
Недавно мы писали, что в новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, сделаны попытки объединения потоковой и пакетной парадигм обработки данных. Сегодня рассмотрим, как подобное стремление к унификации реализуется на практике дата-инженерами фотохостинга Pinterest, которые используют Apache Flink как универсальный инструмент аналитики больших данных в историческом и оперативных периодах.
Под капотом потоковой аналитики на Apache Flink и Kafka
Ежемесячно более 475 миллионов человек используют Pinterest в качестве соцсети, размещая там фотографии и группируя их в различные тематические коллекции. Чтобы лучше обслуживать своих пользователей и рекламодателей, Pinterest использует Apache Flink в качестве stateful-механизма обработки потоковой информации. Он предоставляет богатые API потоковой передачи, поддерживает семантику строго однократного выполнения (exactly once) и контрольные точки состояния для создания стабильных и масштабируемых потоковых приложений. Благодаря этому Flink широко используется во множестве компаний: Alibaba, Netflix, Uber и пр. для критически важных бизнес-сценариев, о чем мы упоминали здесь.
Именно на базе Apache Flink инженеры Pinterest разработали собственную платформу обработки потокового видео под названием Xenon, которая отличается надежностью, быстротой вычислений и безопасностью. Xenon поддерживает следующие бизнес-сценарии в Pinterest:
- показ рекламы в реальном времени, контроль расходов и формирование отчетности по рекламным кампаниям;
- быстрый анализ контента после его создания и использование результатов в конвейерах машинного обучения для индивидуального взаимодействия с пользователем, определения небезопасного контента и передачи данных потенциальным потребителям;
- обновление метаданных о продуктах в реальном времени;
- передача метрик ML-инженерам для более точной настройки, проверки и оценки экспериментов.
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
1 июля, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Разумеется, помимо Xenon на базе Flink, в системе потоковой аналитики Pinterest используются и другие технологии класса Event Streaming. В частности, Singer — высокопроизводительный агент логирования, который загружает сообщения логов с обслуживающих хостов Apache Kafka. Singer поддерживает несколько форматов журналов и семантику доставки сообщений хотя бы один раз (at least once). Поскольку Singer работает как отдельный процесс на сервисах-приемниках сообщений, помимо Kafka его можно также расширить для поддержки записи в другие системы. Он отслеживает каталоги журналов, прослушивая события файловой системы, и выгружает данные при обнаружении новых записей. Singer гарантирует как минимум однократную доставку сообщений журнала. Ключевыми особенностями этого open-source проекта Pinterest являются следующие:
- высокая пропускная способность за счет машиночитаемого логирования, который с помощью набора клиентских библиотек на Python, Java и Go преобразует текстовые сообщения в JSON и форматы, которые хранят данные очень компактно. А для быстрой записи в Kafka используется несколько уровней пула потоков, чтобы достичь максимального параллелизма. Вместе с экономичным форматом логирования, Singer может достичь пропускной способности записи в Kafka более 100 МБ в секунду с одного хоста и обрабатывать текстовые логи со скоростью 20 МБ/с.
- минимум однократная доставка сообщений в Kafka: повторная отправка, если пакет сообщений не удалось загрузить. Для каждого потока журнала Singer использует файл водяного знака, чтобы отслеживать прогресс. При перезапуске Singer перезапускается, он обрабатывает сообщения с учетом позиции водяного знака.
- поддержка входа в Kubernetes в качестве дополнительного системного сервиса – Singer может отслеживать и загружать данные из каталогов журналов нескольких подов Kubernetes;
- логирование с низкой задержкой (менее 5 милисекунд) благодаря гибкой настройке параметров обработки и размеров пакетов;
- гибкое партиционирование — Singer предоставляет несколько разделителей для записи данных в Kafka, включая те, которые с учетом местоположения могут избежать трафика продюсеров между зонами доступности и снизить затраты на передачу данных;
- heartbeat-сигналы – Singer поддерживает периодическую отправку сигнала в топик Kafka в зависимости от конфигурации, чтобы пользователи могли настраивать централизованный мониторинг экземпляров агента во всех системах;
- аудит записи — Singer может отправить контрольную запись в другой топик для каждого пакета сообщений, которые он пишет в Kafka, чтобы пользователи могли проверять наличие записей Singer в K
- расширяемый дизайн – помимо Kafka, Singer можно легко расширить для загрузки данных в другие внешние системы.
Кроме Apache Flink, Kafka и Singer, в системе потоковой аналитики больших данных Pinterest также используется Merced – вариант open-source сервиса Secor, который перемещает данные из Kafka в облачные объектные хранилища: AWS S3, Google Cloud Storage, Microsoft Azure Blob Storage и Openstack Swift. Merced гарантирует строго однократное сохранение сообщения от Kafka до S3 и имеет следующие ключевые особенности:
- сильная согласованность – пока Kafka не удалит сообщения из-за политики очистки, до того, как Secor сможет их прочитать, каждое сообщение будет сохранено ровно в одном файле S3;
- отказоустойчивость — любой компонент Secor может выйти из строя и восстановиться без нарушения целостности данных,
- распределение нагрузки по нескольким узлам;
- горизонтальная масштабируемость – масштабирование системы для обработки большего объема данных просто, как запуск дополнительных процессов Secor. Уменьшить объем ресурсов можно, остановив любой из запущенных процессов Secor. Важно, что увеличение или уменьшение не влияют на согласованность данных,
- партиционирование вывода — Secor анализирует входящие сообщения и помещает их по путям разделов AWS S3, чтобы обеспечить прямой импорт в Apache Hive, включая разделение по временным периодам (дни, часы, минуты).
- настраиваемые политики загрузки — точки фиксации для контроля времени, когда данные сохраняются в S3, настраиваются с помощью политик на основе размера и периода. Например, загружать данные в S3, когда размер локального буфера достигает 100 МБ и не реже одного раза в час. Как подобную проблему больших сообщений с отправкой их в AWS S3 решала немецкая компания Bakdata, читайте здесь.
- мониторинг – показатели производительности отображаются через Ostrich, Micrometer и при необходимости экспортируются в OpenTSDB или statsD;
- конфигурируемость – внешний парсер сообщений логов может быть загружен путем обновления конфигурации;
- преобразование событий – преобразование на уровне внешнего сообщения можно выполнить с помощью настраиваемого класса;
- Qubole-интерфейс для добавления окончательных разделов вывода в таблицы Hive.
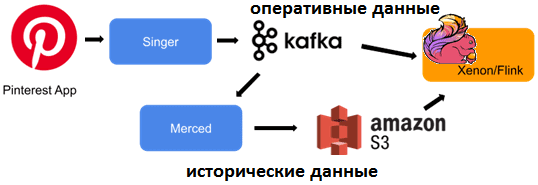
Хотя все сценарии Pinterest используют данные из Kafka, но доступ к этой распределенной платформе потоковой передачи не может удовлетворить все потребности пользователей. Например, иногда требуется доступ к историческим данным, а данные в топиках Kafka хранятся недолго: от трех дней до восьми часов. Возникают сложности с нагрузочным тестированием перед запуском в production: имитация нагрузки в Kafka не масштабируется. Наконец, воспроизведение исторических данных в Kafka сопряжено с дополнительными операционными расходами и 20-кратным увеличением затрат на инфраструктуру.
Merced решает проблему исторических данных, используя AWS S3 в качестве постоянного хранилища. Поэтому можно предоставить единый API, который объединяет исторические данные с данными в реальном времени, реализуя концепцию неограниченного лога. Пользователи смогут искать любое смещение или метку времени, не беспокоясь о том, где именно, т.е. в какой системе хранения хранятся данные. Такой дизайн дает несколько преимуществ:
- кодировка и схема топика в Merced и Kafka одинаковы – их не нужно дополнительно сопоставлять и согласовывать;
- Merced хранит данные в AWS S3, сохраняя исходный порядок событий и разделы с небольшими затратами на инфраструктуру;
- воспроизведение данных через Merced аналогично чтению исходных данных из Kafka.
Реализовать этот дизайн единого API для исторических и оперативных данных дата-инженеры Pinterest решили с помощью Apache Flink.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
1 августа, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Единый API для оперативных и исторических данных
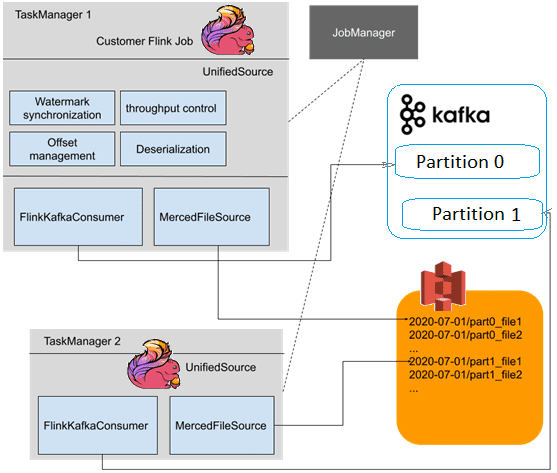
В решении Pinterest реализован класс UnifiedSource расширяет RichParallelSourceFunction — базовый класс для реализации параллельного источника данных. После выполнения среда выполнения выполнит столько параллельных экземпляров этой функции, насколько настроен параллелизм источника. Источник данных имеет доступ к контекстной информации (количество параллельных экземпляров источника и какой из них является текущим экземпляром) через метод AbstractRichFunction.getRuntimeContext(). Он также предоставляет дополнительные методы жизненного цикла: AbstractRichFunction.open() и AbstractRichFunction.close(). Каждая подзадача запускает один экземпляр UnifiedSource, а каждый экземпляр запускает коннекторы FlinkKafkaConsumer и MercedFileSource. Напомним, в новой версии Apache Flink 1.14 коннектор FlinkKafkaConsumer объявлен устаревшим и заменен на KafkaSource. А разработанный Pinterest коннектор MercedFileSource преобразует вывод Merced в потоковый формат.
Во время планирования разделов коннекторы FlinkKafkaConsumer и MercedFileSource в одной подзадаче гарантированно получат данные, принадлежащие одному разделу, обеспечивая плавный переход от чтения файла к Kafka. Чтобы получить все файлы, принадлежащие одному разделу, MercedSource прослушивает топик Kafka с помощью системы уведомлений сервиса Merced, позволяя обрабатывать опоздавшие события.
Объединенные выходные данные распределяются по разделам каждый час, а в именах файлов S3 кодируется время создания и раздел Kafka. Поэтому коннектор MercedFileSource может читать файлы и воссоздавать тот же порядок событий и разбиение на разделы. Класс UnifiedSource для реализации единого API использует лучшие практики Flink для создания водяных знаков из Kafka. Так удалось стандартизировать создание водяных знаков в приложениях Flink, а MercedFileSource объединяет обновления водяных знаков нескольких разделов в один поток. Сервис Merced наблюдает за поздними событиями в Kafka и записывает их в предыдущие разделы данных, которые уже были использованы UnifiedSource. Если перекос времени события в нескольких разделах Merced приводит к постоянно растущему разрыву водяных знаков, возникает рассинхрон контрольных точек далее по потоку. Поэтому дата-инженеры Pinterest реализовали синхронизацию водяных знаков между подзадачами с помощью public-интерфейса GlobalAggregateManager, который предоставляет доступ к временным именованным глобальным агрегатам, чтобы использовать это для совместного состояния между параллельными задачами в одном задании. Он не предназначен для обновлений с высокой пропускной способностью, а агрегаты не выдерживают сбоя задания. Каждый вызов метода updateGlobalAggregate() приводит к сериализованному обмену данными RPC с JobMaster, поэтому интерфейс GlobalAggregateManager следует осторожно. В Pinterest с его помощью обеспечивается глобальность диапазона водяных знаков.
О том, как выполняется контроль сетевого трафика и синхронизация разных источников данных, мы расскажем в следующий раз. Другой кейс совместного использования Apache Flink и Kafka для высоконагруженной системы онлайн-платежей смотрите в нашей новой статье. А как практически использовать Apache Flink и Kafka для разработки распределенных приложений аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка данных с помощью Apache Flink
- Apache Kafka для разработчиков
- Hadoop для инженеров данных

