
Сегодня поговорим про ETL-процессы в мире Big Data на примере построения непрерывного конвейера поставки больших данных о транзакциях для сервисов машинного обучения. Читайте далее, из чего состоит типичная архитектура такой системы на базе Apache Kafka, Spark, HBase и Hive, а также почему большинство ETL-инструментов не подходят для потоковой передачи событий и как решить эту проблему с помощью платформ сбора и маршрутизации данных в реальном времени: NiFi, StreamSets Data Collector или Qlik Replicate.
Потоковый конвейер Big Data для ML-системы
Рассмотрим пример информационной системы, где технологии потоковой передачи Big Data обеспечивают данными сервис машинного обучения (Machine Learning, ML), который принимает решение об обработке платежей по кредитным картам [1]:
- Apache Kafka выступает источником данных для конвейера загрузки данных в корпоративное озер (Data Lake) на базе компонентов экосистемы Hadoop;
- потоки данных из топиков Kafka используются приложением Spark Streaming;
- приложение Spark Streaming загружает данные в NoSQL-СУБД Apache HBase, которая отличается высокой производительностью и позволяет отслеживать версии записей, обеспечивая задачи аналитики больших данных;
- задание Spark Streaming периодически извлекает данные из HBase и загружает их в Apache Hive;
- Hive как средство стека SQL-on-Hadoop дает возможность анализировать большие данные с помощью SQL-подобных запросов (HiveQL), что используется приложением машинного обучения;
- Приложение машинного обучения передает результаты ML-моделирования в сервис принятия решений Decision Service Engine (DSE);
- DSE используется приложением обработки платежей при утверждении транзакции по кредитной карте;
- результаты принятия решения по транзакции передаются обратно в базу данных записей, откуда их собирает Qlik Replicate и снова отправляет в ETL-конвейер Data Lake, чтобы обеспечить непрерывное обучение ML-моделей.
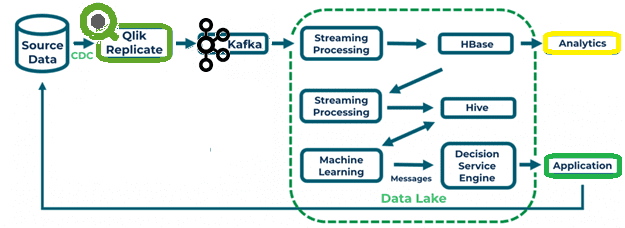
Подобная «зацикленная» архитектура типична для ML-систем, поскольку петля обратной связи обеспечивает непрерывное обучение моделей Machine Learning. При том, что Kafka выступает отправной точкой конвейера, данные в эту Big Data платформу могут попадать двумя способами:
- каждый источник данных публикует сообщения в свой топик с помощью соответствующего producer’а;
- отдельный ETL-инструмент собирает данные из множества разных источников и записывает их в Kafka.
С точки зрения дата-инженера 2-ой вариант предпочтительнее в случае большого количества разных источников данных, число которых может увеличиваться. Для автоматизации процесса сбора данных из разных источников с последующей загрузкой в единое место назначения существует множество ETL-инструментов. Большинство из них работают по пакетному принципу, что не подходит для потоковой обработки событий, т.е. в режиме real-time [1]. Однако, некоторые системы позволяют собирать и маршрутизировать данные в реальном времени, например, Apache NiFi или StreamSets Data Collector, о которых мы рассказывали здесь. Подобными возможностями обладает Qlik Replicate, о котором мы расскажем далее.
Что такое Qlik Replicate и как он работает с Apache Kafka
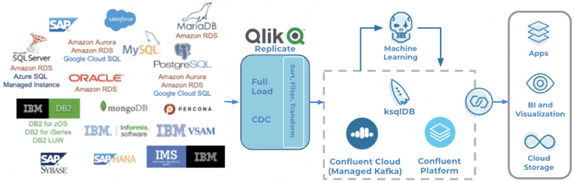
Qlik Replicate – это корпоративное решение с поддержкой ускоренной репликации, обработки и потоковой передачи данных в режиме реального времени для всех основных баз и хранилищ данных, а также Big Data платформ [2].
После загрузки выбранных таблиц в целевой объект высокопроизводительная технология сбора измененных данных (CDC, Change Data Capture) Qlik Replicate удаленно сканирует журналы транзакций и быстро доставляет обновления данных в реальном времени. Интуитивно понятный графический интерфейс сводит администрирование системы к минимуму, позволяя быстро настраивать, контролировать и отслеживать репликацию данных без необходимости ручного кодирования.
В процессе начальной загрузки Qlik Replicate считывает отфильтрованный поток строк (только с соответствующими столбцами) и передает их в процесс преобразования для дальнейшей фильтрации и последующей записи в целевую конечную точку (в ожидаемом формате вывода).
Процесс CDC получает поток отфильтрованных событий или изменений данных и метаданных из файла журнала транзакций. Затем он буферизует все изменения для данной транзакции в единый блок, прежде чем перенаправить их в целевое место при фиксации транзакции. Во время процесса начальной загрузки CDC также буферизует все изменения, происходящие в транзакции, до тех пор, пока все затронутые таблицы не будут загружены [3].
Таким образом, Qlik Replicate собирает данные из более чем 30 источников, включая локальные и облачные реляционные СУБД, устаревшие legacy-системы и проприетарные приложения, в частности, SAP. Qlik Replicate может доставлять данные в режиме реального времени в Kafka, обеспечивая быструю доставку информации в условиях высоких нагрузок, более 100 ГБ в час и сотни таблицы. Примечательно, что этот ETL-инструмент фильтрует и преобразует данные «на лету», поддерживает Confluent Schema Registry, автоматически создавая целевую схему данных и обрабатывая изменения исходного DDL, которые происходят после начала обработки. Наконец, Qlik Replicate выполняет CDC-сбор данных об изменениях на основе журнала для источников, которые он поддерживает, без использования триггеров или запросов, что существенно экономит время и трафик.
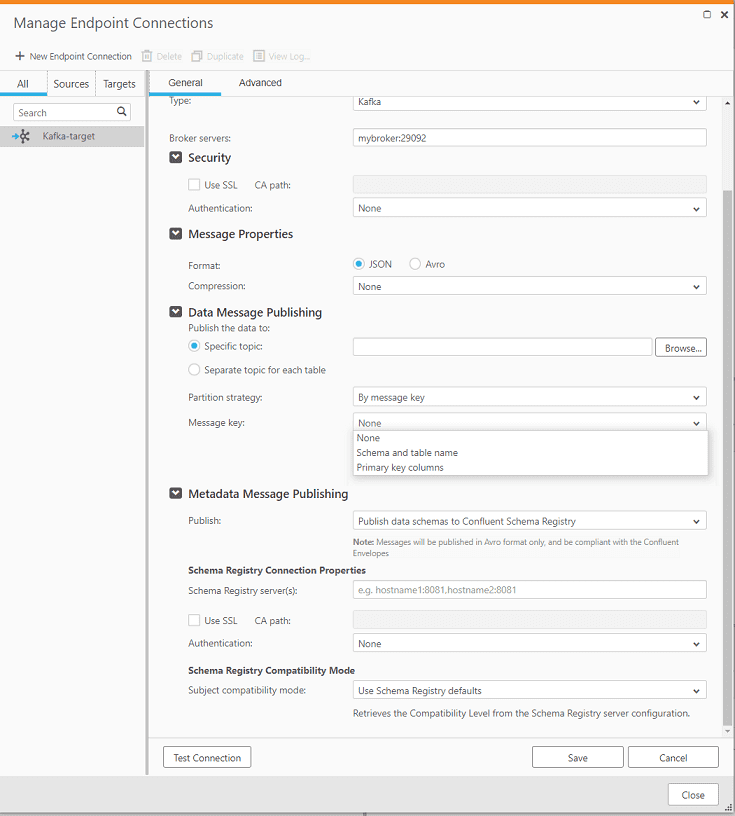
Пользовательский GUI Qlik Replicate для публикации сообщений в Kafka позволяет задать формат сообщения (JSON или AVRO), указать конкретный топик или настроить создание отдельного топика для каждой таблицы. В качестве стратегии разбиения данных по разделам (partitions) топика Kafka Qlik Replicate поддерживает случайный ключ (Random) и ключ сообщения (By message key), который предпочтительнее для работы с транзакционными СУБД в качестве источников данных, т.к. обеспечивает строгий порядок обработки сообщений в случае нескольких разделов. Также можно выбрать принцип на основе на схеме и имени таблицы (Schema and table name) или на столбцах первичного ключа (primary key). В случае больших объемов данных и неравномерной нагрузки на таблицы, некоторые разделы будут обрабатываться немного быстрее других. Использование ключевых столбцов исходной таблицы (вариант primary key) даст лучшее распределение по разделам [1].
Таким образом, благодаря поддержке большого числа внешних источников данных, наглядному интерфейсу и обилию конфигурационных параметров, Qlik Replicate можно назвать удобным ETL-инструментом современного дата-инженера и архитектора Big Data для загрузки данных в топики Apache Kafka и/или корпоративное озеро на базе Hadoop. Завтра мы продолжим разбирать особенности разработки распределенных приложений для аналитики больших данных и рассмотрим тонкости совместного использования Apache Kafka и Spark Streaming. А про особенности оптимизации ETL-конвейеров на базе компонентов Hadoop читайте в этой статье, где мы разбираем кейс компании Panaseer.
Освоить все тонкости администрирования кластеров Apache Hadoop и Kafka, а также разобраться с особенностями разработки приложений потоковой аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для разработчиков
- Hadoop для инженеров данных
- Безопасность озера данных Hadoop
Источники
- https://www.confluent.io/blog/streaming-data-pipelines-and-analytics-with-qlik-and-kafka/
- https://help.qlik.com/ru-RU/
- https://help.qlik.com/en-US/replicate/November2020/Content/Replicate/Main/Introduction/Home.htm

