избегая перемешивания большого датафрейма.
- фильтрация данных перед shuffle-операциями, чтобы уменьшить размер передаваемых по сети датафреймов и повысить общую производительность Spark-приложения.
Анализ данных с Apache Spark
Код курса
SPARK
Ближайшая дата курса
13 мая, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
Контрольные точки, кэширование и запись промежуточных результатов на диск
Поскольку задания Spark-конвейера могут продолжительными и сложными, с тяжеловесными вычислениями, например, работа с окнами по идентификатору перед соединением с основным датафреймом, сохранение промежуточных результатов целесообразно по следующим причинам [2]:
- повышение отказоустойчивости – в случае внезапного сбоя не придется начинать вычисления заново;
- отслеживание происхождения данных, т.к. некоторые методы преобразования «обрезают» его, чтобы предотвратить сбой приложений из-за нехватки памяти.
Одной из лучших практик оптимизации заданий Apache Spark является кэширование данных, с которыми выполняется несколько действий. Рекомендуется после метода cache() добавить действие count(), чтобы запустить кэширование немедленно. Метод count() принудительно помещает содержимое всего датафрейма в память, в отличие от метода show(), который кэширует только часть датафрейма.
Как уже было упомянуто выше, для сокращения логических планов в Apache Spark SQL используются контрольные точки. Это полезно, когда логический план становится очень большим, например, в итеративных объединениях, вызывающих ошибки нехватки памяти (OOM, OutOfMemory), о которых мы писали здесь. Этот способ медленнее, чем кэш, т.к. результаты фиксируются на диске. Работать с checkpoint’ами можно через API нескольких структур данных Apache Spark: RDD и DataFrame. При этом RDD настоятельно рекомендуется сохранять в памяти, т.к. сохранение в файле потребует повторного вычисления. Однако, промежуточные контрольные точки следует с осторожностью, так как это может помешать оптимизации SQL-запросов через встроенный в Apache Spark модуль Catalyst, о котором мы рассказывали здесь. Чтобы в полной мере воспользоваться преимуществами хранения промежуточных результатов с записью на диск, важно использовать кластерную архитектуру с надежной локализацией.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
13 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Узнайте больше про возможности Apache Spark для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

