
При том, что Apache Spark является одной из главных технологий стека Big Data, этот фреймворк не очень хорошо работает с множеством файлов небольшого размера. Поэтому в рамках обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, почему это происходит, зачем динамически сжимать файлы в Apache Spark и как это делает платформа Databricks.
Почему данные должны быть большими: трудности обработки множества маленьких файлов в Apache Spark
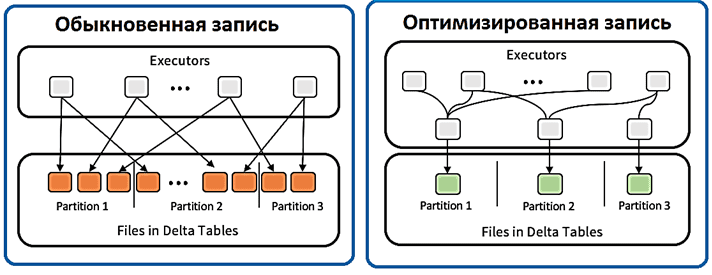
Бывает, что приложение Apache Spark занимает слишком много времени на чтение набора данных из AWS S3, поскольку драйвер выполняет перечисление файлов, оценивая размер и разделы, а затем распределяя фактическую обработку между исполнителями. Spark должен передавать эти файлы по сети, а также распаковывать их. Затем каждый файл становится одним разделом в результирующем RDD, который в итоге содержит множество крошечных разделов. В результате наличие слишком большого количества небольших файлов может привести к снижению производительности. В худшем случае драйвер может выйти из строя с исключениями нехватки памяти. Чтобы преодолеть эту проблему, Apache Spark необходимо динамическое сжатие файлов данных.
Рассмотрим ситуацию, когда это может случиться в действительности: предположим, задание приема данных каждый час добавляет новый пакет данных в место назначения, в котором будет хотя бы один новый файл. Размер файла зависит от объема данных, собранных за час, от нескольких МБ до сотен ГБ. Создаются сотни небольших файлов, которые не могут эффективно обрабатываться системами хранения и самим фреймворком Spark, который опрашивает систему хранения для получения списка файлов. Большое количество файлов замедлит операцию листинга, а Spark потребуется открыть все эти файлы и закрыть их после прочтения. Это приведет к тому, что задание будет тратить много времени на открытие и закрытие файлов, а не на чтение данных и вычисления. Небольшой файл плохо сжимается из-за снижения эффективности сжатия. Если речь идет о таблице Spark, это означает, количество метаданных также растет и дополнительно замедляет обработку.
Кроме того, небольшие файлы приводят к большему количеству обращений к диску при выполнении вычислений. В Spark задача внутри исполнителя читает и обрабатывает по одному разделу за раз. По умолчанию каждый раздел представляет собой один блок. Следовательно, одна параллельная задача может выполняться для каждого раздела в Spark RDD. Поэтому при большом количестве небольших файлов, каждый из них файл читается в другом разделе, что вызывает значительные накладные расходы, что мы подробно рассматриваем здесь.
Решить эту проблему помогает уплотнение или сжатие файлов, если они хранятся в количестве файлов, правильно коррелирующем с размером хранилища. Например, эффективно хранить 100 МБ данных в одном большом 1 файле, вместо 1000 маленьких. Хотя разница заключается в количестве файлов, созданных для хранения одного и того же объема данных, небольшие файлы вызывают серьезное снижение производительности при обработке чтения. Это происходит из-за того, что процессу-потребителю требуется тратить дополнительные дескрипторы для открытия и закрытия гораздо большего количества файлов, чем оптимально для чтения. Поэтому рекомендуется динамически перераспределяйте данные перед их записью в озеро данных на AWS S3.
Однако, здесь тоже есть свои особенности: объем раздела зависит от размера данных. Записывать файлы одинакового размера в отдельные разделы непрактично. Целесообразно применять динамическое разбиение для каждого сжатого файла в соответствии с его уникальным размером для каждого раздела. Предположим, пользователь может указать желаемый минимальный и максимальный размер в мегабайтах для каждого файла после сжатия. Таким образом, динамическое сжатие файлов в Apache Spark сводится к следующим шагам [1]:
- Найти размер раздела;
- Определить количество разделов;
- вычислить размер файла в каждом разделе;
- перезаписать данные в каждом разделе в виде сжатых больших файлов.
Это можно проделать вручную, собственноручно написать функции, как в источнике [1]. Однако, большинство Big Data платформ, основанных на Apache Spark, уже включают опцию автоматического сжатия и оптимизации размеров файлов. Как это работает в Databricks, мы рассмотрим далее.
Анализ данных с Apache Spark
Код курса
SPARK
Ближайшая дата курса
13 мая, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
Динамическое сжатие файлов в Databricks
В коммерциализированной версии Apache Spark на платформе Databricks есть возможность автоматической оптимизации, которая автоматически сжимает небольшие файлы во время отдельной записи в дельта-таблицу. Даже с учетом незначительных накладных расходов во время записи, это дает существенное преимущество для активно запрашиваемых таблиц. Автоматическая оптимизация особенно полезна в следующих случаях:
- сценарии потоковой передачи с допустимой задержкой порядка в пределах минуты;
- запись данных в Delta Lake методом MERGE INTO;
- применение операций CREATE TABLE AS SELECT или INSERT INTO.
Напомним, Delta Lake — это уровень хранилища с открытым исходным кодом, обеспечивающий надежность озера данных с поддержкой ACID-транзакций и масштабируемой обработкой метаданных, объединяя потоковые и пакетные операции. Delta Lake работает на базе существующего озера данных (на Apache Hadoop HDFS, Amazon S3 или Azure Data Lake Storage) и полностью совместимо со всеми API Apache Spark. Подробнее об этом мы рассказывали здесь, здесь и здесь.
В Databricks автоматическая оптимизация (Auto Optimize) состоит из двух дополнительных функций:
- оптимизация записи (Optimized Writes), когда платформа динамически оптимизирует размеры разделов Apache Spark на основе фактических данных и пытается записать файлы размером 128 МБ для каждого раздела таблицы. Это приблизительный размер, который может варьироваться в зависимости от характеристик набора данных.
- автоматическое уплотнение (Auto Compaction) — после каждой записи Databricks проверяет возможность дальнейшего сжатия файлов и запускает задание OPTIMIZE с размером файла 128 МБ вместо размера файла 1 ГБ, используемого в стандартной операции OPTIMIZE для дальнейшего сжатия файлов для разделов с наибольшим количеством небольших файлов.
Оптимизированная запись направлена на максимальное увеличение пропускной способности данных, записываемых в службу хранения. Этого можно добиться, уменьшив количество записываемых файлов, не жертвуя излишним параллелизмом. Оптимизированная запись требует перетасовки данных в соответствии со структурой разделения целевой таблицы. Это перемешивание требует дополнительных затрат, которые может перевесить увеличение пропускной способности во время записи. Важно, что оптимизированная запись включает адаптивное перемешивание. Например, когда в случае потокового приема скорости входных данных меняются со временем, адаптивное перемешивание будет настраиваться в соответствии со скоростями входящих данных между микропакетами. Это также полезно при использовании таких SQL-команд, как MERGE, UPDATE, DELETE, INSERT INTO, CREATE TABLE AS SELECT. Однако, если данные очень большие (порядка терабайт) /или экземпляры, оптимизированные для хранения, недоступны, лучше отказаться от Optimized Writes. Аналогично при использовании спотовых инстансов в облаке, нестабильность которых приводит к потере большой части узлов.
Автоматическое сжатие происходит после успешной записи в таблицу и выполняется синхронно в кластере, который выполнил запись. Это означает, что при наличии шаблонов кода, где выполняется запись в Delta Lake, а затем следует вызов OPTIMIZE, можно удалить его, включив Auto Compaction. В частности, для сеанса Spark это можно сделать в конфигурации spark.databricks.delta.autoCompact.enabled.
Автоматическое уплотнение использует эвристику, отличную от OPTIMIZE. Поскольку он запускается синхронно после записи, Databricks предлагает автоматическое сжатие без поддержки Z-упорядочение, которое значительно дороже простого уплотнения.
Автоматическое сжатие создает файлы меньшего размера (128 МБ), чем OPTIMIZE (1 ГБ), с помощью жадного алгоритма выбирая ограниченный набор разделов, которые лучше всего подходят для уплотнения. Количество выбранных разделов будет зависеть от размера Spark-кластера. Если в кластере много процессоров, можно оптимизировать больше разделов.
Чтобы контролировать размер выходного файла, следует установить конфигурацию Spark spark.databricks.delta.autoCompact.maxFileSize. Значение по умолчанию — 134217728, что задает размер 128 МБ. При указании значения 104857600 размер файла устанавливается равным 100 МБ.
Это будет полезно в сценариях потоковой передачи, когда допустима задержка в минутах и в таблице отсутствуют регулярные вызовы OPTIMIZE.
Однако, поскольку другие пользователи или задания записи могут одновременно выполнять такие операции, как DELETE, MERGE, UPDATE или OPTIMIZE, автоматическое сжатие чревато конфликтом транзакций для этих заданий. Тем не менее, в этом случае Databricks не выходит из строя и не повторяет сжатие [2]. О том, какую роль форматы хранения файлов играют в организации корпоративных хранилищ и озер данных, читайте в нашей новой статье для дата-инженеров.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
13 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Больше подробностей администрирования и эксплуатации Apache Spark для разработки распределенных приложений и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark

