Зачем нужна Python-библиотека Evidently, и как она помогает специалистам по Data Science выявлять дрейф данных моделей Machine Learning в производственной среде. Знакомимся с еще одним MLOps-инструментом.
Что такое дрейф данных, чем это опасно и как его обнаружить
В отличие от многих других информационных систем, проекты машинного обучения очень сильно зависят от данных. Если производственные данные, которые поступают в ML-модель, радикально отличаются от тех, на которых она обучалась, встроенные в нее алгоритмы становятся неэффективны. Этот эффект называется дрейф данных и обычно случается из-за изменения поведения исследуемых объектов в реальном мире с течением времени или изменения меры оценки качества модели. Как правило, при этом статистические свойства входных данных меняются, что приводит к сдвигу в их распределении. Если вовремя не обнаружить дрейф данных, т.е. до того, как он негативно повлияет на результаты моделирования, прогнозы Machine Learning будут ошибочными. Например, риэлторская компания Zillion, базирующаяся в Сиэтле, в результате дрейфа данных своих ML-моделей понесла убытки в размере около $300 миллионов из-за ошибочных прогнозов цен после резких изменений на рынке недвижимости из-за пандемии COVID-19.
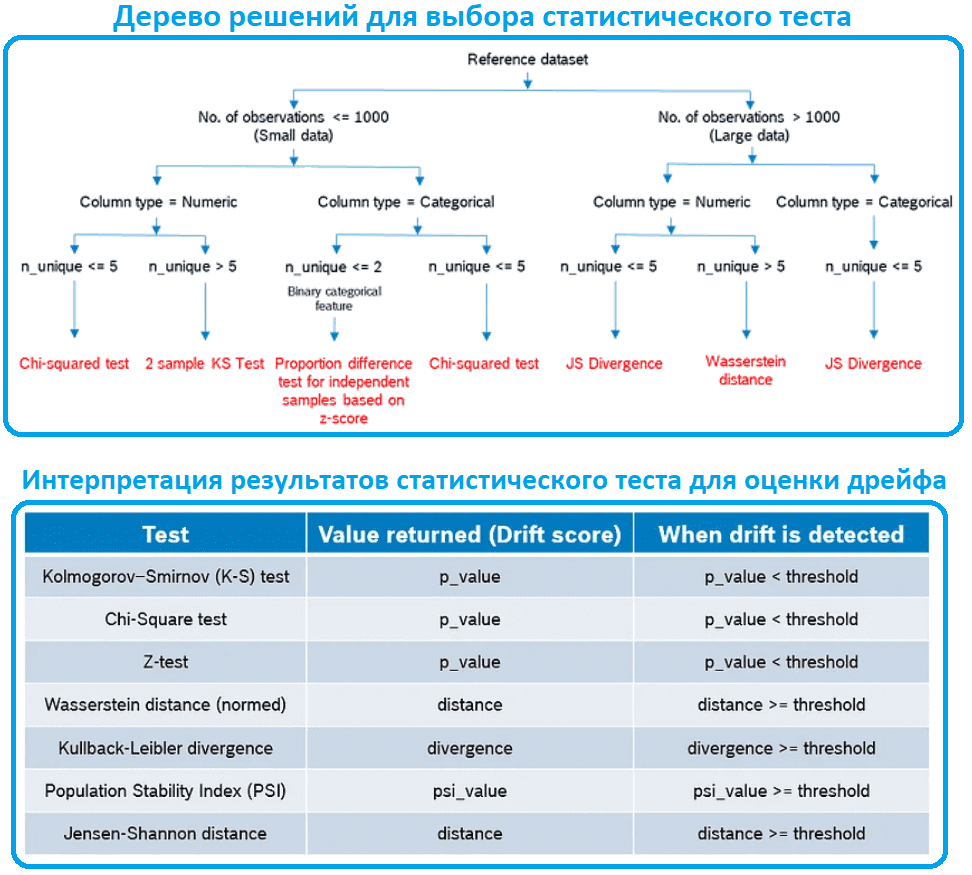
Поскольку дрейф данных обычно вызван изменением их статистических свойств, для обнаружения этого является используются статистические тесты, такие как тест Колмогорова-Смирнова, индекс стабильности распределения, тест Кульбака-Лейблера, тест Дженсена-Шеннона, метрика Вассерштейна, критерий хи-квадрат и Z-тест. Автоматизировать выполнение этих тестов позволяют современные MLOps-инструменты, одним из которых является Python-библиотека мониторинга ML-моделей с открытым исходным кодом, разработанная компанией Evidently.ai. Далее рассмотрим, как она работает.
MLOps c библиотекой Evidently
Evidently — это Python-библиотека с открытым исходным кодом для специалистов по Data Science и инженеров машинного обучения, которая помогает оценивать, тестировать и отслеживать производительность ML-моделей на любом этапе их жизненного цикла. Библиотека включает 3 компонента: отчеты, тесты и интерактивные дэшборды, чтобы охватить все возможные варианты использования MLOps-инженера, от визуального анализа до автоматизированного тестирования конвейера и мониторинга в реальном времени. Пользователю необходимо предоставить входные данные, выбрать объект оценки и указать формат вывода. Evidently предоставляет простой декларативный API, а также библиотеку метрик, тестов и визуализаций, которые можно интегрировать в различные стеки машинного обучения в качестве компонента мониторинга или валидации.
В настоящее время библиотека работает с табличными и текстовыми данными, позволяя выполнять проверку качества структурированных данных и моделей машинного обучения с помощью набора пакетных тестов. В зависимости от типа данных, количества наблюдений в эталонном датасете и числу уникальных значений в столбце, библиотека подбирает наиболее подходящий статистический тест. После применения этого теста к эталонным и текущим данным, пользователю возвращается результат – оценка дрейфа, которая показывает его наличие или отсутствие. Во всех тестах по умолчанию используется уровень достоверности 0,95, а для всех показателей по умолчанию используется пороговое значение 0,1. При желании MLOps-инженер может изменить эти значения по своему усмотрению.
В заключение отметим, что использовать Evidently следует как обычную Python-библиотеку. Сперва Data Scientist должен установить ее в свой ML-проект с помощью менеджера пакетов pip или conda, а затем импортировать необходимые модули:
pip install evidently from evidently.dashboard import Dashboard from evidently.dashboard.tabs import DataDriftTab from evidently.options import DataDriftOptions
Далее следует загрузить эталонные и реальные данные, а затем рассчитать оценку дрейфа, используя методы библиотеки Evidently. При желании результаты можно визуализировать в виде графика, сформировать отчет или вести непрерывный мониторинг, следя за нужными метриками на интерактивном дэшборде.
Будучи легковесным, но полноценным MLOps-инструментом, библиотека отлично интегрируется с другими средствами разработки и развертывания моделей машинного обучения. Использовать эту библиотеку можно в Google Colab, Jupyter notebook, а также блокнотах Databricks и Deepnote. Evidently совместима с Apache AirFlow, позволяя отслеживать дрейф данных в масштабных ML-конвейерах. Также эта библиотеку можно использовать вместе с MLflow, Metaflow и Grafana.
Как применять эти и другие средства MLOps в проектах аналитики больших данных и машинного обучения, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

