Вчера мы говорили про промышленный Machine Learning в больших данных и рассматривали проблемы микросервисной архитектуры в системах машинного обучения. Продолжая разбирать, как Feature Store повышает эффективность MLOps-процессов, сокращая цикл разработки согласно Agile-идеям, сегодня мы приготовили для вас краткий обзор хранилища признаков StreamSQL. Читайте далее, что такое StreamSQL, как оно устроено, каким образом полезно Data Scientist’у и при чем здесь Big Data технологии потоковой обработки событий: Apache Kafka и Spark Streaming.
Что такое StreamSQL и как это работает в Machine Learning
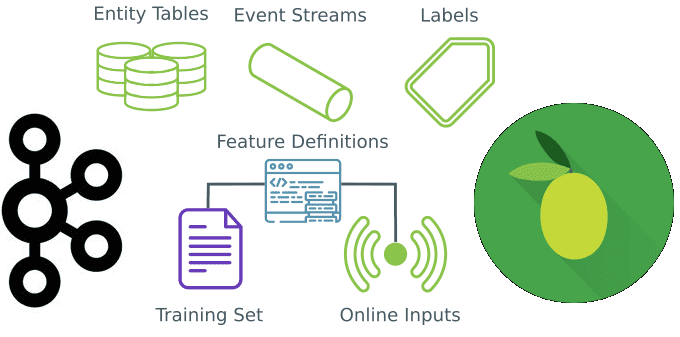
Как мы вчера упоминали, StreamSQL.io – это хранилище признаков (фичей, от анг. feature) для моделей машинного обучения, которое ускоряет разработку ML-систем за счет следующих функциональных возможностей [1]:
- создание фичей с использованием декларативных определений;
- генерация обучающих датасетов с теми же определениями фичей, что и в практическом использовании;
- управление версиями, мониторинг и управление фичами;
- возможность совместного и повторного использования, а также обнаружения фичей в разных командах и ML-моделях.
В общем случае процесс разработки ML-системы с применением StreamSQL.io выглядит так:
- Feature Store подключается к источнику данных или датасет напрямую загружается в хранилище фичей;
- если необходимо, данные можно преобразовать или объединить с помощью типовых SQL-запросов;
- регистрируются определения фичей.
В любой момент можно добавить дополнительные источники данных или преобразования, создать новые или изменить существующие фичи, а также найти и проанализировать их в существующем реестре [1].
Таким образом, StreamSQL.io – это не просто хранилище фичей для ML-модели, а унифицированный конвейер данных для их разработки и ввода в эксплуатацию. Он абстрагирует пакетные и потоковые данные в одном интерфейсе, позволяя добавлять, обновлять и удалять входные фичи через SQL, Tensorflow или пользовательские функции Python. StreamSQL.io работает как в обучающей, так и в production-среде, обеспечивая хранение с отслеживанием состояния для ML-примитивов, таких как embedding-методы, и встроенную интеграцию с Tensorflow [2].
StreamSQL.io повышает уровень абстракции при потоковой обработке событий, чем это возможно с Apache Flink и Spark. Файлы, таблицы и потоки могут быть подключены к StreamSQL.io, а затем преобразованы и объединены с помощью SQL перед превращением в фичи. После подготовки данных к машинному обучению фичи могут быть определены декларативно, и StreamSQL.io будет генерировать их для обучения и практического использования [1].
SQL для потоков Big Data
В общем смысле, вне контекста Machine Learning, StreamSQL представляет собой структурированный язык запросов, который расширяет SQL возможностью обрабатывать потоки данных в реальном времени. В дополнение к SQL для управления отношениями (таблицами) из строк, StreamSQL позволяет манипулировать потоками из бесконечных последовательностей кортежей, которые не все доступны одновременно. Поскольку потоки бесконечны, операции над потоками должны быть монотонными. Запросы к потокам обычно являются «непрерывными», выполняются в течение длительных периодов времени и возвращают инкрементные результаты. В частности, введены следующие операции для управления потоками через SQL-запросы [3]:
- выбор из потока (Selecting from a stream) — стандартный SQL-оператор SELECT может быть применен к потоку для вычисления функций (с использованием целевого списка) или фильтрации нежелательных кортежей (с помощью WHERE). Результатом будет новый поток.
- соединение потока с отношением (Stream-Relation Join) для создания нового потока. Каждый кортеж в потоке соединяется с текущим значением отношения на основе предиката.
- Объединение и слиянием (Union and Merge) двух и более потоков. Union объединяет кортежи в строгом порядке FIFO (First In – First Out). Merge более детерминировано, объединяет потоки в соответствии с ключом сортировки.
- Оконные функции и агрегация (Windowing and Aggregation). Поток может быть оконным для создания конечных наборов кортежей. Например, окно размером 5 минут содержит все кортежи за данный 5-минутный период. Определения окон могут допускать сложный выбор сообщений на основе значений поля кортежа. После создания конечного пакета кортежей можно применять к нему такие аналитические функции, как вычисление количества, среднего или максимального значения и пр.
- Оконное объединение (Windowing and Joining), когда несколько потоков разделены на временные окна, а затем объединены для совместных операций. Кортежи в join-окнах будут объединяться, если они соответствуют предикату.
StreamSQL является производным от академических исследований потоковой обработки событий. Над разработкой основных принципов StreamSQL работала команда из 30 профессоров и студентов проекта Aurora под руководством калифорнийского исследователя Майкла Стоунбрейкера с 2001 по 2003 год. Разумеется, ранее рассмотренное хранилище фичей StreamSQL.io является далеко не единственным вариантом применения языка SQL для потоковой обработки событий. Популярная Big Data платформа потоковой обработки событий Apache Kafka реализует эти принципы в KSQL, аналогичные инструменты предлагают Apache Samza и Storm в виде SamzaSQL и Storm SQL соответственно.
Сам по себе язык StreamSQL обычно используется для систем управления потоком данных об онлайн-событиях, например, в аналитике пользовательского поведения и рыночных данных, сетевом мониторинге, для обнаружения и предотвращения электронного мошенничества, а также прочих аналитических приложений реального времени [3]. Об особенностях оптимизации SQL-запросов в Apache Spark с помощью механизмов Pushdown Pushdown и Projection Pushdown мы поговорим завтра.
Как внедрить Feature Store: потоковая обработка событий и микросервисы
Возвращаясь к промышленным ML-системам, MLOps-практикам и проблемам микросервисной архитектуры, отметим следующие особенности внедрения Feature Store [4]:
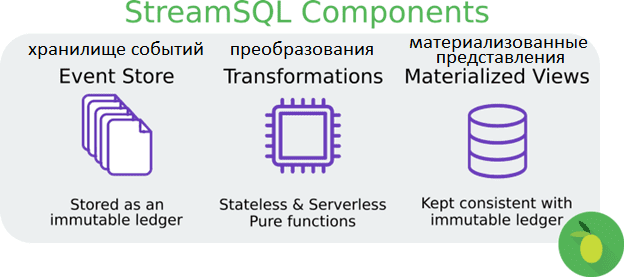
- потоковая обработка событий предполагает, что события домена (логические факты о случившихся действиях) передаются через соответствующую технологию Big Data, например, Apache Kafka или Pulsar. Это позволит Feature Store материализовать свое состояние независимо от микросервисов. Сохранение журнала событий позволяет материализовать фичи в любой момент времени.
- Переход от микросервисной архитектуры ML-системы к потоковой обработке событий потребует организационных и технических обновлений. В частности, понадобится изменить критически важные микросервисы с учетом новых зависимостей или использовать подход захвата изменения данных (Change Data Capture) из каждой СУБД-источника для преобразования обновлений в поток. При этом Feature Store становится уязвимым для ошибок из-за изменения схемы данных внутри микросервисной СУБД.
- Хранилище фичей зависит от схемы потоков событий. Если поток изменяет свою схему данных или микросервис ведет себя некорректно, предоставляя ненужные данные, он может вывести из строя Feature Store. К схемам потоков событий следует относиться так же внимательно, как и к схемам базы данных. Процедуры миграции должны быть четкими и проверенными. Например, рекомендуется расширяемый формат для определения событий, такой как Protobuf или JSON.
- Наконец, стоит помнить об экономической стороне вопроса. Хотя Feature Store, как и прочие MLOps-инструменты, предназначены для снижения стоимости разработки и внедрения ML-моделей в production, создание и поддержка хранилища фичей требуют соответствующих ресурсов. Кроме того, часто хранилище фичей повторяет вычисления, выполняемые отдельными микросервисами. Поэтому внедрение Feature Store предполагает значительную трансформацию существующей MLOps-инфраструктуры и рабочих процессов аналитиков больших данных, Data Scientist’ов и ML-инженеров.
Узнайте больше про потоковую обработку событий и машинное обучение с Apache Kafka и Spark на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Анализ данных с Apache Spark
- Apache Kafka для разработчиков
Источники
- https://docs.streamsql.io/
- https://pypi.org/project/streamsql/1.0.6/
- https://en.wikipedia.org/wiki/StreamSQL
- https://medium.com/analytics-vidhya/why-microservices-suck-for-machine-learning-and-how-a-feature-store-makes-it-better-c34fa0d00b92

