
Мы уже рассказывали, что приложения Kafka Streams используют RocksDB в качестве хранилища состояний. Сегодня рассмотрим, как это key-value NoSQL-СУБД используется для разработки stateful-приложений Apache Flink. Читайте далее о преимуществах и особенностях применения RocksDB для управления состоянием Flink-приложения, а также заблуждениях, связанных с этими фреймворками.
3 бэкенда Apache Flink для хранения состояний stateful-приложений
Как и Apache Spark, фреймворк Flink является компонентом экосистемы Hadoop. Spark и Flink во многом похожи по функциональным возможностям, но различаются в некоторых нюансах. В частности, именно Flink позволяет обрабатывать потоки Big Data в режиме реального времени, тогда как Spark, даже с учетом модуля Structured Streaming, поддерживает концепцию near real-time, когда информация обрабатывается пусть с небольшой, но все-таки некоторой задержкой (latency). Чаще всего потоковые приложения являются stateful: они отслеживают состояние, запоминая информацию из обработанных событий, чтобы на основе этих данных вести дальнейшие вычисления. Подробнее про состояния stateful-приложений Apache Flink читайте в нашей новой статье.
Чтобы предотвратить потерю данных в случае сбоя, серверная часть (backend) состояния периодически сохраняет моментальный снимок своего содержимого в предварительно настроенном долговременном хранилище. В Apache Flink информация о состоянии приложения хранится локально в настроенном backend’е, который может быть представлен следующими вариантами [1]:
- MemoryStateBackend;
- FsStateBackend;
- RocksDBStateBackend.
Подходящий backend состояния для развертывания в производственной среде (production) зависит от требований к масштабируемости, пропускной способности и задержке. К примеру, MemoryStateBackend и FsStateBackend основаны на области памяти, называемой кучей (heap) JVM, где хранится текущее состояние stateful-приложения. Подробнее про области памяти в приложениях Flink читайте в нашей новой статье. Причем MemoryStateBackend рекомендуется для локальных разработок и отладки, а не для использования в production. FsStateBackend работает достаточно быстро, поскольку информация о состоянии приложения хранится непосредственно в JVM и нет необходимости тратить время на процессы сериализации и десериализации данных. Однако, на практике чаще всего для stateful-приложений Apache Flink используется RocksDBStateBackend на основе встраиваемой key-value NoSQL-СУБД RocksDB, о чем мы поговорим далее.
Hadoop для инженеров данных
Код курса
HDDE
Ближайшая дата курса
17 июня, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Как Apache Flink хранит состояния в RocksDB
Прежде чем погружаться в особенности использования RocksDB для хранения данных о stateful-приложениях Apache Flink, разберем виды состояний в этом фреймворке [1]:
- рабочее состояние (in-flight), над которым работает задание Flink. Оно всегда хранится локально в памяти (с возможностью переноса на диск) и может быть утеряно при сбое задания, не влияя на возможность восстановления задания;
- моментальные снимки (snapshot) состояния – контрольные точки и точки сохранения, которые хранятся в удаленном долговременном хранилище и используются для восстановления локального состояния при сбое задания. Чем checkpoint отличается от savepoint, читайте в нашей новой статье.
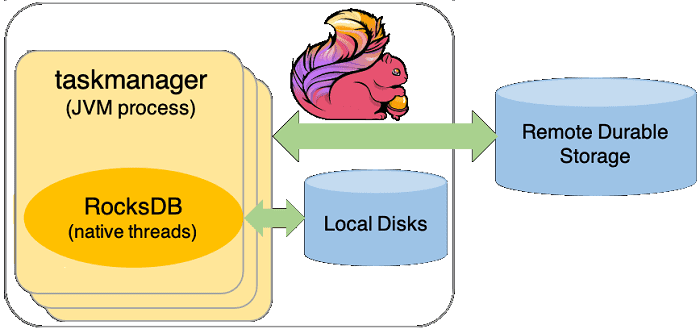
Вопреки распространенному заблуждению, RocksDB – это не просто распределенная NoSQL-СУБД, которая должна работать в кластере и управляться администраторами. RocksDB — это встраиваемое постоянное key-value хранилище, ориентированное на работу с быстрой памятью (SSD-диски), о чем мы писали здесь. RocksDB взаимодействует с Flink через собственный интерфейс Java (JNI, Java Native Interface). Все, что нужно для использования RocksDB в качестве backend’а состояния, уже включено в дистрибутив Apache Flink, в т.ч. собственная общая библиотека. А во время выполнения Flink-задания RocksDB встраивается в процессы TaskManager и работает в собственных потоках с локальными файлами [1].
С помощью RocksDBStateBackend рабочее состояние сначала записывается во внутреннюю память вне кучи, а затем сохраняется на локальные диски при достижении настроенного порогового значения. Таким образом RocksDBStateBackend может поддерживать состояние, превышающее общую настроенную емкость кучи, и ограничен только объемом дискового пространства, доступного во всем кластере. А поскольку RocksDBStateBackend не использует кучу JVM для хранения рабочего состояния, этот backend не зависит от сборки мусора и имеет предсказуемую задержку.
Рабочее состояние в RocksDBStateBackend передается файлам на диске, которые находятся в каталоге, указанном в конфигурации фреймворка state.backend.rocksdb.localdir. Поскольку производительность диска напрямую влияет на производительность RocksDB, рекомендуется располагать этот каталог на локальном диске. Не следует настраивать его для удаленного сетевого расположения в NFS или Hadoop HDFS, поскольку запись на удаленные диски обычно выполняется медленнее. При этом для рабочего состояния не обязательна высокая доступность, а для повышения пропускной способности и скорости работы предпочтительнее использовать локальные SSD-диски.
Кроме полных автономных снимков состояния, RocksDBStateBackend также поддерживает добавочные контрольные точки (checkpoints) в качестве параметра настройки производительности. Инкрементная контрольная точка хранит только изменения с момента последнего завершенного checkpoint’а, что значительно сокращает время реализации этого механизма обеспечения надежности по сравнению с выполнением полного snapshot’а. Примечательно, что сегодня среди всех бэкэндов только RocksDBStateBackend поддерживает добавочные контрольные точки.
Моментальные снимки состояния сохраняются в удаленном надежном хранилище. Во время создания моментального снимка состояния TaskManager делает snapshot текущего состояния и самостоятельно сохраняет его без участия backend’а в любом удаленном хранилище, заданном в state.checkpoints.dir: локальном кластере HDFS или облачном хранилище объектов (Amazon S3, Azure Blob Storage, Google Cloud Storage и пр.) [1]. Подробнее об оптимизации использования RocksDB читайте в нашей новой статье.
Когда использовать RocksDBStateBackend и как
Таким образом, RocksDB – отличный вариант для хранения состояний Flink-приложений в следующих случаях [1]:
- состояние задания больше, чем может доступный объем локальной памяти, например, большой размер окна или самого состояния;
- инкрементные (дополнительные) контрольные точки используются как способ сократить время установки checkpoint’ов;
- характер временной задержки предсказуем и на нее не влияет сборка мусора JVM.
И наоборот, для приложений с небольшим состоянием или строгими требованиями к минимальной временной задержке рекомендуется использовать FsStateBackend в качестве хранилища состояний. RocksDBStateBackend в несколько раз медленнее, чем FsStateBackend, т.к. хранит пары ключ/значение в виде сериализованных байтов и любой доступ к состоянию (чтение или запись) проходит через цикл сериализации и десериализации на границе JNI. На это уходит дополнительное время, создавая накладные расходы. Однако, RocksDBStateBackend для того же количества состояний нужен меньший объем памяти по сравнению с соответствующим представлением в куче.
Поскольку RocksDB полностью встроен в процесс TaskManager и полностью управляется им, то RocksDBStateBackend можно настроить на уровне кластера по умолчанию для всего кластера Apache Flink или на уровне задания для отдельных заданий. Конфигурация уровня задания имеет приоритет над конфигурацией уровня кластера. Сама настройка выполняется таким образом [1]:
- на уровне кластера следует добавить в conf / flink-conf.yaml следующую конфигурацию:
state.backend: rocksdb
state.backend.incremental: true
state.checkpoints.dir: hdfs:///flink-checkpoints # location to store checkpoints
- на уровне Flink-задания после создания StreamExecutionEnvironment нужно добавить в его код инструкцию setStateBackend(new RocksDBStateBackend(«hdfs:///fink-checkpoints», true)).
Таким образом, на практике RocksDB является удобной в применении частью stateful-приложений Apache Flink, которая позволяет заданию иметь состояние, превышающее объем доступной памяти, записывая его на локальный диск. Тем не менее, с этим backend’ом связаны некоторые проблемы и ограничения Flink-приложений [2], о которых мы поговорим в следующий раз. А о том, как использовать HBase в качестве хранилища состояний для Flink-приложений, читайте здесь.
Также читайте в нашей новой статье, зачем коммерческое облачное решение Ververica заменяет традиционный бэкенд состояний для stateful-приложений Flink на GeminiStateBackend, и как это повышает производительность потоковых вычислений.
Освойте тонкости настройки и использования Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

