
Ранее мы писали о том, как фотохостинг Pinterest с помощью новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, объединяет пакетную и потоковую аналитику больших данных, чтобы еще лучше обслуживать более 475 миллионов своих пользователей. Сегодня поговорим про контроль сетевого трафика и синхронизацию источников данных через генерацию водяных знаков для потока сообщений из топиков Kafka.
Синергия Apache Flink и Kafka: еще раз про водяные знаки и не только
Напомним, фотохостинг Pinterest используется не только в качестве площадки для размещения фотографий. Это целая социальная сеть, которая позволяет оценивать изображения и группировать их в различные тематические коллекции. Ежедневно Pinterest привлекает миллионы пользователей и рекламодателей со всего мира. В качестве основного stateful-инструмента потоковой аналитики больших данных используется Apache Flink. Благодаря тому, что в Apache Flink 1.14 сделан шаг к объединению парадигм потоковой и пакетной обработки информации, о чем мы писали здесь, дата-инженеры Pinterest также пытаются объединить онлайн-события с историческими данными.
Flink выполняет пакетные программы как частный случай потоковых программ, где потоки ограничены, т.е. имеют конечное число элементов. Структура данных DataSet внутренне обрабатывается как поток. Поэтому потоковые концепции применимы к пакетным программам с небольшими исключениями:
- отказоустойчивость для пакетных программ не использует контрольные точки. Восстановление происходит при полном воспроизведении потоков, т.к. входы ограничены. Это увеличивает затраты на восстановление, но удешевляет регулярную обработку, поскольку позволяет избежать контрольных точек.
- Stateful-операции в DataSet API используют упрощенные структуры данных в памяти/вне ядра, а не индексы ключ/значение.
- API DataSet вводит специальные синхронизированные на основе супершагов итерации, которые возможны только в ограниченных потоках.
Потоковому процессору, поддерживающему время события, нужен способ измерения хода времени события. В частности, оконный оператор, который строит почасовые окна, должен быть уведомлен, когда время события прошло больше часа, чтобы оператор мог закрыть текущее окно. При этом время события может меняться независимо от времени обработки. Например, в одной программе текущее время события оператора может немного отставать от времени обработки с учетом задержки в получении событий, тогда как обе выполняются с одинаковой скоростью. Но другая потоковая программа может продвинуться на несколько недель времени события всего за пару секунд обработки путем быстрой перемотки некоторых исторических данных, уже буферизованных в топике Kafka или другой очереди сообщений.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
27 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Для измерения прогресса во времени событий Apache Flink использует механизм водяных знаков (watermark). Водяные знаки являются частью потока данных и несут метку времени t. Водяной знак (t) объявляет, что время события достигло времени t в этом потоке, поэтому здесь больше не должно быть событий с меткой времени t ‘<= t, т.е. старше или равными водяному знаку t.
Кроме того, в отличие от неограниченных потоков, обработка исторических данных требует управления трафиком и синхронизации источников для достижения стабильной работы. Например, команде разработчиков в режиме реального времени требуется получать информацию о том, как пользователи просматривают изображения, опубликованные за последнюю неделю. Создается Flink-задание, чтобы извлекать опубликованные журналы изображений Kafka и просмотры этих журналов. Чтобы задание Flink могло публиковать значимую информацию, используется единый источник.
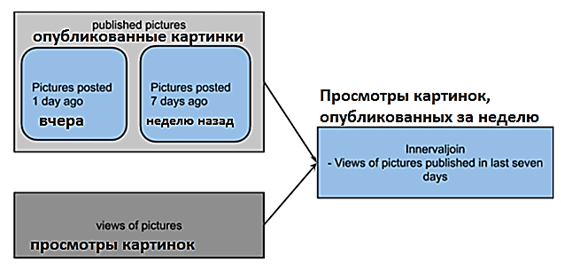
Здесь возникают две проблемы с использованием разных источников данных (в случае рассматриваемого примера это топики Apache Kafka):
- топик просмотров намного больше, чем топик с данными об опубликованных и прикрепленных в коллекции изображениях. Топик просмотров потребляет много трафика и замедляет заполнение опубликованных картинок. Поскольку конвейеры были написаны в режиме времени событий, это замедляет прогресс водяного знака во операторе соединения (INNER JOIN). Со временем все больше и больше событий помещается в буфер, ожидая очистки. Это вызывает сбои противодавления и контрольных точек. Поэтому было задано ограничение скорости на уровне топика Kafka: больший объем получили топики с изображениями вместо топиков с их просмотрами.
- топики просмотров должны ожидать окончания периода публикации изображений – в данном примере 7 дней, иначе будет низкий коэффициент совпадения. По терминологии Flink, водяной знак из опубликованных картинок должен перейти в «текущий», т.е. время запуска задания до того, как просмотры водяных знаков топика изображения станут текущими. Для решения этой проблемы с синхронизацией было была введена обработка водяных знаков на основе allreduce и периодическое обновление порогового значения ratelimiter для каждого топика. Математическая функция параллельного программирования MPI_Allreduce объединяет значения из всех процессов и распределяет результат обратно по всем процессам. Представлению ratelimiter источника изображения предоставляется квота для извлечения топика Kafka только тогда, когда водяные знаки из всех подзадач достигают «текущего» состояния.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
1 августа, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Комбо потоковой и пакетной обработки с UnifiedSource
Чтобы объединить потоковую и пакетную обработку данных, разработчики Pinterest написали UnifiedSource – собственное расширение базового класса RichParallelSourceFunction, который реализует параллельные источники данных. После выполнения среда выполнения выполнит столько параллельных экземпляров этой функции, насколько настроен параллелизм источника. UnifiedSource поддерживает методы Flink для создания водяных знаков из Kafka, извлекая метки времени средствами API, которое используется в коннекторе KafkaSource для создания водяных знаков из источника. Так удалось стандартизировать создание водяных знаков в приложениях Flink. Но универсальный доступ к данным в реальном времени и историческим событиям – не единственное достоинство UnifiedSource. Также это решение предоставляет следующие преимущества:
- готовые функции, такие как десериализатор, создание водяных знаков, управление трафиком и метрики поврежденных сообщений, чтобы разработчики Flink могли сосредоточиться на реализации бизнес-логики, а не на технической специфике фреймворка;
- пользователи могут генерировать детерминированные результаты, загружая фиксированные наборы данных и проверяя их на соответствие изменениям кода или обновлениям инфраструктуры.
Чтобы протестировать эффективность UnifiedSource, дата-инженеры Pinterest провели нагрузочное тестирование заданий Flink перед переходом в production-среду. Эксперименты показали, что имитация нагрузки трафика через UnifiedSource оказалась более масштабируема и экономически эффективна, чем перемотка смещений Kafka.
Hadoop для инженеров данных
Код курса
HDDE
Ближайшая дата курса
17 июня, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Больше практических примеров по администрированию и эксплуатации Apache Flink и Kafka для разработки распределенных приложений аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка данных с помощью Apache Flink
- Apache Kafka для инженеров данных
- Hadoop для инженеров данных
- https://medium.com/pinterest-engineering/unified-flink-source-at-pinterest-streaming-data-processing-c9d4e89f2ed6
- https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/time/
- https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/event-time/generating_watermarks/

