
Сегодня заглянем под капот Apache Kafka и рассмотрим, как на программном уровне работает упаковка сообщений от приложения-продюсера в пакеты перед их отправкой в топик платформы. Что такое RecordAccumulator, какие конфигурации с ним связаны и почему такое пакетирование обеспечивает эффективность потоковой обработки данных.
Как устроено пакетирование потоковой обработки в Apache Kafka
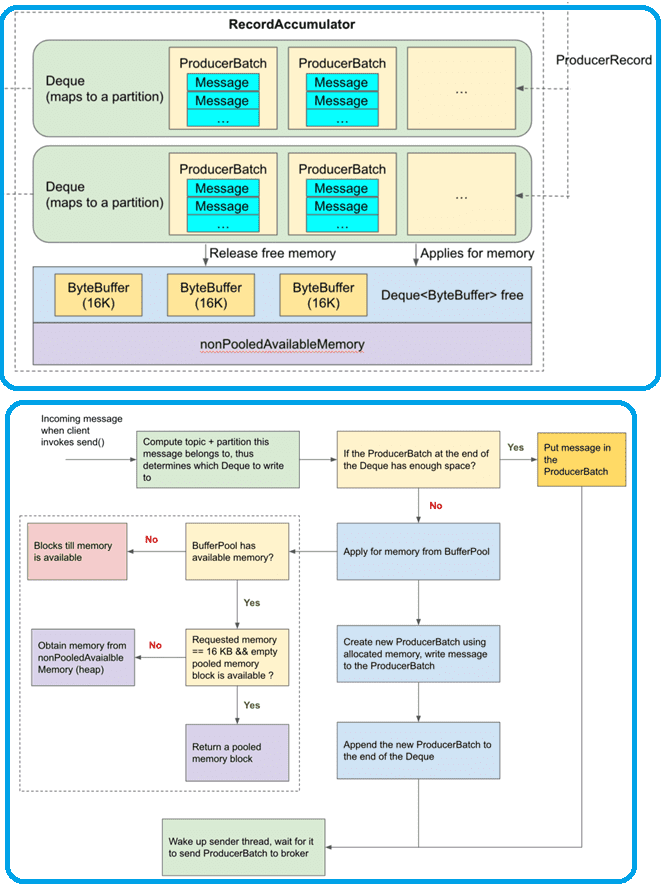
При том, что Apache Kafka является распределенной платформой потоковой обработки событий, сообщения от приложений-продюсеров перед их отправкой в топик группируются в пакеты, чтобы снизить накладные расходы на метаданные, а также повысить эффективность сетевой передачи и операций дискового ввода-вывода. Подробно об этом мы писали здесь и здесь. На программном уровне такое накопление сообщений обеспечивает класс RecordAccumulator, который действует как очередь, накапливающая записи в экземплярах MemoryRecords для отправки на сервер. Он использует ограниченный объем памяти, и вызовы добавления будут блокироваться, когда эта память будет исчерпана, если такое поведение явно не отключено.
Объект класса RecordAccumulator создается исключительно при создании KafkaProducer, который использует следующие свойства конфигурации для создания RecordAccumulator:
- batch.size для размера пакета сообщений;
- linger.ms для lingerMs;
- backoff.ms для retryBackoffMs.
Напомним, продюсер группирует все записи, поступающие между передачами запроса, в один пакет размером batch.size, если сообщения приходят быстрее, чем могут быть отправлены. Уменьшить количество запросов можно, добавив искусственную задержку в конфигурации linger.ms , чтобы вместо немедленной отправки записи продюсер ожидал это время и упаковал несколько сообщений воедино. Параметр linger.ms задает верхнюю границу задержки для пакетной обработки: как только размер сообщений превысит заданный объем пакета batch.size, они будут отправлены немедленно. По умолчанию значение linger.ms равно 0, что означает немедленную передачу сообщений брокерам.
Для создания RecordAccumulator требуются следующие параметры: LogContext, batchSize, CompressionType, lingerMs, retryBackoffMs, deliveryTimeoutMs, а также метрики (название группы метрик, например, producer-metrics, время, версия API, менеджер транзакций и буферный пул памяти.
В структуре данных для RecordAccumulator есть две важные сущности:
- буферный пул памяти (memory buffer pool);
- набор очередей (queue), в которых сообщения хранятся и группируются перед отправкой брокерам.
Эти два объекта постоянно взаимодействуют друг с другом, чтобы динамически обрабатывать пакетную обработку сообщений и выделение памяти. Сообщения, назначенные одному и тому же разделу топика, хранятся в одном и том же сопоставлении разделов (Deque), каждый из которых содержит несколько пакетов ProducerBatch. В свою очередь, каждый пакет ProducerBatch содержит несколько сообщений, которые отправляются брокеру на уровне детализации ProducerBatch. Буферный пул имеет размер по умолчанию 32 МБ, и каждый блок памяти в нем имеет размер по умолчанию 16 КБ.
Администрирование Arenadata Streaming Kafka
Код курса
ADS-KAFKA
Ближайшая дата курса
5 августа, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
На программном уровне алгоритм процесса пакетирования сообщений от приложения-продюсера перед отправкой в топик Kafka можно представить следующим образом:
- определяется Deque, которому принадлежит ProducerBatch сообщения, если он не существует, создается новый;
- после определения Deque следует проверить, достаточно ли места в ProducerBatch в конце Deque. Если места достаточно, то сообщение записывается в ProducerBatch, и на этом весь процесс заканчивается. Если ProducerBatch в конце заполнен или если Deque создается заново, а пространство еще не выделено, необходимо создать новый ProducerBatch.
- Когда Deque не содержит доступного ProducerBatch, следует создать новый ProducerBatch, т. е. память должна быть выделена для нового ProducerBatch. Обычно, когда мы напрямую создаем экземпляр объекта с помощью нового ключевого слова, JVM выделяет память из кучи, и память будет переработана сборщиком мусора позже. Kafka напрямую не полагается на JVM для управления памятью, а имеет BufferPool для оптимизации динамического распределения и повторного использования памяти. Если запрошенный размер памяти совпадает с размером блока по умолчанию в пуле, по умолчанию равному 16 КБ, и есть доступные блоки, ProducerBatch назначается пустой блок. Иначе, если у буфера пула есть не свободная память, доступная в куче, память назначается из кучи. Если в буфере пула нет доступной памяти, запрашивающий поток должен ждать, пока другие потоки не высвободят память обратно в BufferPool. Так использование BufferPool для управления памятью позволяет избежать частого выделения памяти из кучи и сборщика мусора, если они управляются JVM, что повышает производительность производителя.
- Выделенная память привязывается к новому ProducerBatch, и сообщения записываются в новый ProducerBatch;
- новый ProducerBatch помещается в Deque, которому он принадлежит.
Таким образом, Kafka хранит сопоставления между разделом топика и Deque. В реальной рабочей среде это сопоставление должно обрабатывать параллельные операции чтения и записи, поэтому оно должна быть потокобезопасной. Kafka использует CopyOnWriteMap как реализацию ConcurrentMap, чтобы выполнить операцию копирования при записи (COW). Запросы на чтение не нуждаются в блокировках и никогда не блокируются. Каждый запрос на запись создает копию карты, что является дорогостоящей операцией. Однако COW запускается только при создании новой Deque, т. е. когда разделитель определяет сообщение для перехода в новый раздел топика. Поскольку разделы не меняются часто, трафик записи небольшой.
Больше подробностей про администрирование и эксплуатацию Apache Kafka в системах аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники
- https://medium.com/@bb8s/kafka-producer-deep-dive-batching-messages-in-recordaccumulator-aeaf5905fee
- https://jaceklaskowski.gitbooks.io/apache-kafka/content/kafka-producer-internals-RecordAccumulator.html
- http://people.apache.org/~nehanarkhede/kafka-0.9-producer-javadoc/doc/org/apache/kafka/clients/producer/internals/RecordAccumulator.html

