
Специально для обучения начинающих аналитиков данных и дата-инженеров сегодня рассмотрим примеры выполнения простых SQL-запросов и оконных функций в Apache Spark на Google Colab. Как быстро проанализировать датафрейм из CSV-файлов с помощью нескольких строк на PySpark.
Запуск и использование PySpark в Google Colab
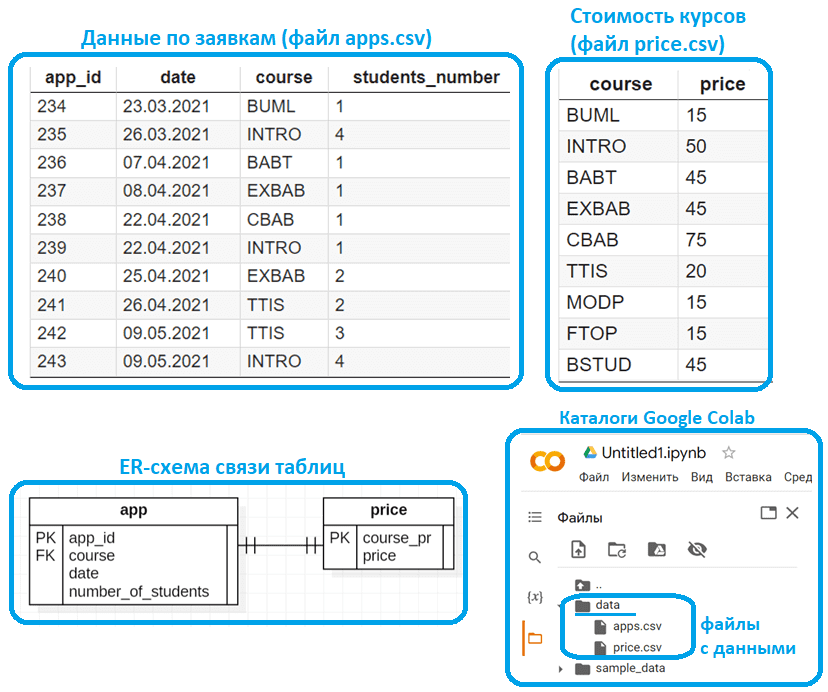
Предположим, необходимо определить потенциальный доход от проведения обучающих курсов по технологиям Big Data. Обезличенные заявки на обучение выгружены из CRM-системы в виде CSV-файла под названием apps.csv. Сведения о стоимости курсов хранятся в отдельном CSV-файле под названием price.csv. Если представить структуру данных каждого файла в виде сущности, можно составить ER-диаграмму, которая показывает связь 1-к-1 между сущностью Заявка (app) и Стоимость (price) по ключу кода курса (course в таблице app и course_pr в таблице price). Загрузим эти CSV-файлы в интерактивную среду анализа и визуализации данных Google Colab, разместив их в папке data.
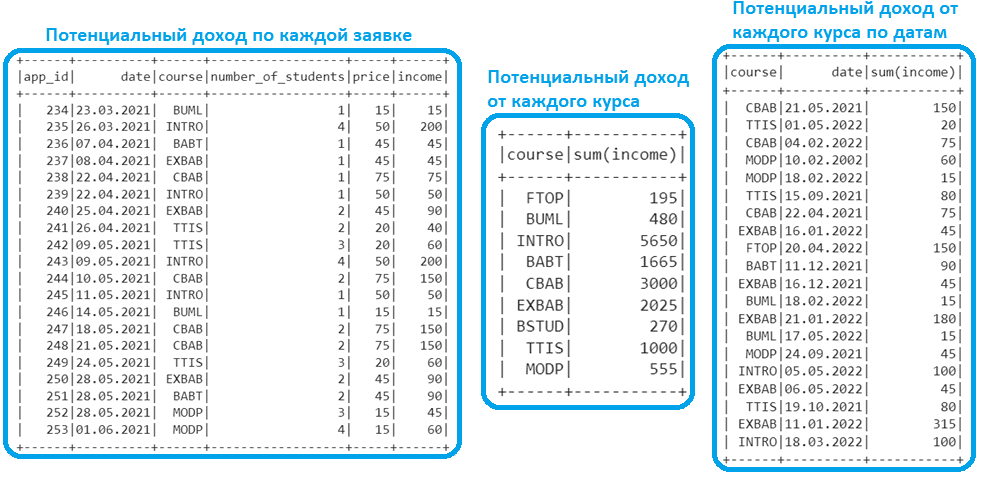
Вычислить потенциальный доход по каждой заявке в Google Colab позволит следующий код на PySpark, который соединяет датафрейм заявок (df1) с датафреймом цен (df2), добавляя в df1 соответствующий столбец (income) и удаляет ненужный столбец c повтором стоимости курса (course_pr’). Также в коде выполнено преобразование поля date из строкового типа в дату.
!pip install pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("SpApp").config('spark.ui.port', '4050').getOrCreate()
from pyspark.sql.types import *
schema1 = StructType([
StructField("date", StringType(), True),
StructField("course", StringType(), True),
StructField("number_of_students", ShortType(), True)])
df1 = spark.read.format("csv").schema(schema1).option("header", True).load("data/apps.csv")
from pyspark.sql.functions import unix_timestamp, from_unixtime
df1.withColumn("date", from_unixtime(unix_timestamp("date", "dd/MM/yyy")).alias("date"))
schema2 = StructType([
StructField("course_pr", StringType(), True),
StructField("price", ShortType(), True)])
df2 = spark.read.format("csv").schema(schema2).option("header", True).load("data/price.csv")
df1=df1.join(df2,df1.course==df2.course_pr,"inner")
from pyspark.sql.functions import lit
df1=df1.drop('course_pr')
df1=df1.withColumn("income", df1.number_of_students*(df1.price))
Поскольку в данном примере используются функции PySpark, сперва выполняется его установка и импорт нужных классов из SQL-модуля. Также создан объект сеанса SparkSession, который является точкой входа в Spark-приложение под названием SpApp. Подробно об этом мы писали здесь.
Оценить потенциальный доход от каждого курса поможет простой запрос с группировкой датафрейма df1 по этому полю: df1.groupBy(‘course’).sum(‘income’).show().
Если необходимо привязаться к дате подачи заявки, т.к. в одни день может быть подано несколько заявок по одному и тому же курсу, группировка будет не только по названию курса, но и по дате:
df1.groupBy(‘course’, ‘date’).sum(‘income’).show().
Оконные функции для анализа данных в Apache Spark вместо SQL-запросов
Оконные функции PySpark выполняют вычисления для набора строк, которые связаны друг с другом. Но, в отличие от агрегатных функций, таких как вычисление среднего значения или суммы сгруппированных строк, что мы рассмотрели выше, оконные функции не сворачивают результат строк в одно значение. Вместо этого все строки сохраняют свою исходную идентичность, и вычисленный результат возвращается для каждой строки.
В нашем примере сравним потенциальный доход каждой заявки с максимальным возможным по конкретному курсу. Разумеется, чем больше число студентов в заявке, тем выше потенциальный доход от ее реализации. Чтобы выполнить операцию над группой заявок по каждому курсу, следует сперва разбить данные с помощью PySpark-функции Window.partitionBy(), указав в параметрах этого метода соответствующее поле – course. А номер строки и ее ранг в разделе можно получить через упорядочивание с помощью предложения orderBy(), в параметрах которого определим поле доход (income).
Однако, в практическом смысле нам интересен не столько номер строки в разделе окна, сколько накопительное или кумулятивное распределение потенциального дохода в сравнении от максимального. Определить это поможет оконная функция cume_dist(), по смыслу аналогичная функции DENSE_RANK в SQL.
from pyspark.sql.window import Window
windowSpec = Window.partitionBy("course").orderBy("income")
from pyspark.sql.functions import cume_dist
df1.withColumn("cume_dist",cume_dist().over(windowSpec)) \
.show()
Чтобы получить сводную статистику с минимальным, максимальным и средним значением, а также общей суммой по каждому курсу, который является ключом раздела, используем оконные PySpark-функции Aggregate и WindowSpec. При этом уже не нужно использовать предложение order by().
from pyspark.sql.functions import row_number
windowSpecAgg = Window.partitionBy("course")
from pyspark.sql.functions import col,avg,sum,min,max,row_number
df1.withColumn("row",row_number().over(windowSpec)) \
.withColumn("avg", avg(col("income")).over(windowSpecAgg)) \
.withColumn("sum", sum(col("income")).over(windowSpecAgg)) \
.withColumn("min", min(col("income")).over(windowSpecAgg)) \
.withColumn("max", max(col("income")).over(windowSpecAgg)) \
.where(col("row")==1).select("course","avg","sum","min","max") \
.show()

Больше практических деталей по применению Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

