
Сегодня рассмотрим, что такое Data Build Tool, как этот ETL-инструмент связан с корпоративным хранилищем и озером данных, а также чем полезен дата-инженеру. В качестве практического примера разберем кейс подключения DBT к Apache Spark, чтобы преобразовать данные в таблице Spark SQL на Amazon Glue со схемой поверх набора файлов в AWS S3.
ETL/ELT в эпоху Big Data: что такое Data Build Tool и как это работает
ETL-процессы являются неотъемлемой частью построения корпоративного хранилища или озера данных (Data Lake). Из всех этапов Extract — Transform – Load, именно преобразования являются наиболее нетривиальными, а потому трудозатратными операциями, т.к. здесь с извлеченными данными выполняется целый ряд действий:
- преобразование структуры;
- агрегирование;
- перевод значений;
- создание новых данных;
- очистка.
Для автоматизации всех этих работ используются специальные инструменты, например, Data Build Tool (DBT). DBT обеспечивает общую основу для аналитиков и дата-инженеров, позволяя строить конвейеры преобразования данных со встроенной CI/CD-поддержкой и обеспечением качества (data quality) [1].
При том, что DBT не выгружает данные из источников, он предоставляет широкие возможности по работе с теми данными, которые уже загружены в хранилище, компилируя SQL-запросы в код. Так можно организовать различные задачи преобразования данных в проекты, чтобы запланировать их для запуска в автоматизированном и структурированном порядке.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
17 июня, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
DBT-проект состоит из директорий и файлов следующих типов:
- файл модели (.sql) — единица трансформации в виде SELECT-запроса;
- файл конфигурации (.yml) — параметры, настройки, тесты и документация.
Работа DBT-фреймворка устроена так [2]:
- пользователь создает код моделей в среде разработки;
- модели запускаются через CLI-интерфейс;
- DBT компилирует код моделей в SQL-запросы, абстрагируя материализацию в команды CREATE, INSERT, UPDATE, DELETE ALTER, GRANT и пр.;
- каждая SQL-модель включает SELECT-запрос, определяющий результат – итоговый набор данных;
- код модели — это смесь SQL и языка шаблонов Jinja;
- скомпилированный SQL-код исполняется в хранилище в виде графа задач или дерева зависимостей модели, DAG (Directed Acyclic Graph — направленный ациклический граф);
- DBT строит граф по конфигурациям всех моделей проекта, с учетом их ссылок (ref) друг на друга, чтобы запускать модели в нужной последовательности и параллельно формировать витрины данных.
Кроме формирования самих моделей, DBT позволяет протестировать предположения о результирующем наборе данных, включая проверку уникальность, ссылочной целостности, соответствия списку допустимых значений и Not Null. Также возможно добавление пользовательских тестов (custom data tests) в виде SQL-запросов, например, для отслеживания % отклонения фактических показателей от заданных за день, неделю, месяц и прочие периоды. Это позволяет найти в витринах данных нежелательные отклонения и ошибки.
Благодаря адаптерам, DBT поддерживает работу со следующими базами и хранилищами данных: Postgres, Redshift, BigQuery, Snowflake, Presto, Apache Spark SQL, Databrics, MS SQL Serves, ClickHouse, Dremio, Oracle Database, MS Azure Synapse DW. Также можно создать собственный адаптер для интеграции с другим хранилищем, используя стратегию материализации. Этот подход сохранения результирующего набора данных модели в хранилище основан на следующих понятиях [2]:
- Table — физическая таблица в хранилище;
- View — представление, виртуальная таблица в хранилище.
Кроме того, DBT предоставляет механизмы для добавления, версионирования и распространения метаданных и комментариев на уровне моделей и даже отдельных атрибутов. А макросы в виде набора конструкций и выражений, которые могут быть вызваны как функции внутри моделей, позволяют повторно использовать SQL-код между моделями и проектами. Встроенный в DBT менеджер пакетов позволяет пользователям публиковать и повторно использовать отдельные модули и макросы [2].
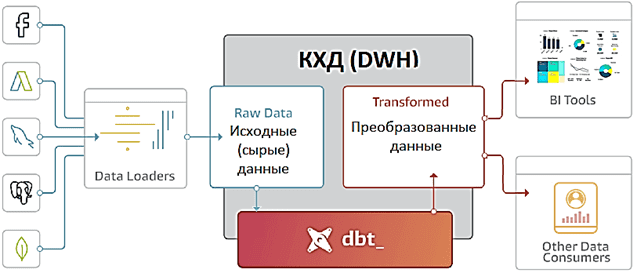
В качестве практического примера использования DBT рассмотрим кейс со Spark SQL, развернутом в облачных сервисах AWS.
Агрегация журналов AWS CloudTrail в Spark SQL
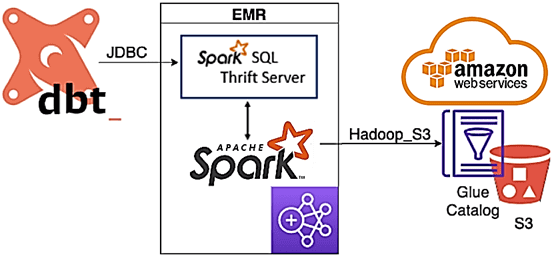
Предположим, требуется считать логи AWS CloudTrail, извлекая из них некоторые поля данных, чтобы создать новую таблицу и агрегировать некоторые данные для простого отчета. Источником является существующая таблица AWS Glue, созданная поверх журналов AWS CloudTrail, хранящихся в S3. Эти файлы имеют формат JSON, причем каждый файл содержит один массив или записи CloudTrail. Таблица Spark SQL на самом деле является таблицей Glue, которая представляет собой схему, помещенную поверх набора файлов в S3.
Альтернативой каталога хранения метаданных Hive Catalog выступает Glue Catalog — реализация от AWS с S3 вместо HDFS. В качестве кластера Hadoop выступает AWS EMR с установленным Apache Spark.
Анализ данных с Apache Spark
Код курса
SPARK
Ближайшая дата курса
13 мая, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
DBT, установленный на небольшом экземпляре AWS EC2 за пределами кластера EMR, будет использоваться для выполнения последовательных преобразований, создания и заполнения данных в таблицах. Подробные примеры реализации SQL-запросов представлены в источнике [1], а здесь мы перечислим некоторые важные особенности интеграции DBT с Apache Spark, развернутом в AWS:
- для подключения DBT к Spark с помощью модуля dbt-spark требуется сервер Spark Thrift;
- DBT и dbt-spark не накладывают ограничений на преобразование данных, позволяя использовать в моделях Data Build Tool любые SQL-запросы, поддерживаемые Spark;
- стратегия материализации DBT поддерживает базовые оптимизации Spark SQL, в частности, разбиение на разделы/сегменты Hive и разделение вывода Spark с помощью Spark SQL hints;
- доступ к порту 10001 сервера Thrift позволяет получить доступ ко всем авторизациям Spark SQL в AWS Обойти эту уязвимость можно, ограничив доступ к порту 10001 в кластере EMR только сервером, на котором запущен DBT. Самый простой вариант – ручная настройка с явным указанием IP-адреса главного узла. В production для EMR рекомендуется создать запись Route53. О других особенностях работы Spark-приложений с AWS S3 читайте здесь.
- при невысокой загрузке можно запускать DBT в управляемом сервисе оркестрации контейнеров Amazon Elastic Container Service (ECS), отключив отключить кластер EMR, чтобы сократить расходы на аналитику больших данных.
Data Build Tool для инженеров данных
Код курса
DBT
Ближайшая дата курса
25 июня, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Читайте в нашей новой статье про преимущества совместного использования dbt с Apache AirFlow. А научиться применять эти инструменты вместе с Apache Spark для разработки распределенных приложений аналитики больших данных и построения эффективных конвейеров обработки информации, вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Data Build Tool для инженеров данных
- Data Pipeline на Apache Airflow
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники

