
Сегодня мы рассмотрим еще один инструмент стека SQL-on-Hadoop: Apache Phoenix, позволяющий выполнять SQL-запросы к нереляционной СУБД HBase. Читайте в нашей статье, что представляет собой этот исполнительный механизм, как он работает и чем отличается от других Big Data решений подобного класса (Cloudera Impala, Apache Hive и Drill). Также мы собрали для вас некоторые практические примеры использования Apache Phoenix в реальных проектах аналитической обработки больших данных.
Что такое Apache Phoenix и как он работает с HBase
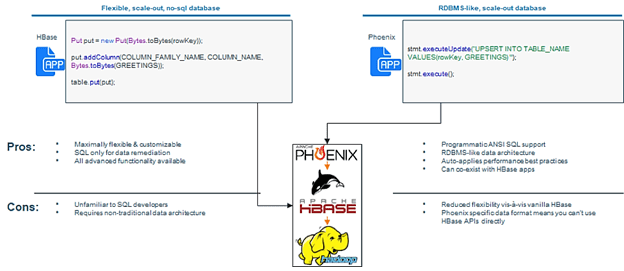
Phoenix (Феникс) – это проект верхнего уровня фонда Apache Software Foundation (c 2014 года), механизм параллельной реляционной базы данных с открытым исходным кодом, который поддерживает обработку транзакций в реальном времени (OLTP, Online Transaction Processing) в Hadoop с использованием NoSQL-СУБД HBase в качестве резервного хранилища. В отличие от Apache Hive, Феникс компилирует SQL-запросы в собственные API-интерфейсы NoSQL, не используя MapReduce, что позволяет создавать быстрые Big Data приложения с низкой временной задержкой (low latency), работающие с нереляционными хранилищами данных.
Соединение с кластером HBase выполняется через JDBC-драйвер, что позволяет работать с NoSQL-хранилищем как с реляционной СУБД, позволяя пользователям создавать, удалять и изменять таблицы, представления, индексы и последовательности, а также вставлять и удалять строки по отдельности и целыми группами. Apache Phoenix выполняет SQL-запрос, компилирует его в серию сканирований HBase и запуская их напрямую через API HBase. Благодаря непосредственному использованию API HBase, сопроцессоров и пользовательских фильтров Феникс может достигать производительности порядка миллисекунд для небольших SQL-запросов или секунд для десятков миллионов строк [1].
Администрирование кластера HBase
Код курса
HBASE
Ближайшая дата курса
26 августа, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
Поскольку Phoenix завязан на HBase, он использует многие концептуальные понятия этой СУБД, относящейся к категории «семейство столбцов» (wide-column store). В частности, Феникс поддерживает регионирование – горизонтальное объединение определенного количества строк таблицы. Напомним, в HBase таблица изначально состоит из одного региона, который по мере роста разбивается на новые и распределяется по узлам кластера. Если таблица оказывается слишком большой для одного узла, она обслуживается кластером серверов, на каждом узле которого размещается подмножество регионов таблицы. Также регионы обеспечивают распределение нагрузки на таблицу. Совокупность отсортированных регионов, доступных по сети, образует общее содержимое таблицы [2]. Phoenix позволяет контролировать количество регионов, в которых распределяются данные, что может значительно увеличить производительность при операциях чтения и записи [3].
Чем хорош Phoenix: ключевые достоинства и основные отличия от Cloudera Impala, Apache Hive и Drill
Из наиболее важных характеристик Phoenix стоит отметить следующие [1]:
- обновляемые представления поверх таблиц с возможностью добавления столбцов к ним. Все представления все имеют одну и ту же базовую физическую таблицу HBase и могут даже индексироваться независимо.
- multitenancy – многопользовательская поддержка, когда представление с несколькими пользователями может добавлять столбцы, определенные исключительно для этого пользователя;
- динамическое определение схемы данных позволяет определять столбцы во время исполнения SQL-запроса, как в Apache Drill, о чем мы рассказывали здесь. Это особенно полезно, если все столбцы неизвестны заранее, до создания запроса.
- ACID-поддержка транзакций (Atomicy, Consistency, Isolation и Durability – Атомарность, Согласованность, Изоляция и Долговечность), как в Apache Hive, стала доступна в Феникс с версии 4.7.0 и обеспечивается специальным диспетчером транзакций, включенным в дистрибутив. Напомним, Cloudera Impala и Apache Drill не поддерживают транзакции.
- вторичное индексирование для повышения производительности HBase. Индекс Phoenix — это таблица HBase, в которой хранятся копии некоторых или всех данных индексированной таблицы. Вторичные индексы повышают производительность операций чтения, т.к. вместо полного сканирования таблицы выполняется конкретный поисковой запрос. При этом увеличивается пространство хранения и ухудшается скорость записи. Выделяют охватывающие (данные из записей и индексированные значения) и функциональные (позволяют создавать индексы для произвольного выражения, которое будет использоваться в SQL-запросах) вторичные индексы [3]. Отметим, что Impala ограниченно поддерживает индексацию, в отличие от Hive, Drill и Феникс.
Hadoop SQL администратор Hive
Код курса
HIVE
Ближайшая дата курса
по запросу
Продолжительность
8 ак.часов
Стоимость обучения
24 000 руб.
Наконец, выделим главное отличие Phoenix от Cloudera Impala, Apache Hive и Drill: при том, что все эти продукты можно условно отнести к стеку SQL-on-Hadoop, Apache Phoenix предназначен специально для HBase, тогда как Hive и Impala могут работать в том числе и другими распределенными файловыми системами, помимо HDFS, например, Amazon S3, а Drill вообще позиционируется как средство для работы с любыми файловыми хранилищами и базами данных. Кроме того, если Hive, Impala и Drill могут рассматриваться еще и в качестве ETL-инструментов, то Феникс больше предназначен для построения корпоративных хранилищ данных (DWH, DataWareHouse) и реализации BI-задач (Business Intelligence).
Что касается быстроты работы, то Феникс считается достаточно быстрым инструментом, позволяющим анализировать данные с помощью SQL-запросов практически в режиме реального времени благодаря прямой работе с API HBase и механизму вторичного индексирования, который мы описали выше.
Где и как используется Phoenix в SQL-on-Hadoop для аналитики Big Data
Несмотря на сравнительную молодость технологии, Phoenix достаточно широко применяется в масштабных Big Data системах. В частности, китайская ИТ-компания Sogou использует Феникс с 2015 года в 2-х направлениях [4]:
- Бизнес-аналитика (BI, Business Intelligence): связка HBase + Phoenix для хранения миллиарда записей рекламной биржи и формирования многомерных статистических аналитических отчетов, чтобы предоставлять рекламодателям полную информацию для принятия управленческих решений с целью максимизации их инвестиционного дохода.
- Технологическая инфраструктура: платформа мониторинга и отслеживания распределенных услуг на базе HBase + Phoenix для непрерывного сбора различных метрик и журналов (около 100 тысяч записей в секунду) благодаря высокой производительности Феникс позволяет генерировать статистику для измерения работоспособности системы и анализа взаимной зависимости услуг.
Американская компания HomeAway, один из мировых лидеров в сфере аренды жилья, использует Phoenix в качестве SQL-абстракции для HBase, чтобы генерировать статистику на дэшбордах владельцев жилья. Эти статистические данные помогают владельцам недвижимости, которые сдают свои дома и квартиры в аренду с помощью HomeAway, получить представление об эффективности своих сделок, включая отображение исторических данных и картину по рынку в целом. Из пула миллиардов записей, накопленных за последние 2 года, HomeAway может обслуживать ориентированные на клиентов веб-страницы из HBase, используя Phoenix, менее чем за секунду. С помощью Phoenix и HBase HomeAway делится собственными взглядами на рынок аренды жилья со своими пользователями, предоставив им необходимые данные для принятия правильных решений, увеличивающих отдачу от инвестиций в аренду [4].
Интеграция Hadoop и NoSQL
Код курса
NOSQL
Ближайшая дата курса
5 августа, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Другая американская компания по разработке ПО, Sift Science с помощью Феникс обслуживает инфраструктуру OLAP при работе с моделями машинного обучения (ML, Machine Learning). Простой SQL-интерфейс позволяет раскрывать данные за пределами организации, а использование Phoenix поверх существующей инфраструктуры HBase дает возможность масштабировать специальные запросы. Подобным образом для real-time аналитики Big Data с помощью SQL-запросов Apache Phoenix применяется в Alibaba, eBay, Teoco, PubMatic, Interset, Socialbakers и множестве других предприятий по всему миру [4]. Пример того, как это делается в компании Vimeo, читайте здесь.
В следующей статье мы рассмотрим еще больше случаев прикладного использования Apache HBase. А все технические особенности аналитики больших данных разбираются на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Администрирование кластера HBase
- Hadoop SQL администратор Hive
- Cloudera Impala Data Analytics
- Интеграция Hadoop и NoSQL
Источники

