Недавно мы рассказывали про новые функции свежего релиза Apache Hadoop 3.3.1. Сегодня разберем подробнее, что такое Erasure Coding и как эта технология кодирования со стиранием экономит место в распределенной файловой системе HDFS. Также заглянем внутрь EC и рассмотрим, чем алгоритм Рида-Соломона лучше ассоциативной операции XOR для обеспечения отказоустойчивости хранилища больших данных.
Что такое Erasure Coding и зачем это нужно в Hadoop HDFS
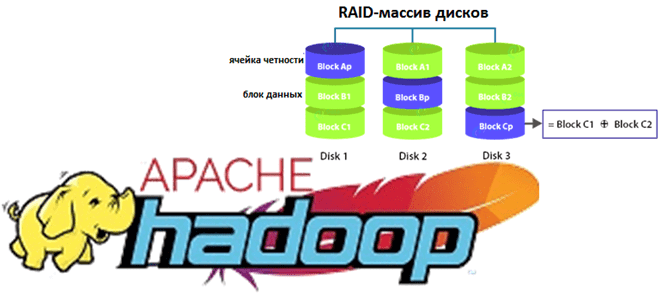
Начиная с версии 3.3.1, Apache Hadoop HDFS поддерживает технологию кодирования со стиранием (Erasure Coding, EC), которая экономит место на жестком диске по сравнению с репликацией. Cтандартная схема 3-кратной репликации в HDFS имеет 200% накладных расходов на пространство хранения и пропускную способность сети. Erasure Coding снижает накладные расходы на хранение данных до 50% независимо от коэффициента репликации за счет чередования, которое разделяет логически последовательные данные файла на более мелкие блоки (бит, байт или блок), сохраняя их на разных дисках недорогого RAID-массива. Для каждой полосы исходных ячеек данных вычисляется и сохраняется определенное количество ячеек четности. Этот процесс называется кодированием. Ошибка в любой чередующейся ячейке устраняется через обратную операцию декодирования на основе сохранившихся данных и ячеек четности. Например, файл с 3-кратной репликацией с 6 блоками HDFS без Erasure Coding будет занимать 6*3 = 18 блоков дискового пространства. А с поддержкой EC и 3-мя ячейками четности он занимает в 2 раза меньше дискового пространства – всего 9 блоков [1].
Таким образом, кодирование со стиранием может снизить накладные расходы на хранилище HDFS примерно на 50% по сравнению с репликацией, сохраняя те же гарантии долговечности и позволяя хранить вдвое больше данных на том же объеме хранилища.
Что касается математики, которую реализует технология Erasure Coding, то здесь используется алгоритм Рида-Соломона (Reed-Solomon, RS), который преодолевает ограничение алгоритма XOR. Операция XOR является ассоциативной и генерирует 1 бит четности из произвольного количества битов данных. Например, если данные столбца Y потеряны, то используя данные столбца X и ячейку четности, можно декодировать потерянные данные, сгенерировав Y снова. Но, поскольку алгоритм XOR генерирует только 1 бит четности для любого количества входных ячеек данных, он может выдержать только 1 сбой. Этого недостаточно для обеспечения высокой надежности HDFS, когда необходимо обрабатывать несколько сбоев. Отказоустойчивость алгоритма XOR равна единице, а эффективность хранения составляет 2/3, то есть 67%.
Алгоритм Рида-Соломона использует операцию линейной алгебры для создания нескольких ячеек четности, чтобы выдерживать множественные отказы. Здесь выполняется умножение m ячеек данных на матрицу генератора, чтобы получить расширенное кодовое слово с m ячейками данных и n ячейками четности. Если хранилище выходит из строя, то его можно восстановить, умножая обратную матрицу порождающей матрицы на расширенные кодовые слова до тех пор, пока доступны m из (m + n) ячеек. Отказоустойчивость RS-алгоритма приближается к n, то есть количество ячеек с проверкой четности и эффективность хранения составляет m/(m + n), где m — ячейка данных, а n — ячейка четности [2].
Основы Hadoop
Код курса
INTR
Ближайшая дата курса
22 апреля, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Что не так с технологией EC: ограничения и недостатки
Поскольку любое достоинство имеет свою цену, поддержка Erasure Coding увеличивает расходы на кластер Apache Hadoop по следующим причинам:
- дополнительное потребление ресурсов (ЦП и пропускная способность сети передачи данных) из-за процессов кодирования и декодирования на клиентах HDFS и самих узлах данных Hadoop-кластера;
- необходимость иметь количество узлов данных в кластере Hadoop не менее настроенной ширины полосы EC, равной числу блоков файловой системы. Например, для RS-алгоритма с 6 ячейками данных и 3-мя ячейками четности, RS (6,3), это означает минимум 9 узлов данных.
- необходимость иметь достаточное количество стоек в кластере, чтобы в среднем каждая из них содержала количество блоков, не более, чем число блоков четности EC. Это обеспечит отказоустойчивость, т.к. при чтении и записи файлов большинство операций выполняется вне стойки. Поэтому пропускная способность сети очень важна, а необходимое количество стоек вычисляется по формуле A+B/B с округлением в большую сторону, где А – это блоки данных, B – это блоки четности. Например, для EC-политики c RS (6,3) необходимо как минимум 3 стойки = (6 + 3)/3 = 3. А чтобы справиться с плановыми и внеплановыми отключениями, авариями и другими отказами, лучше иметь 9 стоек. Если в кластере Hadoop количество стоек меньше, чем количество ячеек четности, HDFS не может поддерживать отказоустойчивость каждой стойки. Однако, при этом распределенная файловая система попытается распределить чередующийся файл по нескольким узлам данных, чтобы сохранить отказоустойчивость на уровне узла. Поэтому рекомендуется устанавливать стойки с одинаковым количеством узлов данных.
Администрирование кластера Hadoop
Код курса
HADM
Ближайшая дата курса
22 апреля, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Однако, удорожание ИТ-инфраструктуры – не единственный недостаток Erasure Coding. На текущий момент эта технология имеет ряд ограничений, которые можно рассматривать как недостатки. В частности, некоторые операции HDFS (hflush, hsync, concat, setReplication, truncate и append) не поддерживаются для EC-файлов:
- append() – функция, которая добавляет один или несколько источников в файловую систему, и truncate(), которая обрезает все файлы, соответствующие указанному шаблону, до указанной длины, вызовут исключение ввода-вывода IOException;
- concat() – функция, которая объединяет существующие файлы из одного каталога в один, тоже сгенерирует исключение IOException для файлов с разными EC-политиками или с реплицированными файлами;
- метод установки коэффициента репликации setReplication() не работает для EC-файлов;
- hflush() – функция, очищающая пользовательский буфер клиента;
- hsync() – функция, гарантирующая, что все данные будут записываться на диск.
Функции hflush() и hsync() из пакета java.io для распределенной файловой системы DFSStripedOutputStream не используются, т.к. не могут гарантировать постоянство данных. Чтобы понять, поддерживает ли OutputStream функции hflush() и hsync(), можно использовать API StreamCapabilities. Этот интерфейс предоставляет способ программно запрашивать возможности, которые поддерживает OutputStream, InputStream или другой класс файловой системы FileSystem. Если необходимо сохранить данные с помощью hflush() и hsync(), можно создать обычные файлы 3-хкратной репликации в каталоге без Erasure Coding или сохранить их в каталог с поддержкой EC с помощью метода replicate() из API FSDataOutputStreamBuilder.
Из-за отмеченных ограничений проекты на базе Apache Hadoop, которые работают с горячими данными, будут использовать старый добрый механизм репликации, который, хоть и занимает больше места в HDFS, но проще и дешевле по сравнению с Erasure Coding. Однако, поскольку EC-технология позволяет экономить место в HDFS, она отлично подойдет для работы с холодными данными, которые используются не так активно [2]. О том, как EC использовалась в Одноклассниках и какими проблемами это обернулось, читайте в нашей новой статье. А лучшие практики конфигурирования HDFS мы описываем здесь.
Hadoop для инженеров данных
Код курса
HDDE
Ближайшая дата курса
17 июня, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Больше практических деталей про администрирование и эксплуатацию Apache Hadoop для хранения и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

