Сегодня рассмотрим, почему наблюдаемость данных так важная для проектов Big Data, какие компоненты обеспечивают ценную информацию о качестве и надежности данных, чем это похоже на DataOps, а также как эти идеи реализовать на практике с использованием популярных инструментов современной дата-инженерии.
Почему важна наблюдаемость данных
Цифровизация предполагает управление на основе качественных данных, которым можно доверять, т.е. точных, релевантных и актуальных. Причем точность – не единственная характеристика качества данных. Подобно продуктам питания, данные имеют ограниченный срок годности – период, в течение которого они корректно отражают реальность. Сегодня мир меняется настолько быстро, что данные 24-часовой давности уже могут стать уже безнадежно устаревшими. А по мере роста количества и разнообразия источников данных их срок годности в некоторых доменах снижается до пары часов. На длительность срока годности данных влияет их время простоя, когда они еще ожидают обработки или заняты в процессах очистки и обогащения. Время простоя данных, когда они являются частичными, ошибочными, отсутствующими или неточными, увеличивается по мере усложнения экосистемы источников и потребителей.
Для дата-инженеров и разработчиков простои данных означают потерю времени и ресурсов, а для бизнес-пользователей это подрывает уверенность в принятии решений в рамках data-driven управления. Однако, зачастую вместо комплексного подхода к решению проблемы простоя данных команды предпочитают работать в режиме тушения пожаров, исправляя локальные недостатки Data Quality разовой основе. Это не соответствует популярной сегодня концепции DataOps, которая, аналогично DevOps, направлена на интеграцию процессов разработки и сопровождения данных для повышения эффективности корпоративного управления и отраслевого взаимодействия за счет распределенного сбора, централизованной аналитики и гибкой политики доступа к информации с учетом ее конфиденциальности, ограничений на использование и соблюдения целостности.
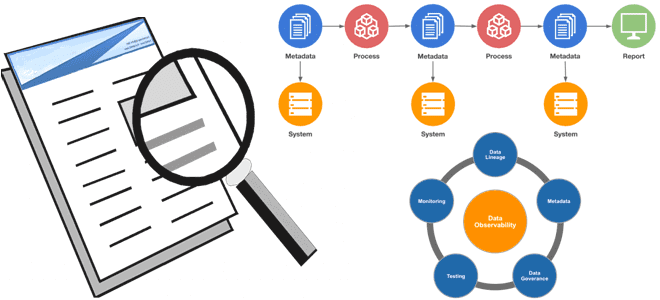
Особое внимание DataOps уделяет наблюдаемости данных (data observability), которая обеспечивает их прозрачность и качество. Цель наблюдаемости данных – снизить время их простоя и гарантировать релевантность реальности в любой момент времени, а также уменьшить вероятность ошибок в бизнес-решениях из-за некорректной информации. Можно рассматривать наблюдаемость данных как способность организации полностью понимать состояние данных в своих системах. В DevOps наблюдаемость включает мониторинг, отслеживание и сортировку инцидентов с ПО для предотвращения простоев с помощью следующих инструментальных средств:
- метрики — числовое представление данных в привязке к временному периоду;
- логи — записи о событии, произошедшем в заданную временную метку;
- трассировки — причинно-следственные события в распределенной среде.
Подобно тому, как DevOps использует подход CI/CD к разработке и эксплуатации ПО, DataOps стремится обеспечить безбарьерное сотрудничество дата-инженеров и специалистов по анализу данных, чтобы повысить их ценность для бизнеса. Это соответствует идеям цифровизации бизнеса и устраняет время простоя данных, применяя лучшие DevOps-практики к наблюдению за конвейером данных.
Инструменты data observability используют автоматизированный мониторинг конвейеров обработки данных и сортировку обнаруженных проблем с генерацией соответствующих оповещений для быстрого принятия мер по устранению выявленных инцидентов. Можно сказать, что наблюдаемость данных основана на следующих ключевых компонентах:
- свежесть данных, т.е. их актуальность релевантному сроку годности и частота обновления;
- распределение данных, т.е. их нахождение в допустимом диапазоне;
- объем как мера полноты данных дает представление о состоянии источников. К примеру, если обычно получаемые 200 миллионов строк в сутки вдруг превратились в 5 миллионов, это может свидетельствовать о неполадках с источником данных или узком месте конвейера.
- схема данных обеспечивает их организацию в обрабатываемые и хранимые структуры. Поэтому изменение схемы часто связано с повреждением данных, а оперативное отслеживание того, кто и когда вносит изменения в эти структуры, дает основу для понимания состояния всей экосистемы данных.
- происхождение данных (lineage) позволяет понять, какие вышестоящие источники и нижестоящие получатели данных были затронуты сбоем, например, из-за изменения схемы или объема, а также, какие команды генерируют данные и кто имеет к ним доступ. Lineage также включает информацию о данных (метаданные), которые относятся к управлению, бизнесу и техническим рекомендациям, связанным с конкретными таблицами данных, и служат единым источником достоверной информации для всех потребителей.
Все эти компоненты выявляют инциденты простоя данных, как только они возникают, обеспечивая целостную структуру наблюдаемости для подлинной сквозной надежности. Решения для наблюдения за данными не просто отслеживают эти компоненты, но и предотвращают попадание неверных данных в производственные конвейеры благодаря следующим возможностям:
- подключение к существующему стеку без изменений самих конвейеров данных, разработки нового кода или использования определенного языка программирования. Это позволяет быстро окупить затраты и обеспечить максимальный охват тестированием без существенных вложений.
- отслеживание данных в состоянии покоя без их фактического извлечения из места хранения. Это позволяет решению для наблюдения за данными быть производительным, масштабируемым и экономичным, а также гарантирует безопасность.
- минимальная настройка без ручной установки пороговых значений. Лучшие инструменты наблюдения за данными должны использовать модели машинного обучения для автоматического изучения среды и данных. Средства обнаружения аномалий генерируют оповещения в атипичных ситуациях, сводя к минимуму ложные срабатывания и избавляя дата-инженера от рутинных операций настройки и поддержки правил наблюдения.
- широкий контекст, который позволяет «на лету» определить ключевые ресурсы, зависимости и различные сценарии, чтобы получить глубокую наблюдаемость данных без особых усилий, быстро сортировать и устранять неполадки, а также эффективно общаться со всеми стейкхолдерами, на которых влияют проблемы с надежностью данных. Это формирует обширную информацию об активах данных, позволяя ответственно вносить изменения.
В отличие от тестирования, наблюдаемость данных обеспечивает сквозное покрытие, масштабируемость и отслеживание их происхождения, позволяя анализировать воздействие изменений. Наблюдаемость данных – это не просто мониторинг их качества, а способ иметь представление обо всех активах данных и атрибутах. Например, мониторинг данных выдает предупреждение, если значение выходит за пределы ожидаемого диапазона, данные не обновляются должным образом или объем обрабатываемых данных вдруг резко сократился/увеличился. Мониторинг выдает оповещения на основе заранее определенных шаблонов, представляя данные в виде агрегатов и средних значений. Сформировать эти шаблоны невозможно без data observability, только на основе результатов тестирования данных. Наблюдаемость ускоряет переход от вопроса «что» к ответу «почему», позволяя не только отслеживать данные, но и обеспечивать их качество в измерениях точности, полноты, согласованности, своевременности, достоверности и уникальности.
Наконец, наблюдаемость данных является неотъемлемой частью цифровой трансформации компаний и дает основу эффективного управления данными как процесса обеспечения их доступности, удобства использования, происхождения и безопасности данных, гарантируя доверие к ним на всех этапах жизненного цикла. Как реализовать эти идеи на практике, рассмотрим далее.
Инструментальные средства Data Observability
Реализовать весь рассмотренный широкий набор требований к функциональным возможностям средства наблюдения за данными в рамках одной технологии довольно сложно. К примеру, фреймворки пакетной и потоковой обработки типа Apache Spark, Flink, NiFi, AirFlow, Kafka и пр. часто используются в качестве основы построения конвейера обработки больших данных, однако, они не обеспечивают полный цикл сопровождения их метаданных и сами требуют дополнительных инструментов визуализации и генерации оповещений. Поэтому для масштабных проектов и крупных data-driven организаций со множеством источников, приемников и конвейеров обработки данных целесообразно выбирать готовые комплексные системы data observability, кастомизируемые под потребности заказчика.
Рассмотрим наиболее популярные из них:
- Monte Carlo — комплексное решение для предотвращения сбоев в конвейерах данных, которое включает возможности наблюдения и помогает дата-инженерам обеспечивать надежность и избегать потенциально дорогостоящих простоев данных. Monte Carlo включает каталоги данных, автоматическое оповещение и возможность наблюдения по нескольким критериям. Для получения первоначальных результатов не требуется ручная настройка, а бизнес-данные не покидают инфраструктуру пользователя – решение работает только с метаданными.
- Databand — платформа на основе искусственного интеллекта поможет обнаружить, где конвейеры данных сломались, прежде чем это отразиться на бизнес-пользователях. Databand предоставляет инженерным командам утилиты для обеспечения бесперебойной работы, позволяя получить единое представление о потоках данных. Это помогает обеспечить успешное завершение конвейеров, сохраняя строгий учет потребления ресурсов и затрат. Databand совместим с Apache Airflow, Snowflake и прочими инструментами дата-инженерии и машинного обучения.
- Acceldata Suite предоставляет инструменты для мониторинга конвейера данных, надежности данных и наблюдаемости данных в сложных многокомпонентных системах. Это популярный инструмент в сфере финансов, он отлично подходит для синтеза сигналов между несколькими слоями и рабочими нагрузками на одной панели. Это позволяет многочисленным командам работать вместе для обеспечения надежности путем прогнозирования, выявления и устранения проблем с данными. Но пользователи иногда сообщают о проблемах при настройке метрик и получении данных из внешних источников.
- Soda — платформа наблюдения за данными на основе искусственного интеллекта, которая включает среду совместной работы для владельцов данных, дата-инженеров и аналитиков. Можно быстро проверить свои данные и создать правила для их верификации и валидации, а также программного реагирования на неуспешные тесты. В частности, можно немедленно остановить процессы обработки и поместить данные в карантин. Платформа предоставляет инструмент командной строки Soda SQL для сканирования данных и просмотра результатов.
- Observe.ai специализируется на контакт-центрах, чтобы дать своим пользователям полную видимость взаимодействия бренда с клиентами. В отличие от других рассмотренных инструментов наблюдения за данными, Observe.ai поставляется с автоматическим распознаванием речи, поддержкой агента и обработкой естественного языка. Здесь речь идет не об обеспечении надежности данных, а скорее о повышении производительности агентов и повышении качества обслуживания клиентов. Observe.ai идеально подходит для контакт-центров и служб поддержки клиентов, помогая выявлять проблемы и возможности сервисного обслуживания.
Также к инструментальным средствам data observability относятся Appdynamics Business Observability Platform, Amazon CloudWatch, Datadog Observability Platform, Dynatrace, Elastic Observability, Instana, Lightstep, New Relic One, Splunk Observability Cloud, StackState и пр. Читайте в нашей новой статье про трудности отслеживания data lineage в приложениях Apache Spark и способах их обхода от разработчиков платформы data observability Monte Carlo и не только. А про наблюдаемость программных систем с использованием этих и других инструментальных средств мы рассказываем здесь.
Как внедрить принципы и инструменты обеспечения наблюдаемости данных в свою ИТ-инфраструктуру на практике, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Аналитика больших данных для руководителей
- Data Pipeline на Apache Airflow
- Data pipeline на Apache AirFlow и Arenadata Hadoop
Источники

