
В этой статье для дата-инженеров рассмотрим пример конвейера анализа потокового видео с Youtube-каналов на Kafka, Spark Streaming и Elasticsearch c Kibana, связанных через процессоры Apache NiFi.
Постановка задачи: ETL-конвейер анализа потоковых данных с Youtube
Потоковые данные непрерывно генерируются тысячами источников, которые отправляют записи одновременно и в небольших размерах (порядка килобайт). Чаще всего такими данными являются лог-файлы от клиентов мобильных или веб-приложений, покупки в электронной торговле, события пользовательского поведения на сайтах, действия онлайн-игроков, информация из соцсетей, финансовых торговых площадок или геопространственных сервисов, а также телеметрия с IoT-устройств или оборудования в дата-центрах. Чтобы проанализировать эти данные, можно составить конвейер потокового маршрутизатора Apache NiFi из следующих шагов:
- генерация потоковых данных;
- анализ потоковых данных с помощью Spark Streaming;
- запись проанализированных данных в топики Apache Kafka;
- визуализация результатов анализа на наглядном дэшборде Kibana в реальном времени.
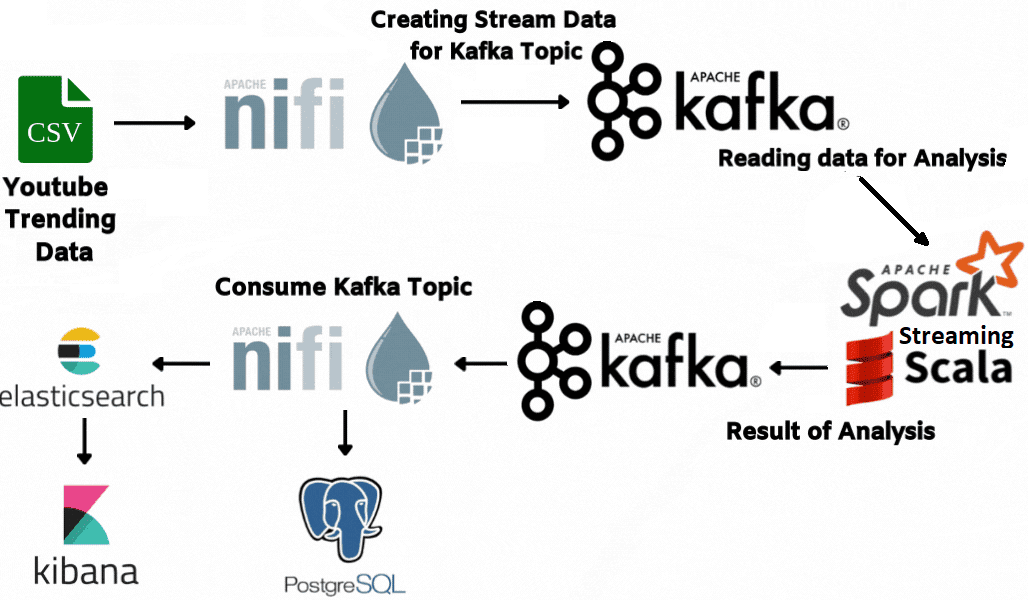
Для примера возьмем в качестве источника исходных данных о CSV-файл с трендами видеохостинга Youtube. Конвейер генерации потоковых данных из этого файла можно представить последовательностью нескольких обработчиков-процессоров Apache NiFi.

Сперва воспользуемся NiFi-процессором под названием GetFile. Он получает файлы из локальной файловой системы и создает потоковый файл (FlowFile), который далее будет обрабатываться другими процессорами. При этом NiFi будет игнорировать файлы, для которых отсутствуют права хотя бы на чтение.
Далее преобразуем каждую запись из этого CSV-файла в JSON и создадим топик Kafka. Для этого воспользуемся процессором ConvertRecord. Он преобразует записи из одного формата данных в другой с помощью настроенных сервисов чтения (Reader) и записи (Writer) данных. Reader и Writer должны быть настроены так, чтобы схемы данных имели одинаковые имена полей. Типы полей не обязательно должны быть одинаковыми, если значение поля можно преобразовать из одного типа в другой. Например, если во входной схеме данных есть поле «баланс» типа double, то в выходной схеме оно может быть типа string, double или float. Если во входных данных есть какое-либо поле, которого нет в выходных данных, это поле будет исключено в выходе. Если какое-либо поле указано в выходной схеме, но отсутствует во входных данных или их схеме, то это поле не появится в выходных данных или будет иметь нулевое значение, в зависимости от модуля записи.
После преобразования данных в JSON разделим каждую на запись перед публикацией в топики Kafka, чтобы отправлять в них фрагментированные небольшие записи вместо одного большого сообщения. Для этого воспользуемся NiFi-процессором SplitJson, который разбивает JSON-файл на несколько отдельных потоковых файлов для элемента массива, заданного выражением JsonPath. Каждый сгенерированный FlowFile состоит из элемента указанного массива и передается в отношение «разделение» (relationship ‘split’), а исходный файл передается в исходное отношение (‘original’ relationship). Если указанный JsonPath не найден или не оценивается как элемент массива, исходный файл перенаправляется на «сбой», и потоковые файлы не создаются.
Наконец, опубликуем каждую из записей JSON в топике Kafka с помощью процессора PublishKafka_2_0. Он отправляет содержимое FlowFile в виде сообщения в Apache Kafka с помощью Kafka 2.0 Producer API. Отправляемые сообщения могут быть отдельными FlowFile или могут быть разделены с помощью заданного пользователем разделителя, например новой строки. Содержимое FlowFile становится содержимым сообщения Kafka, которому дополнительно назначается ключ с помощью свойства <Kafka Key>.
Процессор позволяет пользователю настроить необязательный демаркатор сообщений, который можно использовать для отправки множества сообщений в потоковый файл. Например, с помощью разделителя \n можно указать, что содержимое FlowFile должно использоваться для отправки одного сообщения на строку текста. Он также поддерживает многосимвольные разделители. Если свойство разделителя не установлено, все содержимое FlowFile будет отправлено как одно сообщение. При использовании разделителя, если некоторые сообщения успешно отправлены, а другие – нет, результирующий FlowFile будет считаться неудачным и помечен соответствующими атрибутами. Одним из таких атрибутов является failed.last.idx, указывающий индекс последнего сообщения, которое было успешно подтверждено Kafka. Если разделитель не используется, значение этого индекса равно -1. Это позволит процессору PublishKafka повторно отправлять неподтвержденные сообщения только при следующей повторной попытке. Также этот процессор NiFi имеет свойство Security Protocol, чтобы пользователь мог указать протокол для связи с брокером Kafka.
Далее можно анализировать потоковые данные, считывая из из топика Kafka в реальном времени с помощью приложения, поддерживающего Streaming-обработку. Как это сделать с помощью Spark Streaming, мы рассмотрим далее.
Анализ потоковых данных с помощью Spark Streaming
Когда подходящая среда для обработки потоковых данных в виде топика Kafka готова, можно приступить к их анализу в режиме реального времени. Цель анализа в нашем примере с Youtube-каналами – это ответить на следующие вопросы:
- какие самые просматриваемые каналы?
- какие категории больше всего нравятся?
- какие самые просматриваемые категории?
- какие самые больше всего нравятся?
В нашем примере Spark Scala для анализа данных. После запуска сеанса Spark следует подключиться к топику Kafka, где находятся потоковые данные.
// to start spark streaming
./spark-shell --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.1 ...
// Connecting Kafka
val UsYoutubeDf = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "usyoutube").load
Далее следует определить соответствующую схему данных:
// import StructType for Schema such as StringType, IntegerType, BooleanType
import org.apache.spark.sql.types._
// Defining Schema
val activationSchema = StructType(List( StructField("video_id", StringType, true),
StructField("title", StringType, true),
StructField("published_at", StringType, true),
StructField("channel_id", StringType, true),
StructField("channel_title", StringType, true),
StructField("category_id", IntegerType, true),
StructField("trending_date", StringType, true),
StructField("view_count", IntegerType, true),
StructField("likes", IntegerType, true),
StructField("dislikes", IntegerType, true),
StructField("comment_count", IntegerType, true),
StructField("comments_disabled", BooleanType, true),
StructField("ratings_disabled", BooleanType, true),
StructField("category_title", StringType, true)))
// JSON to df
val youTubeSchemaDf = UsYoutubeDf
.select(from_json($"value".cast("string"), activationSchema)
.alias("usYoutube"))
.select("usYoutube.*")
youTubeSchemaDf.printSchema
/*
root
|-- video_id: string (nullable = true)
|-- title: string (nullable = true)
|-- published_at: string (nullable = true)
|-- channel_id: string (nullable = true)
|-- channel_title: string (nullable = true)
|-- category_id: integer (nullable = true)
|-- trending_date: string (nullable = true)
|-- view_count: integer (nullable = true)
|-- likes: integer (nullable = true)
|-- dislikes: integer (nullable = true)
|-- comment_count: integer (nullable = true)
|-- comments_disabled: boolean (nullable = true)
|-- ratings_disabled: boolean (nullable = true)
|-- category_title: string (nullable = true)
*/
Если нужно ответить на 4 вышепоставленных вопроса, то следует публиковать результаты в 4 разных топиках Kafka:
- Каналы с наибольшим числом просмотров;
- Каналы с наибольшим числом лайков;
- Категории каналов с наибольшим числом просмотров;
- Категории каналов с наибольшим числом лайков.
К примеру, следующий код на Spark Scala позволит выявить каналы с наибольшим числом просмотров:
//mostviewedchannel
val mostviewedchannelDf = youTubeSchemaDf
.groupBy("trending_date","channel_title")
.agg(sum("view_count").as("total_view_count_by_channel"))
.sort($"total_view_count_by_channel".desc)
import org.apache.spark.sql.streaming.Trigger.ProcessingTime
val mostviewedchannelDfQuery = mostviewedchannelDf
.selectExpr("CAST(trending_date as STRING)","CAST(channel_title AS STRING)", "CAST(total_view_count_by_channel AS INTEGER)", "to_json(struct(*)) AS value")
.writeStream.format("kafka")
.option("checkpointLocation", "/home/tugrulgkccc/consumermostviewedchannel")
.option("failOnDataLoss", "false")
.outputMode("complete")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("topic", "mostviewedchannel").start()
Запись проанализированных данных после анализа с процессорами NiFi
Чтобы сделаем результаты анализа данных, получаемые с помощью потоковой передачи Spark, постоянными, запишем их в Elasticsearch и PostgreSQL. Для этого воспользуемся готовыми процессорами Apache NiFi:
- PutElasticsearchHttp – записывает содержимое FlowFile в Elasticsearch, используя указанные параметры, такие как индекс для вставки и тип документа;
- PutSQL – выполняет SQL-команду UPDATE или INSERT над содержимым входящего FlowFile в формате UTF-8. SQL-команда может использовать знак вопроса (?) для экранирования параметров. В этом случае используемые параметры должны существовать как атрибуты FlowFile с соглашением об именах sql.args.N.type и sql.args.N.value, где N — положительное целое число. Ожидается, что sql.args.N.type будет числом, указывающим тип JDBC. Система типов JDBC по образцу типов SQL-92 и SQL-99 обеспечивает преобразование между типами данных SQL Server и типами и объектами языка Java. Драйвер JDBC соответствует спецификации JDBC и предназначен для обеспечения баланса между предсказуемостью и гибкостью. Драйвер JDBC преобразует тип данных Java в соответствующий тип JDBC перед отправкой в базу данных. Он использует сопоставление по умолчанию для большинства типов данных. Например, int Java преобразуется в INTEGER SQL. Сопоставления по умолчанию были созданы для обеспечения согласованности между драйверами.
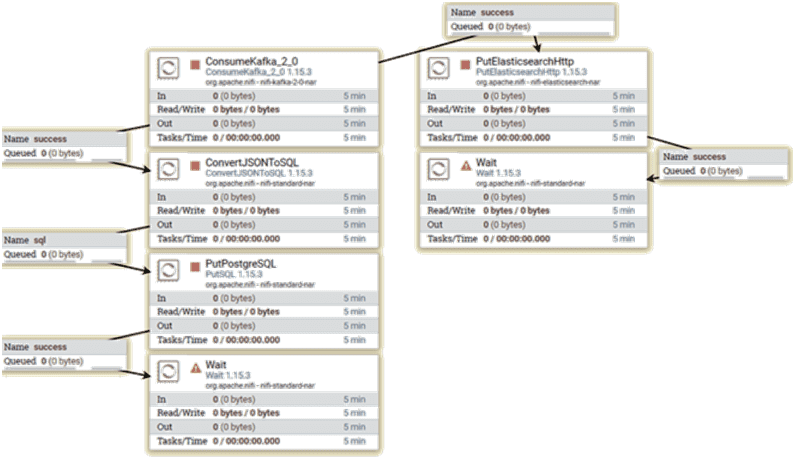
Визуализировать результаты анализа данных в реальном времени можно с помощью инструмента дэшбордов Kibana с бесшовной интеграцией с Elasticsearch в рамках ELK-стека, о чем мы писали здесь.
Больше практических приемов по администрированию и эксплуатации Apache NiFi с Hive для построения эффективных ETL-конвейеров с целью аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/i%CC%87stanbuldatascienceacademy/analyzing-youtube-stream-trend-data-with-spark-streaming-end-to-end-2453ed6d2084
- https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.5.0/org.apache.nifi.processors.standard.ConvertRecord/index.html
- https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.16.0/org.apache.nifi.processors.standard.SplitJson/index.html
- https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.6.0/org.apache.nifi.processors.standard.PutSQL/
- https://www.tutorialspoint.com/jdbc/jdbc-data-types.htm

