
Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh.
Что такое Delta Sharing и при чем здесь Data Lake
Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и сделать его безопасным, в 2021 году компания Databricks, которая развивает и коммерциализирует решения на основе Apache Spark, выпустила новый проект с открытым исходным кодом под названием Delta Sharing. Этот проект позиционируется как открытый протокол для безопасного обмена большими наборами данных в режиме реального времени. Он не просто так содержит в названии слово Delta, будучи связанным с другим продуктом Databricks — Delta Lake — коммерческой платформой, которая поддерживает ACID-транзакции и масштабируемую обработку метаданных, объединяя потоковые и пакетные операции с большими данными. Delta Lake развертывается поверх озера данных на HDFS, AWS S3, Azure Data Lake Storage (ADLS), Google Cloud Storage (GCS) и является полностью совместимой со всеми API Apache Spark. Подробнее о преимуществах и принципах работы Delta Lake мы писали здесь.
По сути, Delta Sharing представляет собой REST API, который обеспечивает безопасный доступ к части облачного набора данных. Он использует современные облачные системы хранения, такие как S3, ADLS или GCS, для надежной передачи больших наборов данных. В качестве поставщика данных, Delta Sharing позволяет совместно использовать существующие таблицы или их части (например, определенные версии таблиц разделов), хранящиеся в облачном озере данных в формате Delta Lake. Таблица Delta Lake обычно представляет собой набор Parquet-файлов. Поставщик данных решает, какими данными он хочет поделиться, и запускает перед ним сервер обмена, который реализует протокол Delta Sharing и управляет доступом для получателей. Чтобы получатель мог использовать эти данные, нужен клиент Delta Sharing с подходящим коннектором, например, Pandas, Apache Spark, Rust и пр.
Таким образом, с помощью Delta Sharing пользователи могут напрямую подключаться к общим данным через pandas, Tableau или десятки других форматов и систем, реализующих открытый протокол, без необходимости предварительного развертывания конкретной платформы. Это ускоряет время обработки данных и расширяет области их использования, позволяя фактически реализовывать ETL-конвейеры для разных озер данных даже за пределами одного предприятия.
Delta Sharing разработан так, чтобы поставщики и получатели могли использовать свои существующие данные и рабочие процессы, делясь данными в реальном времени напрямую, без предварительного копирования. Delta Sharing позволяет безопасно обмениваться любым существующим набором данных в форматах Delta Lake или Apache Parquet. Получатели могут использовать данные, обрабатывая их имеющимися инструментами, без установки новой платформы, поскольку Delta Sharing основан на Parquet, который уже поддерживается многими фреймворками.
Реализуя требования к безопасности и защите данных, Delta Sharing позволяет предоставлять, отслеживать и проверять доступ к общим данным из единой точки контроля. А, чтобы сделать это эффективным с точки зрения экономики, Delta Sharing ориентирован на облачные системы хранения данных.
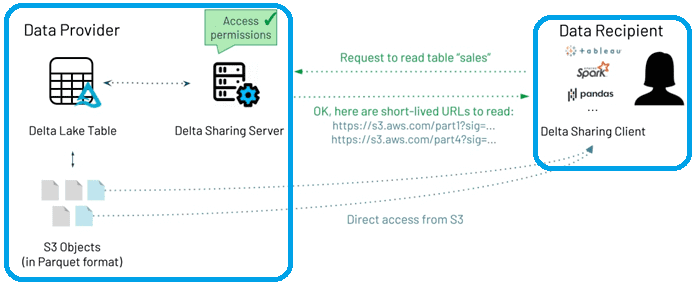
Как это работает и чем полезно в децентрализованной архитектуре данных
Delta Sharing работает следующим образом:
- клиент получателя аутентифицируется на сервере обмена (через токен носителя или другим способом) и запрашивает запрос к конкретной таблице, в т.ч. с использованием фильтров WHERE в качестве подсказки для чтения только подмножества данных.
- сервер проверяет, разрешен ли клиенту доступ к данным, регистрирует запрос, а затем определяет, какие данные отправить обратно. Это будет подмножество объектов данных в S3 или других облачных системах хранения, которые фактически составляют таблицу.
- для передачи данных сервер генерирует предварительно подписанные краткосрочные URL-адреса, которые позволяют клиенту читать эти Parquet-файлы непосредственно из облачного провайдера, чтобы распараллелить это с большой пропускной способностью без потоковой передачи через сервер обмена.
Таким образом, поставщики данных могут надежно обновлять данные в режиме реального времени с помощью ACID-транзакций в Delta Lake, и получатели всегда будут видеть согласованное представление. Причем получателям данных не обязательно находиться на той же платформе, что и поставщик, или обязательно иметь облачную инфраструктуру: общий доступ работает между облаками и даже между облаком и локальными пользователями.
Delta Sharing уже поддерживается многими популярными BI-системами (Tableau, Qlik, Power BI), аналитическими хранилищами (AtScale, Dremio, Starburst, Microsoft Azure, Google BigQuery) и поставщиками данных (FactSet, Nasdaq, Precisely, Safegraph, Atlassian, AWS, Foursquare, ICE, Qandl, S&P, SequenceBio).
Клиенты Databricks могут воспользоваться Delta Sharing через его встроенную интеграцию в каталог Unity, что обеспечит упрощенный обмен данными как внутри, так и между организациями. Администраторы могут управлять общими ресурсами с помощью нового синтаксиса CREATE SHARE SQL или REST API и централизованно проверять все доступы. А выдача и отзывы разрешений на доступ к целым таблицам или их части выдаются с помощью типовых команд grant/revoke.
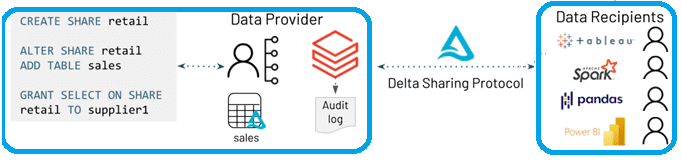
В Github-репозитории Delta Sharing находится не только его спецификация, но и коннектор Python — библиотека, которая реализует этот протокол для чтения общих таблиц как pandas DataFrame или Apache Spark DataFrames. Также представлен исходный код коннектора Apache Spark, который реализует протокол Delta Sharing для чтения общих таблиц с сервера Delta Sharing. Затем к таблицам можно получить доступ через конструкции на языках SQL, Python, Java, Scala или R. Коннектор получает доступ к общим таблицам на основе файлов профилей, которые представляют собой файлы JSON, содержащие учетные данные пользователя для доступа к серверу общего доступа Delta.
Таким образом, Delta Sharing позволяет реализовать новую децентрализованную архитектуру данных под названием Data Mesh, которая предполагает инфраструктуру самообслуживания, позволяющую владельцам продуктов публиковать активы доменных данных для их использования в смежных бизнес-процессах. Это ускоряет создание ценности аналитических данных и дает возможность выполнения сценариев, выходящих за рамки предметной области или бизнес-подразделения в режиме реального времени.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Практическое применение Big Data Аналитики для решения бизнес-задач
- Аналитика больших данных для руководителей
Источники

