В продолжение темы про основы Apache Kafka Streams для начинающих, сегодня мы поговорим про то, как абстрактные понятия топика (topic), таблицы (table) и потока (stream) позволяют распараллелить обработку информационных потоков. Читайте в нашем новом материале, что такое обработчики потоков Кафка Стримс, как они обрабатывают разделы топиков (topic partition) Kafka и как это связано с потоками изменений (таблицами).
Что такое обработчик потоков Apache Kafka Streams
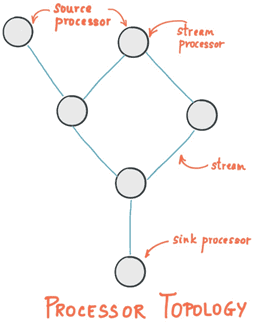
Напомним, что главная абстракция Kafka Streams – это поток – неограниченный и постоянно обновляемый набор данных в виде упорядоченной, воспроизводимой и отказоустойчивой последовательности неизменяемых парных записей «ключ-значение» (key-value). Вычислительная логика приложений потоковой обработки, использующих библиотеку Apache Kafka Streams, работает по графовой модели обработчиков потоков (вершин), связанных между собой потоками (ребрами). В этой топологии обработчик является узлом преобразования данных в потоки, который выполняет следующие действия [1]:
- получает по одной входной записи за раз от вышестоящих узлов;
- применяет к входящей записи свою операцию (агрегация, фильтр и пр.);
- создает одну или несколько выходных записей для своих нижестоящих узлов.
Различают 3 вида обработчиков потоков Apache Kafka Streams [1]:
- источник (source processor), который не имеет вышестоящих узлов, он создает входной поток в свою топологию из одному или нескольким топикам Кафка, потребляя из них записи и направляя их на свои нижестоящие узлы;
- обычный обработчик потока (stream processor), который получает входной поток от вышестоящих узлов, обрабатывает его и отправляет нижестоящим узлам, при этом обработанные результаты могут быть либо переданы обратно в Kafka, либо записаны во внешнюю систему;
- приемник (sink processor), который не имеет нижестоящих узлов, он отправляет все полученные записи от своих вышестоящих обработчиков в указанный топик Кафка.
Как обработчики потоков Кафка Стримс разделяют задачи параллельной обработки больших данных
Отметим, что вышеописанная топология потоковых обработчиков, используемая в Apache Kafka Streams – это просто логическая абстракция для программного кода. Во время выполнения эта логическая топология создается и реплицируется внутри приложения параллельной обработки [2].
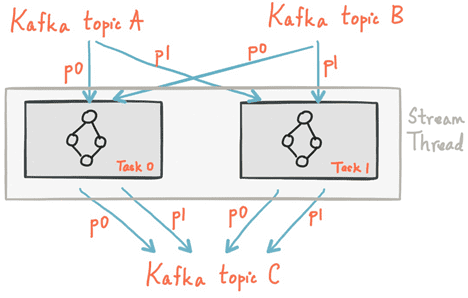
В качестве логических единиц своей модели параллелизма Kafka Streams использует концепции потоковых разделов и потоковых задач (stream task). При этом между Кафка и Kafka Streams существуют следующие связи:
- каждый потоковый раздел (stream partition) представляет собой полностью упорядоченную последовательность записей данных в соответствии с разделом топика (topic partition) Кафка;
- запись данных в потоке отображает сообщение из топика Кафка;
- ключи записей определяют разбиение данных по разделам (partition) в Кафка и Kafka Streams (то, как данные направляются в определенные разделы топиков).
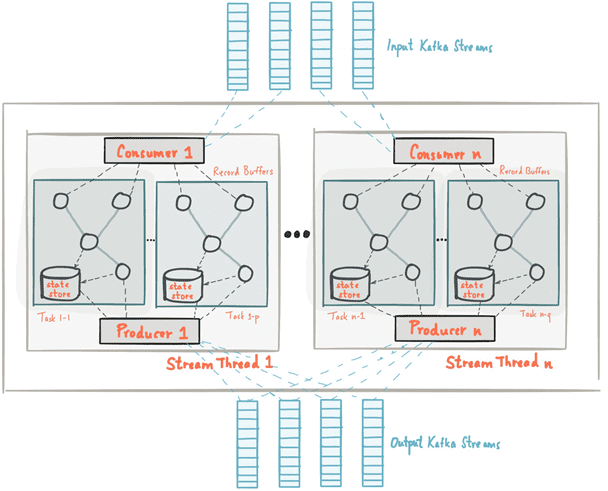
Топология программного обработчика масштабируется путем разбивки его на несколько потоковых задач: Kafka Streams создает фиксированное количество потоковых задач на основе входных потоковых разделов (stream partition) для приложения. При этом каждой задаче назначается свой список топиков Кафка. Назначение потоковых разделов потоковым задачам никогда не меняется, поэтому потоковая задача является фиксированной единицей параллелизма приложения. Задачи могут создавать свою собственную топологию потоковых обработчиков на основе назначенных разделов, буферизируя каждый раздел и обрабатывая по одной записи за раз из этих буферов [3].
Отметим, что Kafka Streams позволяет настраивать количество веток (thread) для распараллеливания обработки в экземпляре приложения. При этом каждая ветка может независимо выполнять одну или несколько задач с своими топологиями обработки. Запуск большего количества потоковых веток или большего количества экземпляров приложения сводится к репликации топологии и позволяет обрабатывать другое подмножество разделов Kafka, эффективно распараллеливая обработку. Поскольку между потоками нет общего состояния, нет необходимости в их координации, что позволяет очень просто запускать разные топологии обработки параллельно между экземплярами приложения и потоками. Назначение разделов топика Кафка среди различных потоковых веток обрабатывается Kafka Streams с помощью координации Kafka.
Таким образом, масштабировать приложение потоковой обработки с помощью Kafka Streams очень просто: нужно запустить дополнительные экземпляры приложения, а Kafka Streams автоматически распределении разделы между задачами, которые выполняются в экземплярах приложения. Потоковые задачи будут обрабатываться автоматически, независимо и параллельно. При этом максимальный параллелизм приложения ограничен максимальным количеством потоковых задач. В свою очередь, число потоковых задач определяется максимальным количеством разделов входного топика, из которого приложение считывает данные (сообщения Kafka). Например, если входной топик имеет 5 разделов, можно запустить до 5 экземпляров приложений, которые будут совместно обрабатывать данные этого топика. В случае запуска большего количества экземпляров приложения, «лишние» из них останутся бездействующими, но, если один из занятых экземпляров выйдет из строя, любой свободный возобновит его работу [3]. Таким образом, можно запустить столько потоков приложения, сколько имеется входных разделов топика Кафка, чтобы во всех запущенных экземплярах приложения каждый поток и выполняемые им задачи имели, по крайней мере один входной раздел для обработки [4]. А каким образом Kafka Streams реализует обработку потоковых данных, читайте в нашей следующей статье.
Узнайте все технические подробности по работе с Apache Kafka Streams API для быстрой обработки больших данных в режиме онлайн на специализированных курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Источники
- https://kafka.apache.org/23/documentation/streams/core-concepts
- https://dzone.com/articles/kafka-streams-more-than-just-dumb-storage
- https://docs.confluent.io/current/streams/architecture.html
- https://kafka.apache.org/23/documentation/streams/architecture

