
В этой статье для обучения дата-инженеров и аналитиков данных заглянем под капот Apache Hive, чтобы разобраться с механизмов LLAP. Как этот движок повышает производительность популярного SQL-on-Hadoop инструмента, поддерживая длительные процессы на одних и тех же ресурсах для кэширования и аналитической обработки больших данных.
Что такое LLAP в Apache Hive и зачем он нужен
Напомним, Apache Hive является популярным NoSQL-хранилищем стека SQL-on-Hadoop, позволяя обращаться к данным, хранящимся в HDFS, через ANSI-подобный язык SQL-запросов без разработки Java-кода с функциями MapReduce. Поэтому Hive активно используется в различных Data Science проектах и востребован у инженеров данных. Hive поддерживает 3 движка выполнения запросов: классический MapReduce, Spark и Tez, о чем мы писали здесь и здесь. LLAP работает поверх любого используемого движка выполнения SQL-запросов, повышая производительность этой NoSQL-СУБД. Подобно тому, как Spark может кэшировать (сохранять) данные в памяти или на диске, чтобы снова использовать их в том же задании, LLAP позволяет передавать кэшированные данные между заданиями.
Механизм Live Long And Process (LLAP) был добавлен в Apache Hive 2.0. Он не является механизмом запросов, а располагается поверх движка, чтобы сделать запросы и обработку данных намного быстрее. LLAP предоставляет гибридную модель выполнения. Он состоит из долгоживущего системного сервиса (демона), который заменяет прямое взаимодействие с узлом данных HDFS, и тесно интегрированной инфраструктуры на основе DAG. Демон обеспечивает такие функции, как кэширование, предварительная выборка, некоторая обработка запросов и контроль доступа. Небольшие короткие запросы обрабатываются этим демоном напрямую, а длительные задания выполняются в стандартных контейнерах YARN.
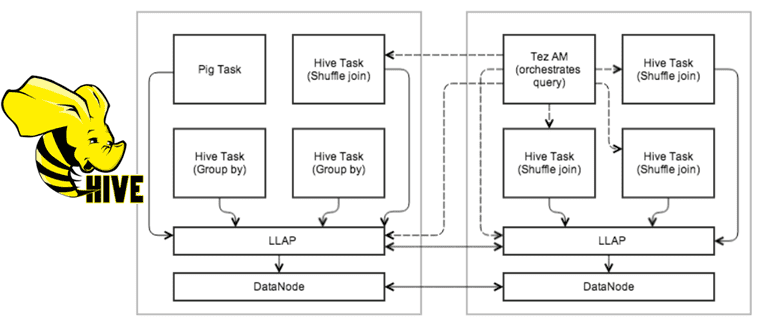
Подобно DataNode, демоны LLAP могут использоваться и другими приложениями, особенно если реляционное представление данных предпочтительнее, чем обработка, ориентированная на файлы. Демон также открыт через дополнительные API, например, InputFormat, которые могут использоваться другими платформами обработки данных в качестве строительного блока. Примечательно, что LLAP поддерживает детальное управление доступом на уровне столбцов.
Примечательно, что LLAP совершенно необязателен для запросов Hive. Его рекомендуется использовать только в том случае, если нужно повысить скорость отклика на запросы Hive как в интерактивном, так и в пакетном режимах. Даже при использовании LLAP, не все части запроса выполняются внутри него. LLAP берет на себя части запросов, которые могут выиграть от использования кэша или долгоживущих процессов. Именно механизмы запросов определяют, что может быть передано в LLAP, а что нет. Tez и другие фреймворки, такие как Pig, могут использовать LLAP. Движок MapReduce не поддерживает этот механизм.
Как устроен механизм Live Long And Process
Не стоит рассматривать LLAP как просто уровень кэширования и обработки в памяти. Лучше думать о нем как об еще одном приложении YARN, работающем на всех узлах данных в кластере Hadoop. Хотя LLAP долгоживущий процесс, он потребляет ресурсы активно. LLAP можно настроить на очень маленький процесс для обработки простых запросов или на динамическое увеличение и уменьшение масштаба. А, поскольку LLAP работает с YARN, он обладает всеми преимуществами этого диспетчера ресурсов, такими как распределенный характер и отказоустойчивость. Поэтому узлы демона LLAP могут общаться друг с другом и обмениваться данными между узлами. Еще одним преимуществом здесь является то, что сами процессы демона не требуют много ресурсов для работы. YARN выделяет минимум, необходимый для самих процессов, и увеличивает выделение ресурсов по мере необходимости в зависимости от рабочей нагрузки.
Чтобы избежать проблем с кучей или проблем с памятью JVM, кэшированные данные всегда хранятся вне кучи и в больших буферах. Таким образом, обработка агрегаций, таких как группировка и объединение, будет намного быстрее в LLAP по сравнению с механизмами запросов. Модель делегирования контейнера YARN используется для передачи выделенных ресурсов в LLAP. Чтобы избежать ограничений настроек памяти JVM, кэшированные данные хранятся вне кучи, а также большие буферы для обработки (например, группировка по, объединение). Таким образом, демон может использовать небольшой объем памяти, а дополнительные ресурсы (например, ЦП и память) будут выделяться в зависимости от рабочей нагрузки.
LLAP запускает процессы демонов на узлах данных, и эти демоны не привязаны к пользователю, отправляющему запросы Hive. Это позволяет LLAP повторно использовать кэшированные данные между пользователями. Таким образом, даже при запуске разными пользователями одинаковых запросов к одной и той же таблице, LLAP может использовать кэш, который уже доступен для них, что очень повысит производительность. Без LLAP запросы будут выполнять одни и те же операции по отдельности, что не очень оптимально.
Для частичного выполнения узлы LLAP выполняют фрагменты запроса, такие как фильтры, проекции, преобразования данных, частичные агрегаты, сортировку, группировку, хэш-соединения и пр. В LLAP принимаются только код Hive и UDF. Из соображений стабильности и безопасности код не локализуется и не выполняется на лету. Узел LLAP допускает параллельное выполнение нескольких фрагментов запроса из разных запросов и сеансов. Пользователи могут получить доступ к узлам LLAP напрямую через клиентский API, задавать реляционные преобразования и считывать данные через потоки, ориентированные на записи.
Демон LLAP разгружает ввод-вывод и преобразование из сжатого формата в отдельные потоки. Данные передаются на выполнение по мере их готовности, поэтому предыдущие пакеты могут быть обработаны, пока готовятся следующие. Данные передаются на выполнение в простом столбцовом формате с RLE-кодированием, который готов к векторизованной обработке и является форматом кэширования, чтобы сократить копирование между вводом-выводом, кэшем и выполнением.
Ввод-вывод и кэширование зависят от некоторого знания базового формата файла. Поэтому, как и в случае с векторизацией, различные форматы файлов будут поддерживаться с помощью плагинов, специфичных для каждого формата, начиная с ORC. Можно добавить общий менее эффективный плагин, который поддерживает любой формат ввода Hive. Плагины должны поддерживать метаданные и преобразовывать необработанные данные в фрагменты столбцов, предикаты и фильтры Блума. SARG и фильтры Блума переносятся на уровень хранения, если они поддерживаются.
Демон LLAP кэширует метаданные для входных файлов, а также данные. Метаданные и индексную информацию можно кэшировать даже для данных, которые в данный момент не кэшированы. Метаданные хранятся в процессе в объектах Java, а кэшированные данные хранятся в формате, описанном в разделе ввода-вывода, и хранятся вне кучи.
В LLAP политика вытеснения настроена для аналитических рабочих нагрузок с частым (частичным) сканированием таблиц. Изначально используется простая политика, такая как LRFU (Least Recently/Frequently Used) — алгоритм для хранения ограниченного объема данных: из хранилища вытесняется информация, которая не использовалась дольше всего. Его применяют при организации кэша. Фрагменты столбцов являются единицами данных в кэше. Так достигается компромисс между малой обработкой и эффективностью хранения. Степень детализации фрагментов зависит от конкретного формата файла и механизма выполнения: размер пакета векторизованных строк, полоса ORC и пр. Фильтр Блума создается автоматически для обеспечения динамической фильтрации во время выполнения. О том, что представляет собой эта структура данных, мы рассказывали здесь.
YARN используется для получения ресурсов для различных рабочих нагрузок. Как только ресурсы (ЦП, память и пр.) были получены от YARN для конкретной рабочей нагрузки, механизм выполнения может делегировать эти ресурсы LLAP или запускать исполнители Hive в отдельных процессах. Преимущество принудительного использования ресурсов через YARN в том, что узлы не перегружаются ни LLAP, ни другими контейнерами. Сами демоны находятся под контролем YARN.
Важно, что LLAP поддерживает материализованные представления и ACID-транзакции в Apache Hive. Слияние дельта-файлов для создания определенного состояния таблиц выполняется до того, как данные будут помещены в кэш. Также обеспечивается версионирование, и в запросе указывается, какая версия должна использоваться. Так достигается асинхронное и однократное выполнение слияния выполняется кэшированных данных, что позволяет избежать попадания в конвейер оператора.
Серверы LLAP поддерживают контроль доступа на детальном уровне, поскольку демоны знают, какие столбцы и записи обрабатываются, к этим объектам можно применять политики. Это не заменяет существующие механизмы, а расширяет их и открывает для других приложений.
Наконец, LLAP поддерживает мониторинг, конфигурации для которого хранятся в файлах resources.json, appConfig.json, metainfo.xml, которые встроены в templates.py, используемые Slider. Демон LLAP Monitor работает в контейнере YARN, подобно демону LLAP, и прослушивает тот же порт. Сервер сбора метрик LLAP периодически собирает метрики JMX от всех демонов LLAP, а список демонов LLAP извлекается из сервера Zookeeper, запущенного в кластере.
А как Hive работает с данными, хранящимися в Hadoop, сериализуя и десериализуя их, мы рассказываем в новой статье.
Освойте администрирование и эксплуатацию Apache Hive для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

