Сегодня обсудим ключевые тренды развития дата-инженерии и инструментальные средства их реализации. Как это применяется на практике, рассмотрим на примере эволюции хранилища данных в индонезийской ИТ-компании Bukalapak, от локального кластера Apache HBase до Лямбда-архитектуры в облаке Google Cloud Platform с Kafka, Spark и AirFlow.
7 главных драйверов развития дата-инженерии
В наши дни для большинства компаний данные являются наиболее важным бизнес-активом, это основа принятия операционных и стратегических решения, которую необходимо проверять и защищать. Потребности бизнеса в оперативном доступе к исходным и обработанным данным постоянно растет, поэтому дата-инженерия эволюционирует от простой загрузки и хранения в озерах данных на Apache Hadoop, к облачным вычислениям на Spark и Hive со сложной оркестровкой заданий с помощью Airflow и прочих аналогов. Основными драйверами развития современной инженерии данных можно назвать следующие:
- востребованность со стороны бизнеса – современным компаниям нужно не просто эпизодически обрабатывать пакетные задания по анализу исторических данных, а реагировать на события в режиме реального времени и/или даже опережать их, снижая риски и влияние их последствий;
- расширенная аналитика данных с использованием методов машинного обучения для выявления неявных закономерностей из огромных наборов разнородной информации;
- востребованность во множестве отраслей, от розничной торговли до гостиничного бизнеса в организациях различного масштаба частного и государственного секторов;
- правила защиты и управления данными, как на уровне государственных и межгосударственных регуляторов типа GDPR, до внутренних политик и регламентов каждой организации относительно прав на выполнение различных операций с данными и возможности отследить их источник в случае утечки;
- технологические инновации, например, переход к облачным аналитическим архитектурам, микросхемы с поддержкой сложных ML-алгоритмов (нейросети и глубокое обучение), средства поддержки принятия решений в прикладных системах автоматизации бизнес-процессов;
- финансовая прозрачность – с ростом инвестиций инициативы в области аналитики также подвергаются все более тщательной проверке. Извлечение ценности из данных должно быть финансово ответственным и фактически добавлять ценность предприятию, обеспечивая своевременный возврат инвестиций.
- эволюция ролей в процессах работы с данными, например, директора по данным (CDO), дата-стюарта, куратора по качеству данных и других ролей, которые должны сбалансировать потребности управления, безопасности и демократизации.
Какие инструментальные средства стека Big Data реализуют эти тенденции инженериии данных, рассмотрим далее на примере развития архитектуры корпоративного озера данных в индонезийской e-commerce компания Bukalapak.
Эволюция озера данных: от ETL-конвейера к Lambda-архитектуре
Озеро данных (Data Lake) — это репозиторий, в котором хранится огромное количество необработанных данных в различных форматах, структурированных и неструктурированных. В 2017 году индонезийская компания Bukalapak реализовала свое озеро данных на Apache HBase поверх Hadoop HDFS.
Тогда команда дата-инженеров компании еще не была знакома со Spark Streaming и создала свой первый конвейер потоковой передачи с помощью клиентского сервиса Kafka в кластере Kubernetes. Он объединял все этапы сбора и обработки данных, от топиков Kafka до таблиц HBase, которые были 2-х видов:
- Upsert-таблицы,куда данные вставляются или обновляются на основе ключа строки HBase;
- Appaend-only — таблицы только для добавления, куда вставляются новые данные с разделением по времени приема (дата и час).
Хранилище данных как система управления данными, предназначенная для включения и поддержки операций BI-аналитики было реализовано в HDFS. Задания Spark выступали в качестве конвейеров ETL, запланированных ежедневно и ежечасно, а Apache Airflow был их оркестратором и планировщиком. Сам конвейер ETL представлял собой набор процессов для извлечения данных из озера, их очистки и преобразования в готовые к использованию форматы и загрузки в другие источники. Изначально было достаточно всего пары ETL-конвейеров: с полной загрузкой для ежедневных обновлений и с инкрементальной загрузкой для ежечасных обновлений.
Но по мере роста компании и развития бизнеса возникла потребность в новых аналитических сценариях: запросов становилось все больше, и они были все разнообразнее. В 2019 году инженеры Bukalapak начали экспериментировать с потоковой обработкой и использовать Apache Kudu с Impala и Spark Streaming. Напомним, Apache Kudu — это механизм распределенного хранения данных, который упрощает быстрый анализ быстрых и меняющихся данных. Apache Impala — это современный распределенный механизм запросов SQL. Подробнее о совместном использовании Kudu и Impala мы рассказывали здесь и здесь.
API Apache Kudu поддерживает функцию вставки данных Upsert, что было удобно из-за наличия таких таблиц в корпоративном Data Lake. Для обслуживания хранилища и витрины данных были созданы внешние таблицы в Apache Hive и подключены с помощью коннектора Hive к кластеру PrestoDB. Presto (ныне Trino) был основным инструментом для запроса всех данных во всех элементах платформы Bukalapak.
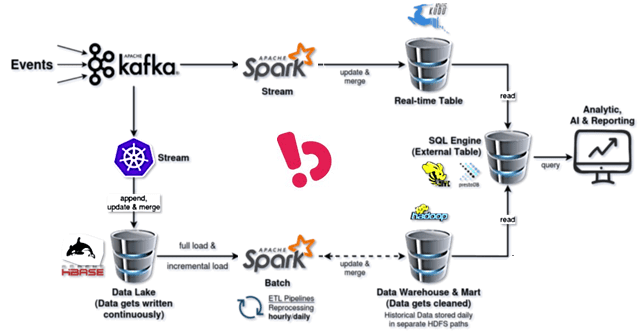
Хотя такая архитектура и воплощала некоторые идеи Lambda-подхода, она не полностью соответствовала ему и провоцировала некоторые инфраструктурные проблемы. В частности, внезапно случались аппаратные сбои, устранение которых занимало много времени и ресурсов. Также были сложности с масштабированием и скоростью обработки данных. Потери данных в озере на Apache HBase возникали довольно часто. Размер блока данных в HDFS не был максимальным, что сказывалось на производительности и проблемах с хранилищем. Из-за того, что каждое бизнес-подразделение могло создать свой ETL-конвейер, управлять ими было непросто. Дополнительную трудность вносило отсутствие оперативного мониторинга рабочих процессов и метрик.
Из-за отсутствия надлежащего управления данными, включая произвольные изменения схемы и типов, наблюдались проблемы с их качеством. В частности, были обнаружены разные категории значений в одном и том же столбце и несоответствие схемы между данными в реальном времени и хранилищем. Чтобы исправить все эти проблемы дата-инженеры Bukalapak решили перевести существующую архитектуру на Lambda. Как это было сделано, мы рассмотрим далее.
Реализация Лямбда-архитектуры в Bukalapak на Spark Kafka и AirFlow в GCP
Напомним, Лямбда-архитектура обеспечивает доступ к методам пакетной и потоковой обработки больших объемов данных с гибридным подходом. Новые данные постоянно поступают в систему одновременно на пакетный уровень и на уровень скорости. Пакетный слой отвечает за управление набором основных данных, который является источником истины. Этот слой создается по заранее заданному расписанию, обычно один или два раза в день и выполняет две основные функции:
- Управление основным набором данных;
- Предварительно вычисление пакетных представлений.
Выходные данные пакетного слоя — это пакетные представления, а выходные данные слоя скорости — это представления, близкие к реальному времени. Слой скорости обрабатывает данные, которых нет в пакетном представлении из-за задержки пакетного уровня, и имеет дело только с последними данными. Поэтому, чтобы дать пользователям полное представление о данных, данные слоя скорости объединяются с пакетным слоем.
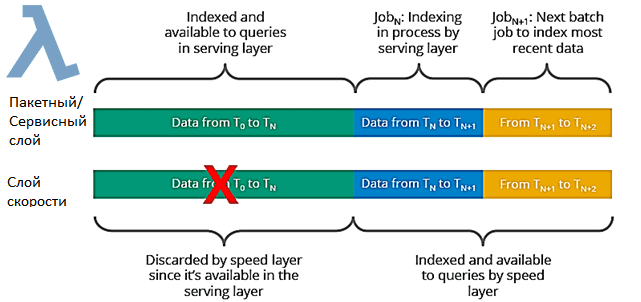
Чтобы сократить временные и финансовые затраты на инфраструктуру, дата-инженеры Bukalapak решили реализовать Лямбда-архитектуру на базе Google Cloud Platform (GCP). GCP включает множество отличных сервисов: Google Cloud Storage, Google Cloud Dataflow, Google Cloud Dataproc, Google BigQuery и пр. Некоторые из них задействованы в новой архитектуре:
- Google Cloud Storage заменил HDFS;
- Google Cloud Dataflow для потоковых ETL-конвейеров;
- Google Cloud Dataproc для пакетных конвейеров ETL;
- Google BigQuery в качестве вычислительного SQL-движка для доступа к хранилищу данных и выполнения аналитических запросов;
- Looker для визуализации данных.
Все эти службы предоставляют множество журналов, позволяя создать наглядную панель мониторинга и отчеты. О том, каковы преимущества бессерверной службы Apache Spark в Google Dataproc для дата-инженера, читайте в нашей новой статье.
Чтобы улучшить качество данных, был разработан новый сервис под названием SchemaHub, интегрированный с DataHub, для поддержки всех метаданных таблиц хранилища данных. SchemaHub хранит связанную информацию, такую как имена столбцов, типы данных и определения данных, описания таблиц и столбцов, столбцы метаданных и т. д. Поэтому все ETL-конвейеры должны обрабатывать любые данные со схемой, зарегистрированной в службе SchemaHub. В хранилище данных используется схема звезды, которая включает одну или несколько таблиц фактов, ссылающихся на любое количество таблиц измерений.
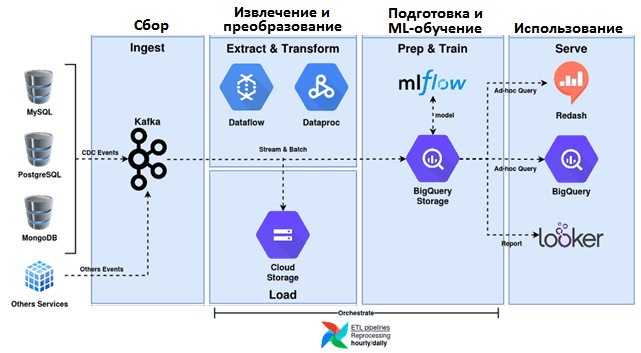
В результате реализации Лямбда-архитектуры на Google Cloud Platform, удалось стандартизовать корпоративное озеро данных, чтобы использовать таблицу только для добавления с разделом даты и часа, хранящимся в Google Cloud Storage (GCS). Теперь все таблицы озера данных имеют одну и ту же схему, а также определение на более высоком уровне. Google Cloud Dataflow выступает в качестве потокового ETL-конвейера для передачи всех событий из Kafka в GCS практически в режиме реального времени.
Стандартизовано корпоративное хранилище данных для использования схемы звезды, хранящейся в BigQuery, включая все возможности этого хранилища, такие как автоматическое сжатие и сохранение данных. ETL-конвейеры в виде Spark-заданий в Google Cloud Dataproc основаны на схеме, предоставленной SchemaHub. Хранилище исторических данных организовано в Google Cloud Storage, откуда удаляются объекты, которые не обновлялись в течение последних 365+ дней. А объекты, которые не обновлялись в течение последних 3-х месяцев, считаются историческими данными («холодными»).
Данные в реальном времени стандартизованы, чтобы использовать таблицу только для добавления с разделом TimeStamp, хранящимся в BigQuery. Google Cloud Dataflow выступает в роли ETL-конвейера потоковой передачи всех событий из Kafka в BigQuery практически в режиме реального времени. Конвейеры потоковой передачи ETL также используют схему, предоставляемую SchemaHub, с дополнительными столбцами метаданных для дедупликации «горячих» данных. Согласно концепции Lambda-архитектуры, сохраняются только последние данные, которые еще не доступны на пакетном уровне, создавая политику хранения в таблице BigQuery. Унификация конвейеров потоковой и пакетной обработки достигается с помощью Apache Beam, о котором мы недавно писали здесь.
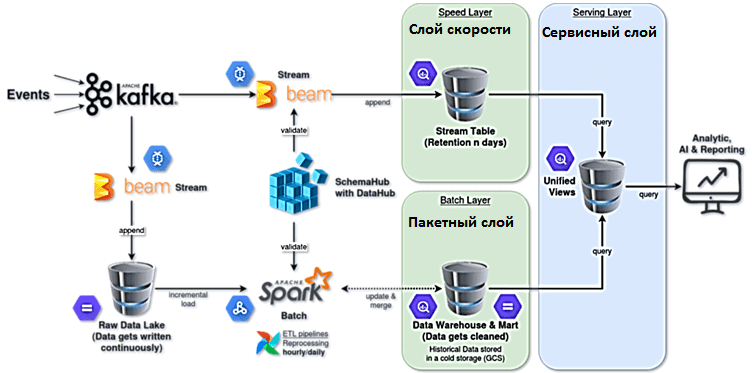
На сервисном уровне Лямбда-архитектуры реализована децентрализованная платформа данных, чтобы каждая команда могла хранить свои данные в своем хранилище BigQuery. BigQuery поддерживает разделение между системами хранения и вычислений. Так можно использовать другой BigQuery в качестве вычислительной машины и создавать представления для того же BigQuery, чтобы сделать их запрашиваемыми и затем подключить к другим сервисам типа Looker и Redash. Используя Left Join и Union в SQL-запросах, можно получать представления в реальном времени:
WITH distinct_speed_layer AS ( SELECT <any_columns> FROM ( SELECT stream.*, ROW_NUMBER() OVER (PARTITION BY <unique_id> ORDER BY <ingestion_time> DESC) AS row_number FROM <speed_layer_table> AS stream ) WHERE row_number=1 )SELECT <any_columns> FROM <batch_layer_table> AS batch_layer LEFT JOIN ( SELECT DISTINCT <unique_id> FROM distinct_speed_layer ) AS speed_layer ON batch_layer.<unique_id> = speed_layer.<unique_id> WHERE speed_layer.<unique_id> IS NULL UNION ALL SELECT <any_columns> FROM distinct_speed_layer
Узнайте все про проектирование архитектуры, разработку и реализацию распределенных приложений с Apache Hadoop, Kafka, Spark и AirFlow для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
- Архитектура Данных
- Hadoop для инженеров данных
- Apache Kafka для разработчиков
- Анализ данных с Apache Spark
- Data Pipeline на Apache Airflow

